Renforcer la recherche sur la qualité de l’air avec des analyses prédictives sécurisées pilotées par le ML
Sources: https://aws.amazon.com/blogs/machine-learning/empowering-air-quality-research-with-secure-ml-driven-predictive-analytics, https://aws.amazon.com/blogs/machine-learning/empowering-air-quality-research-with-secure-ml-driven-predictive-analytics/, AWS ML Blog
TL;DR
- Un flux d’imputation de données comble les lacunes PM2.5 grâce à un modèle ML entraîné dans SageMaker Canvas, orchestré par AWS Lambda et AWS Step Functions.
- Le jeu de données d’exemple comprend plus de 15 millions d’enregistrements de mars 2022 à octobre 2022, en Kenya et en Nigérie, sur 23 capteurs dans 15 emplacements.
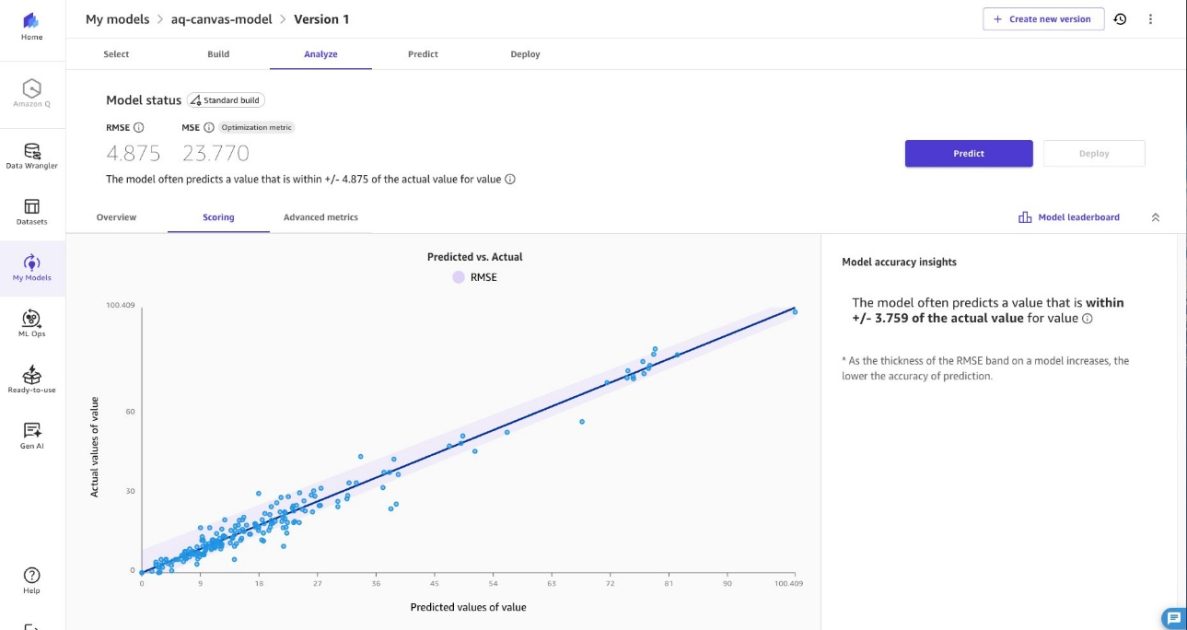
- Les prédictions comblent les valeurs PM2.5 manquantes dans une plage de ±4,875 µg/m³ pour préserver la fiabilité des tendances.
- La solution met l’accent sur la sécurité, le chiffrement et le déploiement en réseau privé, avec un cadre de responsabilité partagée pour la protection des données.
