Accélérez le traitement intelligent des documents avec l’IA générative sur AWS
TL;DR
- AWS présente GenAI IDP Accelerator, une solution open source sans serveur qui combine IA générative et Bedrock Data Automation ( et modèles Bedrock ) pour automatiser le traitement intelligent des documents.
- L’accélérateur transforme des documents non structurés en données structurées, permettant un traitement scalable dans divers secteurs tout en réduisant la saisie manuelle et les erreurs.
- Le déploiement est facilité par un modèle CloudFormation et un workflow modulaire par patterns, avec des résultats en quelques jours plutôt qu’en mois.
- Des cas réels, notamment Competiscan et Ricoh, illustrent le traitement à haut volume et l’optimisation de documents de santé. Source
- Le projet met l’accent sur un pipeline configurable, des prompts, des templates d’extraction et des règles de validation, le tout construit sur les services AWS avec une sécurité et une efficacité des coûts accrus.
Contexte et arrière-plan
Chaque jour, les organisations traitent des millions de documents, des factures et contrats aux demandes d’assurance et dossiers médicaux. Une grande partie des données contenues dans ces documents est non structurée, ce qui limite l’exploitation des insights et la valeur métier. La saisie manuelle persiste, car les PDFs, images scannées et formulaires exigent souvent une intervention humaine. Cette approche est lente, source d’erreurs et difficile à faire évoluer avec les volumes croissants. Le paysage IDP a évolué grâce aux modèles de grande taille et à l’IA générative. Les approches basées sur des templates et des règles montrent leurs limites face aux variations des documents et aux mises en page complexes. Les modèles modernes permettent de comprendre le contexte, de gérer des formats variés sans templates et d’obtenir une précision élevée sur des extractions complexes. Cette transition autorise le traitement de multiples types de documents à un coût et un délai réduits. Dans ce cadre, AWS présente GenAI IDP Accelerator comme une solution open source prête pour la production. Le GenAI IDP Accelerator est une solution serverless et modulaire, construite sur les services AWS. Il exploite Bedrock Data Automation pour des capacités de traitement de documents « prêt à l’emploi » et les modèles Bedrock (FMs) pour les scénarios nécessitant une logique personnalisée. L’objectif est de proposer un point de départ robuste compatible avec les entreprises, adaptable rapidement à différents secteurs et types de documents, tout en assurant sécurité et évolutivité. Source Pour les développeurs et les architectes, ce projet offre un chemin concret pour passer d’une démonstration à une solution IDP prête pour la production, axée sur l’évolutivité et la précision pour divers documents. Source
Ce qu’il y a de nouveau
Le GenAI IDP Accelerator est une solution open source prête à être déployée, qui associe IA générative et Bedrock Data Automation à des modèles Bedrock avancés. Points clés :
- Une base sans serveur proposant des patterns de traitement via Bedrock Data Automation, offrant des fonctionnalités de traitement documentaire prêtes à l’emploi, une grande précision et une tarification simple par page. Source
- Intégration avec les modèles Bedrock de pointe pour les documents complexes nécessitant une logique personnalisée.
- Un pipeline modulaire qui enrichit les documents à chaque étape—OCR, classification, extraction, évaluation, résumé et évaluation finale—avec possibilité d’implémenter et de personnaliser chaque étape indépendamment.
- Conception guidée par la configuration, facilitant l’ajustement des prompts, des templates d’extraction et des règles de validation sans toucher à l’infrastructure.
- Déploiement via le template AWS CloudFormation; mise en place en environ 15–20 minutes, puis accès à l’interface web avec les identifiants fournis par e-mail. Source
- Démo pratique (Pattern-1) du flux Bedrock Data Automation et possibilité d’ajouter d’autres patterns selon les besoins.
- Résultats réels de clients mentionnés dans l’article, dont Competiscan et Ricoh, illustrant l’utilité à grand volume et les documents médicaux. Source Le projet est conçu pour s’intégrer dans l’écosystème AWS et offrir une solution prête à escalier pour les entreprises qui automatisent des flux de documents tout en respectant la sécurité et les coûts.
Pourquoi c’est important (impact pour les développeurs/entreprises)
