Comment Amazon Finance a construit un assistant IA utilisant Amazon Bedrock et Amazon Kendra pour aider les analystes à la découverte des données et aux insights commerciaux
Sources: https://aws.amazon.com/blogs/machine-learning/how-amazon-finance-built-an-ai-assistant-using-amazon-bedrock-and-amazon-kendra-to-support-analysts-for-data-discovery-and-business-insights, https://aws.amazon.com/blogs/machine-learning/how-amazon-finance-built-an-ai-assistant-using-amazon-bedrock-and-amazon-kendra-to-support-analysts-for-data-discovery-and-business-insights/, AWS ML Blog
TL;DR
- Amazon Finance a conçu un assistant IA qui associe Claude 3 Sonnet via Amazon Bedrock avec la recherche intelligente d’Amazon Kendra pour aider les analystes à découvrir les données et à générer des insights.
- La solution repose sur Retrieval Augmented Generation (RAG) : des stockages vectoriels pour la recherche sémantique et une génération augmentée ancrée dans les connaissances récupérées pour réduire les hallucinations.
- Amazon Kendra Enterprise Edition Index a été choisi plutôt que OpenSearch Service et Amazon Q Business pour ses capacités intégrées, son traitement de documents en plus de 40 formats, ses connecteurs d’entreprise et sa gestion avancée des requêtes.
- L’interface est construite avec Streamlit; les évaluations montrent une réduction de 30% du temps de recherche et une amélioration de 80% de l’exactitude des résultats, avec des gains de précision et de rappel.
- L’architecture standardise l’accès aux données au sein d’Amazon Finance, préserve le savoir institutionnel et améliore l’agilité de la prise de décision. Les affirmations ci-dessus s’appuient sur le déploiement décrit par l’équipe Amazon Finance et cité dans le AWS ML Blog [https://aws.amazon.com/blogs/machine-learning/how-amazon-finance-built-an-ai-assistant-using-amazon-bedrock-and-amazon-kendra-to-support-analysts-for-data-discovery-and-business-insights/].
Contexte et arrière-plan
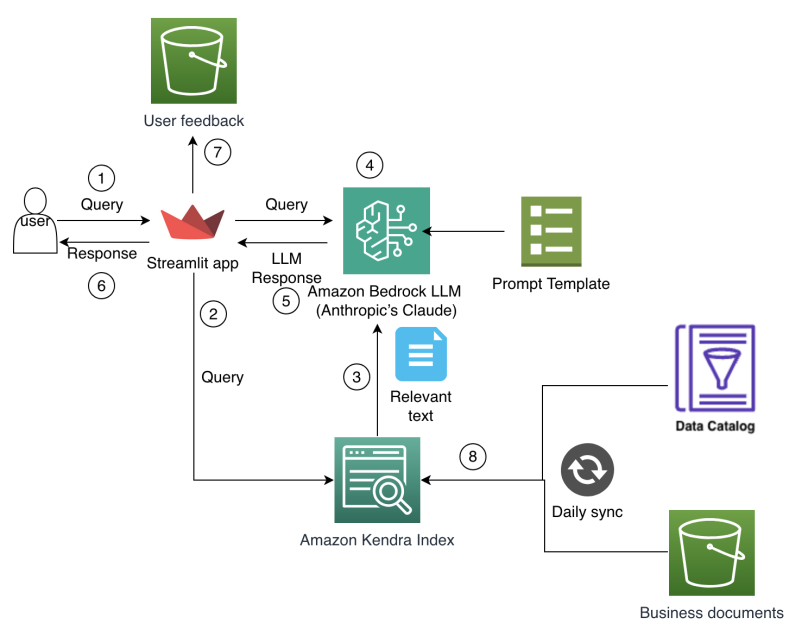
Les analystes financiers d’Amazon Finance font face à une complexité croissante dans la planification et l’analyse, travaillant avec d’immenses ensembles de données provenant de multiples systèmes, lacs de données et unités opérationnelles. La navigation manuelle dans les catalogues de données et la réconciliation d’informations issues de sources disparates consomment un temps précieux, laissant moins d’espace pour l’analyse et la génération d’insights. Les données historiques et les décisions passées résident dans des documents et des systèmes hérités, rendant difficile l’utilisation des apprentissages antérieurs lors des cycles de planification. À mesure que le contexte commercial évolue rapidement, les analystes ont besoin d’un accès rapide aux métriques pertinentes, aux hypothèses de planification et aux insights financiers pour prendre des décisions basées sur les données. Les outils traditionnels reposant sur des recherches par mots-clés et des requêtes rigides peinent à saisir les relations contextuelles dans les données financières et ne préservent pas nécessairement le savoir institutionnel, conduisant à des analyses redondantes et à des hypothèses de planification incohérentes entre équipes. En résumé, les analystes avaient besoin d’un moyen plus intuitif d’accéder, de comprendre et d’utiliser le savoir financier et les actifs de données de l’organisation. L’équipe Amazon Finance a développé un assistant IA de bout en bout pour répondre à ces défis, en combinant IA générative et recherche d’entreprise. L’objectif était de permettre aux analystes d’interagir avec des sources de données financières et des documents via des requêtes en langage naturel, réduisant le besoin de recherches manuelles entre plusieurs systèmes tout en garantissant que les réponses soient fondées sur une base de connaissances d’entreprise reflétant le contexte institutionnel et les exigences de sécurité. Cette approche accélère non seulement la découverte des données, mais aide aussi à préserver les raisonnements de décision et à standardiser la planification à travers l’organisation. L’approche s’appuie sur le modèle Retrieval Augmented Generation (RAG), qui combine récupération de connaissances externes et génération de langage. Le système stocke et interroge des représentations de texte en haute dimension via des vecteurs pour supporter des recherches sémantiques, conditionne le modèle de langage au contexte récupéré et génère des réponses ancrées dans les sources. Le but est d’assurer précision et traçabilité des échanges IA pour les finances. L’implémentation utilise des LLMs sur Amazon Bedrock et une recherche sémantique avec Amazon Kendra pour offrir une expérience d’assistant d’entreprise cohérente, sécurisée et évolutive. Le modèle retenu est Claude 3 Sonnet d’Anthropic, accessible via Bedrock, choisi pour ses capacités de génération et de raisonnement. L’intégration avec Kendra permet de comprendre l’intention de l’utilisateur et de récupérer des réponses pertinentes en s’appuyant sur des documents d’entreprise. Les fonctionnalités de sécurité d’entreprise de Kendra protègent les données et soutiennent les exigences de conformité en finance. L’interface utilisateur suit une approche Streamlit pour faciliter le développement rapide, l’itération et le déploiement. L’objectif central est le pattern Retrieval Augmented Generation (RAG), qui sépare la récupération d’informations du processus de génération afin de préserver la fiabilité et la précision des réponses. L’intégration entre Claude 3 Sonnet, Bedrock et Kendra forme un flux de travail RAG cohérent qui ancre les réponses dans les sources d’entreprise. Le post AWS décrit ces choix de conception et les résultats observés. [source]
Nouveautés et architecture
La mise en œuvre associe plusieurs technologies modernes dans un flux de travail intégré. Les éléments clés incluent :
- RAG comme socle, combinant recherche sémantique et génération ancrée dans le savoir récupéré.
