Analyse de bases de données en langage naturel avec Amazon Nova
Sources: https://aws.amazon.com/blogs/machine-learning/natural-language-based-database-analytics-with-amazon-nova, https://aws.amazon.com/blogs/machine-learning/natural-language-based-database-analytics-with-amazon-nova/, AWS ML Blog
TL;DR
- L’analyse de bases de données en langage naturel est rendue possible grâce à la famille de modèles fondation Amazon Nova (Nova Pro, Nova Lite, Nova Micro) et au pattern ReAct via LangGraph, permettant des interactions conversationnelles avec des systèmes de bases de données complexes.
- La solution repose sur trois composants: interface utilisateur (UI), IA générative et données, avec un agent qui coordonne questions, raisonnement, orchestration des flux et réponses en langage naturel, tout en offrant autoréparation et HITL.
- Elle propose l’auto-correction et des flux HITL pour valider et affiner les requêtes SQL, afin que les résultats correspondent à l’intention de l’utilisateur et aux exigences du schéma.
- Les évaluations sur le dataset Spider (text-to-SQL) montrent des performances compétitives et une faible latence dans des tâches cross-domaines, avec des atouts sur les requêtes les plus complexes. Pour les déploiements en production, des considérations de sécurité pour Streamlit sont signalisées.
- La collaboration avec GenAIIC donne accès à des experts pour identifier des cas d’usage pertinents et adapter des solutions d’IA générative, avec une architecture basée sur Amazon Bedrock pour permettre du NL->SQL et des visualisations de données.
Contexte et enjeux
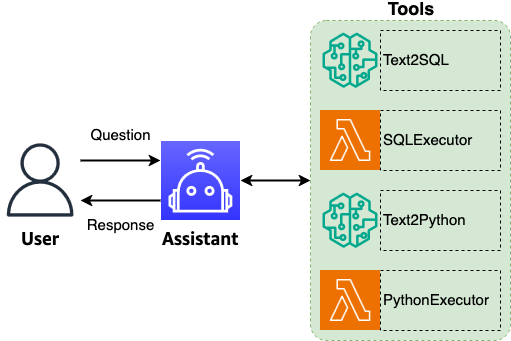
Les interfaces en langage naturel vers les bases de données ont longtemps été un objectif en gestion de données. L’approche présentée utilise des Agents basés sur des LLM pour décomposer des requêtes complexes en étapes de raisonnement explicites et permettre une auto-correction via des boucles de validation. En détectant les erreurs, en analysant les échecs et en affinant les requêtes, le système s’efforce d’aligner l’intention de l’utilisateur et les exigences du schéma avec précision et fiabilité. Cela permet des interactions intuitives, sous forme de conversation, avec des systèmes de bases de données sophistiqués tout en préservant l’exactitude analytique. Pour obtenir des performances optimales avec des compromis minimes, la solution s’appuie sur la famille Nova, des modèles fondationnels qui intègrent d’immenses connaissances et permettent un raisonnement nuancé et une compréhension contextuelle essentielles pour des analyses de données complexes. Le pattern ReAct (raisonnement et action) est mis en œuvre via l’architecture flexible de LangGraph, combinant les forces des LLM Nova pour la compréhension du langage naturel avec des étapes de raisonnement explicites et des actions. Le résultat est une approche moderne d’analyse de bases de données en langage naturel qui facilite l’analyse automatisée et les requêtes textuelles vers SQL. De nombreux clients en transformation IA réalisent que leurs vastes dépôts de données recèlent un potentiel inexploité pour l’analyse automatisée. Cette prise de conscience les pousse à explorer des solutions SQL, allant de simples clauses SELECT à des requêtes multipages impliquant des agrégations et des fonctions sophistiquées. Le défi clé est de traduire l’intention d’un utilisateur — exprimée ou implicite — en requêtes SQL performantes, précises et valides, qui permettent d’obtenir le bon ensemble de données pour une visualisation et une exploration ultérieures. Notre solution se distingue par sa capacité à générer des requêtes riches en contexte et métadonnées, permettant d’obtenir des ensembles de données précis et d’effectuer des analyses complexes. Une interface conviviale est essentielle et nous avons développé une interface intuitive guidant l’utilisateur tout au long de son parcours d’analyse avec des capacités de HITL, permettant des entrées, des approbations et des modifications à des points de décision clés. L’objectif est une analyse cohérente et continue, pas seulement une requête unique.
Ce qui est nouveau
L’architecture décrit ici présente trois composants centraux: UI, IA générative et données, avec un agent central qui coordonne les questions, le routage et les sorties. L’agent accomplit la compréhension des questions, la prise de décision, l’orchestration des flux, le routage intelligent et la génération de réponses complètes en langage naturel. Il améliore la qualité du texte, standardise la terminologie et maintient le contexte conversationnel pour permettre une suite de requêtes liées et une intention analytique précise. Des capacités clés incluent le routage intelligent pour invoquer les bons outils pour chaque question, permettant un traitement de bout en bout des requêtes. Le flux peut aussi traiter des données tabulaires et visuelles et utiliser le contexte complet pour générer des synthèses explicatives et des insights. Un avantage notable est la capacité de l’agent à proposer des questions de suivi pour approfondir l’exploration et révéler des insights inattendus. L’agent conserve le contexte entre les conversations et peut reconstruire des questions abrégées à partir du contexte existant pour confirmation, tout en suggérant des questions complémentaires après chaque échange. La standardisation terminologique assure la cohérence avec les normes industrielles, les directives client et les exigences de marque, en développant les abréviations en termes complets. La solution inclut aussi l’auto-réparation: en cas d’erreur d’exécution, l’agent utilise l’erreur et le contexte pour régénérer une requête SQL corrigée, renforçant la robustesse du traitement des requêtes. La sortie de l’agent comprend un résumé en langage naturel, des résultats tabulaires avec raisonnement, des visualisations avec explications et un résumé concis des insights. Une démonstration Streamlit est utilisée à des fins illustratives; les déploiements en production nécessitent des configurations de sécurité adaptées. Le GenAIIC fournit un accès à des experts pour identifier des cas d’usage précieux et déployer des solutions d’IA générative adaptées à des besoins spécifiques. L’architecture repose sur Amazon Bedrock, permettant de transformer des requêtes en langage naturel en SQL et de générer des visualisations pertinentes. Pour plus d’informations, reportez-vous à Amazon Nova Foundation Models et Amazon Bedrock. Si vous souhaitez collaborer avec GenAIIC, vous pouvez obtenir plus d’informations via les canaux AWS Generative AI Innovation Center.
