Construire un flux de travail sans serveur Bedrock pour l’orchestration de jobs par lot avec AWS Step Functions
Sources: https://aws.amazon.com/blogs/machine-learning/build-a-serverless-amazon-bedrock-batch-job-orchestration-workflow-using-aws-step-functions, https://aws.amazon.com/blogs/machine-learning/build-a-serverless-amazon-bedrock-batch-job-orchestration-workflow-using-aws-step-functions/, AWS ML Blog
TL;DR
- Bedrock batch inference offre une voie rentable et scalable pour les charges de travail volumineuses, avec une remise de 50% par rapport au traitement à la demande.
- Cet article présente un motif d’orchestration sans serveur utilisant AWS Step Functions et une pile AWS CDK pour gérer le prétraitement, les jobs en lot en parallèle et le post-traitement.
- La démonstration exploite 2,2 millions de lignes du jeu SimpleCoT, pour des tâches de génération de texte ou d’embeddings.
- Les templates de prompts et le format des entrées sont centralisés dans le code (prompt_templates.py et prompt_id_to_template), avec des sources d’entrée configurables (datasets Hugging Face ou CSV/Parquet sur S3).
- La solution est conçue pour être rentable et scalable, avec des indications sur le suivi, le parallélisme et le nettoyage des ressources.
Contexte et antécédents
À mesure que les organisations adoptent des modèles de fondation pour des charges AI/ML, les motifs d’inférence à grande échelle se répartissent en deux catégories générales: l’inférence en temps réel et l’inférence par lot. L’inférence par lot est adaptée au traitement de très grands ensembles de données où des résultats immédiats ne sont pas requis, et Bedrock propose une option économique avec une remise de 50% par rapport au traitement à la demande. Mettre en place l’inférence par lot à grande échelle présente des défis tels que le formatage des entrées, la gestion des quotas de jobs, l’orchestration des exécutions concurrentes et le post-traitement des sorties du modèle. Cette approche réunit des composants sans serveur et évolutifs afin de simplifier l’orchestration des flux en lot. Le flux couvre trois phases: le prétraitement des jeux de données (par exemple le formatage des prompts), l’exécution des jobs en lot en parallèle, et le post-traitement pour analyser les sorties du modèle. La solution est conçue pour être flexible et scalable, permettant des flux comme la génération d’embeddings pour des millions de documents ou l’exécution de tâches d’évaluation ou de complétion sur de grands ensembles de données. L’architecture est déployée via AWS Cloud Development Kit (CDK) et orchestre une machine d’états Step Functions pour gérer le processus de bout en bout. Dans l’exemple, 2,2 millions de lignes du dataset SimpleCoT, hébergé sur Hugging Face, illustrent le pipeline. SimpleCoT est un ensemble de tâches conçues pour démontrer le raisonnement en chaîne dans les modèles de langage. Le motif Bedrock batch inference utilise des composants scalables et sans serveur pour couvrir les considérations architecturales clés des flux de traitement par lot. Les sections suivantes décrivent les étapes pour déployer le stack CDK et exécuter le flux dans votre environnement AWS.
Ce qui est nouveau
Cet article met en avant une architecture sans serveur et scalable pour le traitement par lot avec Bedrock, orchestrée par AWS Step Functions. Il montre comment:
- Prétraiter les entrées et formater les prompts via le module prompt_templates.py et le mapping prompt_id_to_template qui associe une tâche à un prompt spécifique.
- Lancer des jobs en lot en parallèle et les gérer via une machine d’états Step Functions déployée avec CDK.
- Post-traiter les sorties pour extraire les résultats et les agréger dans des fichiers Parquet qui conservent les colonnes d’entrée et ajoutent les données de sortie (réponse ou embedding). Un cas concret utilise 2,2 millions de lignes de SimpleCoT. L’environnement CDK est utilisé pour déployer le flux et le processus peut être étendu à d’autres jeux de données ou charges FM. Le nombre maximum de jobs simultanés est contrôlé par la variable maxConcurrentJobs dans cdk.json, ce qui permet d’ajuster le throughput et le coût. L’exemple montre également comment repérer les sorties CloudFormation indiquant les noms du bucket et du workflow Step Functions.
En quoi cela compte (impact pour les développeurs et les entreprises)
Pour les développeurs et les organisations, cette approche permet un traitement par lot scalable et économique pour des inférences sur des modèles de fondation. Avantages principaux:
- Coûts réduits grâce à Bedrock pour l’inférence par lot, rendant faisable le traitement de millions d’enregistrements pour des embeddings ou des tâches de génération.
- Architecture sans serveur axée sur l’orchestration, réduisant la charge opérationnelle des pipelines d’inférence par lot.
- Clarté dans la séparation entre prétraitement, calcul et post-traitement, facilitant la maintenance et l’extension du flux pour différents modèles et jeux de données.
- Intégration facile avec des sources de données telles que S3 ou Hugging Face, facilitant la réutilisation entre projets.
- Contrôles explicites de la concurrence et déploiement via CDK, permettant d’ajuster le pipeline pour répondre aux besoins de l’entreprise. Pour les équipes travaillant sur l’étiquetage des données, la génération de données synthétiques ou la distillation de modèles, ce motif offre un blueprint pragmatique pour des pipelines d’inférence par lot dans le cloud.
Détails techniques ou Implémentation
Voici une vue d’ensemble de la mise en œuvre du flux Bedrock par lot avec AWS Step Functions, en soulignant les étapes et points de configuration.