Contexte et antécédents
La pollution de l’air demeure un défi important pour la santé environnementale en Afrique. Des organisations comme sensors.AFRICA déployent des capteurs pour surveiller la qualité de l’air, mais les lacunes de données persistent en raison d’instabilités d’alimentation et de connectivité dans des zones à haut risque, où l’entretien est limité. Des données PM2.5 manquantes réduisent le pouvoir statistique et introduisent des biais dans les estimations, rendant difficile la détection fiable des tendances et les conclusions sur les schémas de qualité de l’air. Ces lacunes compromettent les décisions fondées sur des preuves pour le contrôle de la pollution et la conformité réglementaire. L’exposition au PM2.5 est associée à des millions de décès prématurés dans le monde, d’où l’importance de prévisions précises pour la santé publique. L’article met en évidence la capacité de prévision en séries temporelles d’Amazon SageMaker Canvas, une plateforme ML à faible code, pour prédire les valeurs PM2.5 à partir de jeux de données incomplets. Canvas offre une résilience face aux données manquantes, permettant une opération continue des réseaux de surveillance pendant les pannes ou la maintenance des capteurs. Cette approche aide les agences environnementales et les responsables de la santé publique à accéder à des informations critiques sans interruption pour des alertes et des analyses à long terme. L’approche combine des prévisions avec l’imputation des données à l’aide d’Amazon SageMaker AI, AWS Lambda et AWS Step Functions. Le jeu de données d’exemple provient d’openAFRICA et contient plus de 15 millions d’enregistrements (mars 2022 – octobre 2022) de 23 capteurs sur 15 sites, au Kenya et en Nigérie, démontrant comment adapter la solution à des données réelles. L’architecture repose sur deux composants ML : un flux d’entraînement et un flux d’inférence. Ces flux sont construits avec SageMaker Canvas pour le développement et l’exportation du modèle vers l’inférence en lot. Le processus d’entraînement commence par l’extraction des données des capteurs depuis une base de données, l’importation dans Canvas pour l’analyse prédictive et la préparation des données, puis l’exportation du modèle entraîné pour l’inférence en batch. L’approche prend en charge le ré-entrainement avec de nouveaux jeux PM2.5 pour s’adapter à l’évolution des capteurs.
Ce qu’il y a de nouveau
Cet article présente un flux complet et sécurisé d’imputation des données PM2.5 à partir de lacunes, en utilisant une combinaison de services AWS. Points clés:
- Prévision de séries temporelles avec SageMaker Canvas pour estimer les valeurs manquantes de PM2.5 dans des jeux de données comportant des lacunes.
- Flux de travail robuste de bout en bout : extraction des données, entraînement dans Canvas, export du modèle et pipeline d’inférence par batch.
- Orchestration quotidienne : une fonction Lambda lance un travail Transform Batch SageMaker toutes les 24 heures pour les données avec lacunes, puis met à jour le jeu de données avec les prédictions.
- Données d’exemple réalistes : plus de 15 millions d’enregistrements entre mars 2022 et octobre 2022, au Kenya et en Nigérie, issus de 23 capteurs sur 15 emplacements.
- Sécurité par conception : chiffrement au repos sur S3, la base de données Aurora PostgreSQL-compatible et SageMaker Canvas; chiffrement en transit via TLS; identifiants IAM temporaires pour l’accès RDS; rôles Lambda à privilèges minimaux; déploiement dans des sous-réseaux privés avec des points de terminaison VPC pour S3 et SageMaker AI.
- Déploiement via IaC : l’article décrit une approche CDK pour l’entraînement, l’enregistrement du modèle et le déploiement, facilitant les mises à jour répétables et traçables. Pour déployer, le projet fournit un dépôt avec du code d’exemple et un README détaillant les étapes.
Pourquoi cela compte (impact pour les développeurs/entreprises)
Pour les équipes et entreprises travaillant sur la surveillance environnementale, cette approche offre :
- Des pipelines de données résilients qui maintiennent l’opération malgré les pannes des capteurs, réduisant les lacunes et les coûts.
- Des insights exploitables de PM2.5 issus de données incomplètes sans nécessiter des flux parfaits, aidant les chercheurs et les décideurs à suivre les tendances en temps utile.
- Une solution scalable, sécurisée et cloud qui s’intègre à des systèmes existants (Aurora) et au stockage d’objets (S3), avec des contrôles de sécurité stricts.
- Un modèle d’implémentation traçable et reproductible grâce à l’Infrastructure as Code via CDK.