- Couche de récupération vectorielle pour une recherche sémantique riche en contexte.
- Un LLM via Amazon Bedrock, Claude 3 Sonnet, pour la génération de langage et le raisonnement.
- Amazon Kendra Enterprise Edition Index pour le NLP d’entreprise, le traitement automatique des documents (>40 formats), les connecteurs d’entreprise et la gestion intelligente des requêtes (sinonymes, suggestions de raffinement).
- Une interface Streamlit pour un déploiement rapide et une expérience utilisateur convaincante, avec des templates de prompts pour formater les requêtes et intégrer les connaissances récupérées.
- Un cadre d’évaluation pour mesurer les performances et l’expérience utilisateur. Les métriques d’évaluation montrent une réduction du temps de recherche et une amélioration de l’exactitude des résultats de recherche, démontrant l’impact opérationnel de l’approche RAG dans un contexte de finances. Le post AWS détaille ces résultats et le raisonnement autour des choix technologiques. [source]
Détails techniques ou Mise en œuvre
Composants et raisons:
- Récupération intelligente avec des stockages vectoriels pour une recherche sémantique plus riche et plus pertinente.
- Génération augmentée (RAG) pour produire des réponses contextuelles en utilisant Claude 3 Sonnet conditionné par le contexte récupéré.
- LLMs sur Amazon Bedrock avec Claude 3 Sonnet, choisi pour ses capacités de raisonnement et de génération.
- Amazon Kendra Enterprise Edition Index utilisé pour le NLP avancé, le traitement automatique de documents dans plus de 40 formats, les connecteurs et le maniement intelligent des requêtes (synonymes, raffinement).
- UI et outils : Streamlit pour un développement rapide et une déploiement facile.
- Templates de prompts : structurer les requêtes, intégrer les connaissances et imposer des contraintes de génération.
- Cadre d’évaluation : métriques de précision, de rappel et de temps de réponse pour mesurer les améliorations en découverte de données et en recherche de connaissances. Les résultats montrent une amélioration significative des performances, avec des perspectives d’amélioration continue via l’enrichissement des métadonnées, comme indiqué dans le post. [source] | Service | Raison d’usage | Caractéristiques clés pertinentes pour ce cas |---|---|---| | Amazon Kendra Enterprise Edition Index | NLP prêt à l’emploi, réduction de la configuration manuelle | Compréhension du langage naturel; traitement automatique des documents (>40 formats); connecteurs d’entreprise; gestion intelligente des requêtes, y compris reconnaissance de synonymes et suggestions de raffinement |OpenSearch Service | Configuration manuelle nécessaire | Implémentation manuelle des fonctionnalités de recherche sémantique et vectorielle |Amazon Q Business | Moins robuste/flexible | Capacités de récupération, mais moins adaptées au contexte d’entreprise par rapport à Kendra | Cette comparaison justifie le choix de Kendra en tant que composant de récupération, en complément de Bedrock et de l’architecture RAG.
Pourquoi cela compte (impact pour les développeurs et les entreprises)
Cette approche montre comment les organisations peuvent déployer et faire évoluer une IA d’aide à la découverte de données tout en maintenant la gouvernance et la sécurité des données. En ancrant les réponses dans une base de connaissances d’entreprise et en utilisant une recherche sémantique pour présenter les documents pertinents, les analystes accèdent plus rapidement aux métriques clés, aux hypothèses et au contexte historique. Le cadre RAG permet de préserver le savoir institutionnel, évitant la perte de connexions décisionnelles lorsque les équipes changent. Pour les développeurs et les ingénieurs, l’architecture expose un chemin concret pour combiner récupération vectorielle et LLM robuste, avec une couche de recherche d’entreprise prête pour la production. Les capacités de Kendra Enterprise Edition apportent NLP, traitement des documents et connecteurs adaptés aux exigences de conformité et de gouvernance des finances. L’impact pratique est une meilleure agilité de planification, des décisions plus cohérentes et une meilleure interopérabilité au sein des opérations mondiales. Le post AWS décrit ce cas concret et ses bénéfices. [source]
Points clés (takeaways)
- Les flux d’IA fondés sur la récupération (RAG) peuvent transformer la découverte de données et les insights en finance.
- La recherche sémantique basée sur vecteurs, associée à la génération, réduit les hallucinations et améliore la précision.
- Le choix d’une solution de recherche d’entreprise avec NLP intégré et traitement de documents (Kendra Enterprise Edition) facilite l’adoption et la conformité.
- L’interface Streamlit permet un développement rapide et une expérience utilisateur agréable pour les analystes.
- Un cadre d’évaluation structuré guide l’amélioration continue, notamment via l’enrichissement des métadonnées.
FAQ
-
Comment l’assistant fonde-t-il ses réponses ?
Il récupère des informations pertinentes via une recherche sémantique dans un corpus vectoriel, conditionne Claude 3 Sonnet au contexte et génère des réponses ancrées dans les sources récupérées.
-
Pourquoi choisir Claude 3 Sonnet via Bedrock pour ce cas ?
Claude 3 Sonnet offre de solides capacités de génération de langage et de raisonnement pour soutenir une interaction en langage naturel bien alignée sur le contexte métier.
-
uelles métriques ont été observées ?
Réduction de 30% du temps de recherche et amélioration de 80% de l’exactitude des résultats de recherche, avec des gains de précision et de rappel pour la découverte de données et la recherche de connaissances.
-
uels bénéfices de Kendra Enterprise Edition par rapport à OpenSearch ou Q Business ?
NLP prêt à l’emploi, traitement automatique des documents, connecteurs d’entreprise, reconnaissance de synonymes et raffinement des requêtes, moins de configuration manuelle et meilleure récupération.
Références
More news