Détails techniques ou Mise en œuvre
Architecture et composants centraux
La solution se déploie autour de trois composants: UI, IA générative et données. Un agent central coordonne les questions, le routage et les sorties, avec une compréhension des questions, une prise de décision et une orchestration des flux. L’agent améliore la qualité du texte et standardise la terminologie tout en maintenant le contexte pour permettre une chaîne de requêtes liées avec une intention analytique précise. Le routage intelligent assure l’invocation des outils appropriés pour chaque question et le traitement end-to-end. Le flux couvre aussi le traitement des données tabulaires et visuelles et utilise le contexte pour générer des résumés et des insights.
Agent et capacités d’auto-correction
La capacité clé est l’auto-correction: en cas d’erreur d’exécution, l’agent s’appuie sur l’erreur et le contexte pour régénérer une requête SQL corrigée, renforçant la robustesse du traitement des requêtes. L’agent traite les entrées (question réécrite, résultats d’analyse et contexte) pour produire un résumé en langage naturel et une réponse incluant des résultats tabulaires avec raisonnement, des explications de visualisations et un résumé des insights. Il conserve le contexte entre les échanges et propose des questions de suivi après chaque interaction.
Traitement des données, visualisation et standardisation du langage
La solution prend en charge les données tabulaires et visuelles et produit des sorties qui expliquent les résultats et mettent en évidence des insights. La terminologie est standardisée selon les normes industrielles et les directives clients, et les abréviations sont développées en formes complètes pour plus de clarté.
Évaluation et considérations de production
L’évaluation s’est appuyée sur le Spider dataset (text-to-SQL), un benchmark largement utilisé pour des tâches de parsing sémantique cross-domain. Spider comprend 10 181 questions et 5 693 requêtes SQL uniques sur 200 bases de données couvrant 138 domaines. L’évaluation a été réalisée en configuration zero-shot (aucun réglage fin) pour mesurer la généralisation. Les métriques montrent des performances compétitives et une faible latence, en particulier pour les requêtes complexes. Cette évaluation permet de comparer Amazon Nova à des approches de pointe et démontre le potentiel d’un accès en langage naturel aux données à grande échelle.
Démo et considérations de production
L’interface Streamlit est utilisée à des fins illustratives dans la démonstration. Pour les déploiements en production, les configurations de sécurité et l’architecture doivent être examinées pour s’assurer de l’alignement avec les exigences de sécurité de l’organisation. Le GenAIIC offre un accès à des experts pour aider à identifier des cas d’usage et à adapter des solutions d’IA générative.
Pré-requis et étapes de déploiement (vue d’ensemble)
- Utilisez des notebooks SageMaker pour expérimenter la solution.
- Téléchargez et préparez la base de données utilisée pour les requêtes.
- Lancez l’application Streamlit avec la commande: streamlit run app.py. La démo illustre l’interface et le flux; en production, considérez la sécurité et l’évolutivité.
Tableau des faits clés
| Composant | Description |
|---|---|
| Modèles centraux | Amazon Nova Pro, Nova Lite, Nova Micro |
| Modèle | ReAct (raisonnement et action) via LangGraph |
| Plateforme | Amazon Bedrock |
| Ensemble d’évaluation | Spider Text-to-SQL (zero-shot) |
| Domains de données | 138 dans 200 bases de données |
Pourquoi cela compte (impact pour les développeurs/entreprises)
- Permet des requêtes naturelles bout en bout sur des données structurées avec génération SQL précise, réduisant l’obstacle à l’accès aux données pour les analystes et décideurs.
- Utilise des étapes de raisonnement explicites et des actions pour accroître la transparence et la traçabilité du processus analytique.
- Prend en charge l’auto-correction et le HITL pour une meilleure robustesse et fiabilité en production.
- Propose une approche scalable pour la traduction cross-domain avec une faible latence, même pour les requêtes complexes.
- Offre un accompagnement d’experts via GenAIIC pour identifier des cas d’usage et adapter les solutions à des besoins spécifiques.
Points clés
- Amazon Nova, guidé par le pattern ReAct et LangGraph, permet la traduction NL vers SQL avec raisonnement explicite.
- Un agent central coordonne les questions, le routage et les sorties tout en conservant le contexte entre les dialogues.
- L’auto-correction et le HITL renforcent la robustesse face aux erreurs et au raffinement des résultats.
- L’évaluation Spider montre des performances compétitives et une faible latence pour les tâches NL-to-SQL cross-domaines.
- La démonstration Streamlit est illustrative; les déploiements en production nécessitent des configurations de sécurité appropriées.
FAQ
-
- **Q : Quel est le rôle d’Amazon Nova dans cette solution ?**
mazon Nova fournit les modèles de base utilisés pour la compréhension du langage naturel et le raisonnement, permettant la traduction NL-to-SQL dans le cadre ReAct. - **Q : Comment fonctionne l’auto-correction ?** **A :** Lors d’une erreur d’exécution, l’agent utilise l’erreur et le contexte pour régénérer une requête SQL corrigée, améliorant la robustesse. - **Q : Quel est le rôle de LangGraph ?** **A :** LangGraph met en œuvre le pattern ReAct, en coordonnant les étapes de raisonnement et les actions pour le traitement des requêtes de bout en bout. - **Q : Quel dataset a été utilisé pour l’évaluation et que montre-t-il ?** **A :** Spider (10 181 questions, 5 693 requêtes SQL uniques, 200 bases, 138 domaines) en zero-shot démontre la capacité de généralisation et une latence faible. - **Q : Où trouver des informations ou collaborer avec GenAIIC ?** **A :** GenAIIC propose un accès à des experts pour identifier des cas d’usage et déployer des solutions d’IA générative; les informations se trouvent via les canaux AWS Generative AI Innovation Center.
Références
- https://aws.amazon.com/blogs/machine-learning/natural-language-based-database-analytics-with-amazon-nova/
- Les mentions d’Amazone Nova et Bedrock sont intégrées dans l’article comme contexte de la solution.
More news