- Des pratiques claires de protection des données en transit et au repos, avec des permissions IAM granulaires et un réseau privé. Ce travail soutient les objectifs de santé publique en permettant une surveillance continue et des analyses PM2.5 plus fiables, favorisant les actions de contrôle de pollution et la conformité réglementaire.
Détails techniques ou Mise en œuvre
La solution comprend deux composants ML principaux : un flux d’entraînement et un flux d’inférence, intégrés dans un pipeline sécurisé.
- Données et entraînement
- Des données PM2.5 historiques sont extraites d’une base relationnelle et préparées dans SageMaker Canvas pour l’analyse prédictive.
- Canvas permet d’entraîner un modèle pour une cible unique avec des transformations et une ingénierie des caractéristiques adaptées aux séries temporelles.
- Après l’entraînement, Canvas exporte le modèle pour l’inférence en batch.
- Le jeu de données d’entraînement d’exemple comprend plus de 15 millions d’enregistrements entre mars 2022 et octobre 2022, issus de 23 capteurs dans 15 localisations au Kenya et en Nigérie.
- Inférence et imputation des données
- Le Step Functions coordonne le flux ; une fonction Lambda est appelée toutes les 24 heures.
- La Lambda démarre un travail Transform Batch SageMaker pour prédire les valeurs manquantes des données nouvelles.
- La transformation en batch traite l’ensemble du jeu de données en une seule passe et met à jour le jeu avec les prévisions.
- Cycle de vie du modèle et déploiement
- Après l’entraînement et l’évaluation ( RMSE et autres métriques ), le modèle est enregistré dans le SageMaker Model Registry et déployé pour l’inférence en batch.
- Le déploiement CDK crée un domaine SageMaker AI et un profil utilisateur, en provisionnant les ressources nécessaires pour l’entraînement et l’inférence.
- Le flux comprend la création du modèle SageMaker dans une VPC, le déploiement du travail batch et la mise à jour de l’infrastructure avec le nouvel ID de modèle via cdk deploy.
- La solution prend en charge le réentraînement avec de nouveaux jeux PM2.5.
- Sécurité et conformité
- Chiffrement en repos pour S3, Aurora et SageMaker Canvas.
- Chiffrement en transit via TLS pour toutes les communications Lambda.
- Identifiants IAM temporaires pour l’accès RDS, supprimant les mots de passe statiques.
- Fonctions Lambda fonctionnant avec des privilèges minimaux et des permissions adaptées.
- Déploiement dans des sous-réseaux privés sans accès direct à Internet public, avec des endpoints VPC pour S3 et SageMaker AI.
- Configuration et extensibilité
- L’architecture est conçue pour être adaptée à des changements de configuration futurs via CDK, avec un fichier de configuration décrivant les paramètres par défaut.
- L’approche favorise la sécurité et l’alignement avec le AWS Shared Responsibility Model, invitant les clients à examiner les responsabilités de déploiement sécurisé.
- Tableau: composants clés et rôles
| Composant | Rôle |
|---|---|
| SageMaker Canvas | Entraînement et exportation du modèle pour l’inférence en batch |
| AWS Lambda | Orchestration des mises à jour et démarrage des transformations en batch |
| AWS Step Functions | Coordination du flux de travail de bout en bout |
| Amazon Aurora PostgreSQL‑Compatible | Stockage des données capteurs avec authentification IAM |
| Amazon S3 | Stockage en data lake avec chiffrement en repos |
- Références et notes de déploiement
- L’approche est documentée avec du code d’exemple et des guides d’installation dans le dépôt Git: [email protected]:aws-samples/sample-empowering-air-quality-research-secure-machine-learning-predictive-analytics.git
- L’article est accessible à l’adresse https://aws.amazon.com/blogs/machine-learning/empowering-air-quality-research-secure-ml-driven-predictive-analytics/.
Points à retenir
- L’imputation des lacunes PM2.5 peut être réalisée efficacement via un modèle SageMaker Canvas et un pipeline d’inférence en batch.
- Le déclenchement quotidien par Lambda maintient les jeux de données à jour avec un minimum d’interruptions de surveillance.