Faire passer vos agents IA du concept à la production avec Amazon Bedrock AgentCore
Une exploration détaillée de la façon dont Amazon Bedrock AgentCore aide à faire passer des applications IA basées sur des agents du proof of concept à des systèmes de production de niveau entreprise, en préservant mémoire, sécurité, observabilité et gestion d’outils à l’échelle.

Surveiller l’inférence par lot Bedrock d’AWS via les métriques CloudWatch
Apprenez à surveiller et optimiser les jobs d’inférence par lot Bedrock via CloudWatch, with alertes et tableaux de bord pour améliorer les performances, les coûts et l’exploitation.

Prompting pour la précision avec Stability AI Image Services sur Amazon Bedrock
Bedrock intègre Stability AI Image Services avec neuf outils pour créer et modifier des images avec précision. Apprenez les techniques de prompting adaptées à l’entreprise.

Utiliser les AWS Deep Learning Containers avec SageMaker AI géré MLflow
Découvrez comment les AWS Deep Learning Containers (DLCs) s’intègrent à SageMaker AI géré par MLflow pour équilibrer le contrôle de l’infrastructure et une gouvernance ML robuste. Un flux TensorFlow pour la prédiction de l’âge des abalones illustre le suivi de bout en bout et la traçabilité des modè

Évoluer la production visuelle avec Stability AI Image Services dans Amazon Bedrock
Stability AI Image Services est désormais disponible dans Amazon Bedrock, offrant des capacités d’édition d’images prêtes à l’emploi via l’API Bedrock et étendant les modèles Stable Diffusion 3.5 et Stable Image Core/Ultra déjà présents.

Créer des flux de travail agentiques avec GPT OSS d’OpenAI sur SageMaker AI et Bedrock AgentCore
Vue d’ensemble complète sur le déploiement des modèles GPT OSS d’OpenAI sur SageMaker AI et Bedrock AgentCore pour alimenter un analyseur d’actions multi-agents avec LangGraph, incluant la quantification MXFP4 en 4 bits et une orchestration sans serveur.