Le GenAI IDP Accelerator répond à deux défis majeurs du traitement documentaire : le volume de données et la diversité des formats. En associant IA générative et pipeline sans serveur sur AWS, la solution permet :
- de traiter des centaines à des millions de documents avec moins d’intervention manuelle, libérant des insights issus de données non structurées plus rapidement ;
- de réduire le temps de mise en production, en favorisant la fiabilité, la gestion d’erreurs et l’évolutivité ;
- de conserver flexibilité et contrôle des coûts, grâce à une architecture modulaire et des règles configurables sans toucher au code infra ;
- de tirer parti de la sécurité, de la fiabilité et de l’écosystème AWS, avec des possibilités d’extension via CDK ou Terraform à l’avenir. Source Pour les développeurs et les architectes, l’accélérateur offre une trajectoire concrète pour passer d’une démonstration à une solution IDP prête pour la production, capable de traiter différents types de documents avec une précision élevée et une scalabilité adaptée. Source
Détails techniques ou Mise en œuvre
Le GenAI IDP Accelerator se présente comme une solution modulaire, sans serveur, construite sur les services AWS. Points techniques clés :
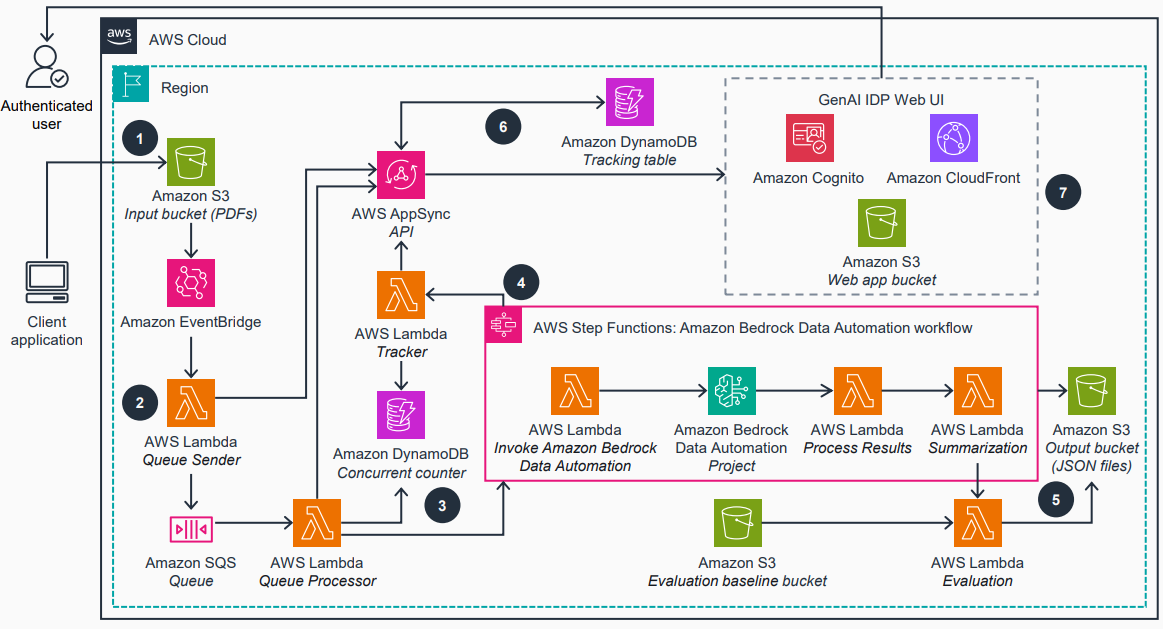
- Pipeline modulaire qui enrichit les documents à chaque étape—OCR, classification, extraction, évaluation, résumé et évaluation finale—permettant de déployer et de personnaliser chaque étape indépendamment, tout en conservant le flux intégré. Cette conception facilite l’adaptation à différents types de documents.
- Utilisation du Bedrock Data Automation pour des capacités de traitement prêts à l’emploi, grande précision et tarification par page simple. Pour les scénarios plus complexes, les modèles Bedrock (FMs) apportent la logique personnalisée nécessaire. Source
- Distribution via GitHub, avec la possibilité de mettre à jour la pile vers la version la plus récente et de construire à partir du code si des ajustements sont nécessaires. Le projet adopte une approche pilotée par la configuration pour prompts, templates et règles sans changer l’infrastructure. Source
- Pattern-1 représente le flux de travail par défaut Bedrock Data Automation, et l’article évoque l’ajout futur de nouveaux patterns pour répondre à d’autres besoins réels. L’architecture est illustrée par le pattern par défaut et les connections entre composants dans la pile AWS. Source Détails de déploiement et opération :
- Prérequis : un compte AWS avec des permissions administratives et l’accès aux modèles Bedrock (y compris Anthropic lorsque pertinent). Consultez les conditions d’accès aux modèles Bedrock. Source
- Déploiement via AWS CloudFormation : le template déploie les ressources nécessaires; après déploiement, vous recevez un e-mail avec les identifiants pour l’interface web. Le délai est d’environ 15–20 minutes.
- Flux de production : en production, les documents sont chargés dans un bucket S3 d’entrée pour déclencher automatiquement le traitement; il existe des méthodes de test sans l’UI et des instructions pour mettre à jour la pile vers la version la plus récente. Source
- Extensibilité : vous pouvez reconstruire à partir du code pour étendre le support à d’autres régions ou apporter des modifications. Des plans prévoient le support du CDK AWS et Terraform à l’avenir. Suivez le répertoire GitHub pour les mises à jour et participez à la communauté pour contribuer. Source Exemples et résultats concrets mentionnés : Competiscan traite un grand volume de campagnes et Ricoh transforme le traitement de documents de santé, démontrant l’utilité dans des environnements à fort volume et à documents sensibles. Source
Points à retenir
- GenAI IDP Accelerator offre une approche éprouvée, prête pour la production, pour automatiser la transformation de documents non structurés avec l’IA générative sur AWS.
- La solution est modulaire, sans serveur et configurable, permettant d’ajuster rapidement prompts, règles et templates sans toucher à l’infrastructure.
- Bedrock Data Automation gère le traitement de documents prêt à l’emploi, tandis que Bedrock FMs fournissent une logique personnalisée pour les cas plus complexes.
- Le déploiement est simplifié via CloudFormation, avec une fenêtre de provisionnement de 15–20 minutes et une tarification par page évolutive.
- Des cas réels montrent le potentiel de substituer la saisie manuelle par des extractions structurées précises à grande échelle. Source
FAQ
Références
More news