- Les mesures de sécurité — chiffrement, IAM à privilèges minimaux et réseau privé — protègent les données environnementales sensibles.
- Le modèle d’infrastructure-as-code facilite des déploiements reproductibles et évolutifs.
FAQ
-
- **Q : Comment l’imputation PM2.5 est-elle réalisée ?**
Le flux entraîne un modèle SageMaker Canvas sur des données historiques PM2.5 et utilise un travail Transform Batch SageMaker pour prédire les valeurs manquantes dans une plage de ±4,875 µg/m³. - **Q : Quelles données ont été utilisées dans l’exemple ?** **A :** Un jeu de données d’entraînement openAFRICA contenant plus de 15 millions d’enregistrements entre mars 2022 et octobre 2022, provenant de 23 capteurs répartis sur 15 sites. - **Q : Quels services AWS composent ce pipeline ?** **A :** SageMaker Canvas pour l’entraînement et l’export, AWS Lambda pour l’orchestration, AWS Step Functions pour la coordination, SageMaker Transform pour l’inférence, Amazon Aurora PostgreSQL-compatible pour le stockage et Amazon S3 pour le data lake, le tout en privé. - **Q : Comment la sécurité est-elle gérée ?** **A :** Chiffrement au repos (S3, Aurora, SageMaker Canvas), chiffrement en transit (TLS), identifiants IAM temporaires pour RDS, rôles Lambda à privilèges minimaux et sous-réseaux privés avec endpoints VPC, en accord avec le AWS Shared Responsibility Model. - **Q : Comment déployer cela dans mon environnement ?** **A :** Le dépôt fournit une approche CDK et un README avec des instructions pour reproduire le flux et l’adapter à vos jeux PM2.5.
Références
- https://aws.amazon.com/blogs/machine-learning/empowering-air-quality-research-secure-ml-driven-predictive-analytics/
- [email protected]:aws-samples/sample-empowering-air-quality-research-secure-machine-learning-predictive-analytics.git
More news

Faire passer vos agents IA du concept à la production avec Amazon Bedrock AgentCore
Une exploration détaillée de la façon dont Amazon Bedrock AgentCore aide à faire passer des applications IA basées sur des agents du proof of concept à des systèmes de production de niveau entreprise, en préservant mémoire, sécurité, observabilité et gestion d’outils à l’échelle.

Surveiller l’inférence par lot Bedrock d’AWS via les métriques CloudWatch
Apprenez à surveiller et optimiser les jobs d’inférence par lot Bedrock via CloudWatch, with alertes et tableaux de bord pour améliorer les performances, les coûts et l’exploitation.

Prompting pour la précision avec Stability AI Image Services sur Amazon Bedrock
Bedrock intègre Stability AI Image Services avec neuf outils pour créer et modifier des images avec précision. Apprenez les techniques de prompting adaptées à l’entreprise.

Utiliser les AWS Deep Learning Containers avec SageMaker AI géré MLflow
Découvrez comment les AWS Deep Learning Containers (DLCs) s’intègrent à SageMaker AI géré par MLflow pour équilibrer le contrôle de l’infrastructure et une gouvernance ML robuste. Un flux TensorFlow pour la prédiction de l’âge des abalones illustre le suivi de bout en bout et la traçabilité des modè

Évoluer la production visuelle avec Stability AI Image Services dans Amazon Bedrock
Stability AI Image Services est désormais disponible dans Amazon Bedrock, offrant des capacités d’édition d’images prêtes à l’emploi via l’API Bedrock et étendant les modèles Stable Diffusion 3.5 et Stable Image Core/Ultra déjà présents.

Créer des flux de travail agentiques avec GPT OSS d’OpenAI sur SageMaker AI et Bedrock AgentCore
Vue d’ensemble complète sur le déploiement des modèles GPT OSS d’OpenAI sur SageMaker AI et Bedrock AgentCore pour alimenter un analyseur d’actions multi-agents avec LangGraph, incluant la quantification MXFP4 en 4 bits et une orchestration sans serveur.