- Prérequis: Installez les paquets requis avec la commande npm i.
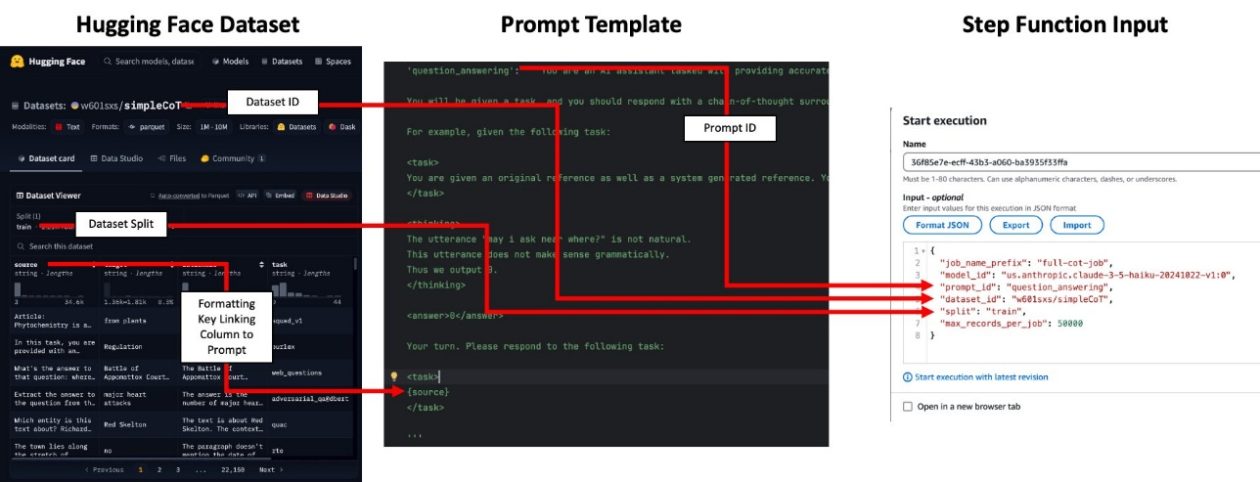
- Prompts et mapping: Vérifiez prompt_templates.py et ajoutez un nouveau template de prompt au mapping prompt_id_to_template pour votre cas d’utilisation. Le mapping relie une tâche à un prompt spécifique. Assurez-vous que les clés de formatage du template correspondent aux colonnes du jeu de données d’entrée, comme requis par les prompts. Note: les prompts ne sont pas utilisés pour les travaux d’embedding.
- Déploiement du stack: Déployez le stack CDK avec npm run cdk deploy. Après le déploiement, notez les sorties CloudFormation qui indiquent les noms du bucket de données et du workflow Step Functions.
- Préparation des données: Votre entrée peut être un Hugging Face dataset ID (par exemple, w601sxs/simpleCoT) ou un jeu de données sur S3 (CSV ou Parquet). Si vous utilisez Hugging Face, référencez l’ID du dataset et la split (par exemple, train); le dataset sera extrait du Hugging Face Hub. Les colonnes du dataset doivent correspondre aux clés de formatage requises par les prompts.
- Mappage des prompts et formatage des données: La colonne utilisée pour les prompts est exposée via une clé de formatage (par exemple, topic). Le dataset doit contenir une colonne correspondante pour que le prompt soit correctement rempli. Pour les embeddings, il n’est pas nécessaire de fournir prompt_id, mais le CSV d’entrée doit contenir la colonne input_text contenant le texte à embarquer.
- Ingestion et orchestration des données: Téléchargez votre CSV ou Parquet dans le bucket S3 désigné (par exemple, aws s3 cp topics.csv s3://batch-inference-bucket-/inputs/jokes/topics.csv). Ouvrez le console Step Functions et soumettez une entrée avec un s3_uri pointant vers votre jeu de données. Le prompt_id pointe vers un template de prompt qui génère la raison et la réponse pour chaque ligne (ou, pour les embeddings, opère sur input_text).
- Observabilité et surveillance: Le nombre maximal de jobs simultanés est contrôlé par maxConcurrentJobs dans le fichier cdk.json. Les fichiers Parquet de sortie contiennent les mêmes colonnes que l’entrée plus la sortie du modèle. Pour les tâches de génération, la colonne de sortie est response; pour les embeddings, la colonne embedding (liste de nombres à virgule flottante).
- Remarques sur le temps et les coûts: il n’existe pas de SLA garanti pour l’API Batch Inference; les temps d’exécution varient selon la demande du modèle. Dans une expérimentation, le traitement de 2,2 millions d’enregistrements répartis sur 45 jobs avec jusqu’à 20 concurrents a pris en moyenne 9 heures par job, soit environ 27 heures au total.
- Nettoyage des ressources: pour éviter des coûts récurrents, exécutez cdk destroy pour démonter les ressources créées par la stack CDK. Le flux et la solution associée sont disponibles dans un dépôt public GitHub mentionné dans l’article.
| Configuration clé | Description |
|---|---|
| maxConcurrentJobs | Contrôle du nombre maximum de jobs en parallèle via le contexte CDK dans cdk.json, permettant d’ajuster le throughput et le coût |
| Formats d’entrée | Hugging Face dataset ID ou CSV/Parquet sur S3 |
| Sortie | Fichiers Parquet contenant les colonnes d’entrée plus la sortie du modèle; text generation produit la colonne response et embeddings la colonne embedding |
Flux de travail pratique
- Étape 1: Prétraiter vos données pour les adapter aux prompts et vous assurer que toutes les clés de formatage sont présentes.
- Étape 2: Lancer les jobs en parallèle et gérer leur exécution via la machine d’états Step Functions, en respectant la limite de concurrence.
- Étape 3: Post-traiter les sorties pour extraire les résultats, en les consolidant dans des fichiers Parquet jointes aux colonnes d’entrée et à la sortie du modèle.
Points à retenir
- L’inférence par lot avec Bedrock est scalable et économique pour des inférences massives quand des résultats immédiats ne sont pas requis.
- Un pattern d’orchestration sans serveur via Step Functions simplifie les pipelines d’inférence par lot en séparant prétraitement, calcul et post-traitement.
- Le workflow prend en charge diverses sources de données (Hugging Face ou S3) et les tâches de génération de texte ou d’embeddings, avec des sorties stockées en Parquet pour l’analyse.
- Des contrôles de concurrence et le déploiement CDK permettent d’obtenir des pipelines reproductibles et auditables adaptés aux ressources de l’entreprise.
- L’article donne un exemple concret avec 2,2 millions de lignes et peut servir de base pour d’autres modèles et jeux de données.
FAQ
-
- **Q : Quel problème résout cette solution ?**
Fournit une architecture robuste, sans serveur, pour orchestrer l’inférence Bedrock par lot à grande échelle, incluant le prétraitement, l’exécution parallèle et le post-traitement. - **Q : Quelles sources de données sont prises en charge en entrée ?** **A :** Un Hugging Face dataset ID (avec la division) ou un jeu de données sur S3 en CSV ou Parquet. - **Q : Comment la concurrence est-elle gérée ?** **A :** Le nombre maximal de jobs simultanés est contrôlé par maxConcurrentJobs dans le fichier de configuration CDK (cdk.json). - **Q : Comment nettoyer les ressources après les tests ?** **A :** Exécutez cdk destroy pour détruire les ressources créées par la stack CDK. - **Q : Quelles sorties produit le flux ?** **A :** Des fichiers Parquet avec les colonnes d’entrée et la sortie du modèle; pour la génération de texte, la colonne est response et pour les embeddings, la colonne est embedding.
Références
More news