Faire passer vos agents IA du concept à la production avec Amazon Bedrock AgentCore
Une exploration détaillée de la façon dont Amazon Bedrock AgentCore aide à faire passer des applications IA basées sur des agents du proof of concept à des systèmes de production de niveau entreprise, en préservant mémoire, sécurité, observabilité et gestion d’outils à l’échelle.

Scaleway rejoint les Fournisseurs d’Inference de Hugging Face pour une Inférence Serverless et Faible Latence
Scaleway est désormais un Fournisseur d’Inference pris en charge sur Hugging Face Hub, permettant l’inférence serverless directement sur les pages de modèles avec les SDK JS et Python. Accédez à des modèles open-weight populaires et bénéficiez d’une latence réduite.

Prévoir les phénomènes météorologiques extrêmes en quelques minutes sans superordinateur : Huge Ensembles (HENS)
NVIDIA et le Lawrence Berkeley National Laboratory présentent Huge Ensembles (HENS), un outil IA open source qui prévoit des événements météorologiques rares et à fort impact sur 27 000 années de données, avec des options open source ou prêtes à l’emploi.

Surveiller l’inférence par lot Bedrock d’AWS via les métriques CloudWatch
Apprenez à surveiller et optimiser les jobs d’inférence par lot Bedrock via CloudWatch, with alertes et tableaux de bord pour améliorer les performances, les coûts et l’exploitation.

Prompting pour la précision avec Stability AI Image Services sur Amazon Bedrock
Bedrock intègre Stability AI Image Services avec neuf outils pour créer et modifier des images avec précision. Apprenez les techniques de prompting adaptées à l’entreprise.

Utiliser les AWS Deep Learning Containers avec SageMaker AI géré MLflow
Découvrez comment les AWS Deep Learning Containers (DLCs) s’intègrent à SageMaker AI géré par MLflow pour équilibrer le contrôle de l’infrastructure et une gouvernance ML robuste. Un flux TensorFlow pour la prédiction de l’âge des abalones illustre le suivi de bout en bout et la traçabilité des modè