Faire passer vos agents IA du concept à la production avec Amazon Bedrock AgentCore
Une exploration détaillée de la façon dont Amazon Bedrock AgentCore aide à faire passer des applications IA basées sur des agents du proof of concept à des systèmes de production de niveau entreprise, en préservant mémoire, sécurité, observabilité et gestion d’outils à l’échelle.

Scaleway rejoint les Fournisseurs d’Inference de Hugging Face pour une Inférence Serverless et Faible Latence
Scaleway est désormais un Fournisseur d’Inference pris en charge sur Hugging Face Hub, permettant l’inférence serverless directement sur les pages de modèles avec les SDK JS et Python. Accédez à des modèles open-weight populaires et bénéficiez d’une latence réduite.

Prévoir les phénomènes météorologiques extrêmes en quelques minutes sans superordinateur : Huge Ensembles (HENS)
NVIDIA et le Lawrence Berkeley National Laboratory présentent Huge Ensembles (HENS), un outil IA open source qui prévoit des événements météorologiques rares et à fort impact sur 27 000 années de données, avec des options open source ou prêtes à l’emploi.

Surveiller l’inférence par lot Bedrock d’AWS via les métriques CloudWatch
Apprenez à surveiller et optimiser les jobs d’inférence par lot Bedrock via CloudWatch, with alertes et tableaux de bord pour améliorer les performances, les coûts et l’exploitation.

Prompting pour la précision avec Stability AI Image Services sur Amazon Bedrock
Bedrock intègre Stability AI Image Services avec neuf outils pour créer et modifier des images avec précision. Apprenez les techniques de prompting adaptées à l’entreprise.

Utiliser les AWS Deep Learning Containers avec SageMaker AI géré MLflow
Découvrez comment les AWS Deep Learning Containers (DLCs) s’intègrent à SageMaker AI géré par MLflow pour équilibrer le contrôle de l’infrastructure et une gouvernance ML robuste. Un flux TensorFlow pour la prédiction de l’âge des abalones illustre le suivi de bout en bout et la traçabilité des modè