Faire passer vos agents IA du concept à la production avec Amazon Bedrock AgentCore
Une exploration détaillée de la façon dont Amazon Bedrock AgentCore aide à faire passer des applications IA basées sur des agents du proof of concept à des systèmes de production de niveau entreprise, en préservant mémoire, sécurité, observabilité et gestion d’outils à l’échelle.

Scaleway rejoint les Fournisseurs d’Inference de Hugging Face pour une Inférence Serverless et Faible Latence
Scaleway est désormais un Fournisseur d’Inference pris en charge sur Hugging Face Hub, permettant l’inférence serverless directement sur les pages de modèles avec les SDK JS et Python. Accédez à des modèles open-weight populaires et bénéficiez d’une latence réduite.

Surveiller l’inférence par lot Bedrock d’AWS via les métriques CloudWatch
Apprenez à surveiller et optimiser les jobs d’inférence par lot Bedrock via CloudWatch, with alertes et tableaux de bord pour améliorer les performances, les coûts et l’exploitation.

Prompting pour la précision avec Stability AI Image Services sur Amazon Bedrock
Bedrock intègre Stability AI Image Services avec neuf outils pour créer et modifier des images avec précision. Apprenez les techniques de prompting adaptées à l’entreprise.

Utiliser les AWS Deep Learning Containers avec SageMaker AI géré MLflow
Découvrez comment les AWS Deep Learning Containers (DLCs) s’intègrent à SageMaker AI géré par MLflow pour équilibrer le contrôle de l’infrastructure et une gouvernance ML robuste. Un flux TensorFlow pour la prédiction de l’âge des abalones illustre le suivi de bout en bout et la traçabilité des modè

Évoluer la production visuelle avec Stability AI Image Services dans Amazon Bedrock
Stability AI Image Services est désormais disponible dans Amazon Bedrock, offrant des capacités d’édition d’images prêtes à l’emploi via l’API Bedrock et étendant les modèles Stable Diffusion 3.5 et Stable Image Core/Ultra déjà présents.