Le 'Super Weight' : comment un seul paramètre peut déterminer le comportement d'un grand modèle de langage
Sources: https://machinelearning.apple.com/research/the-super-weight
TL;DR
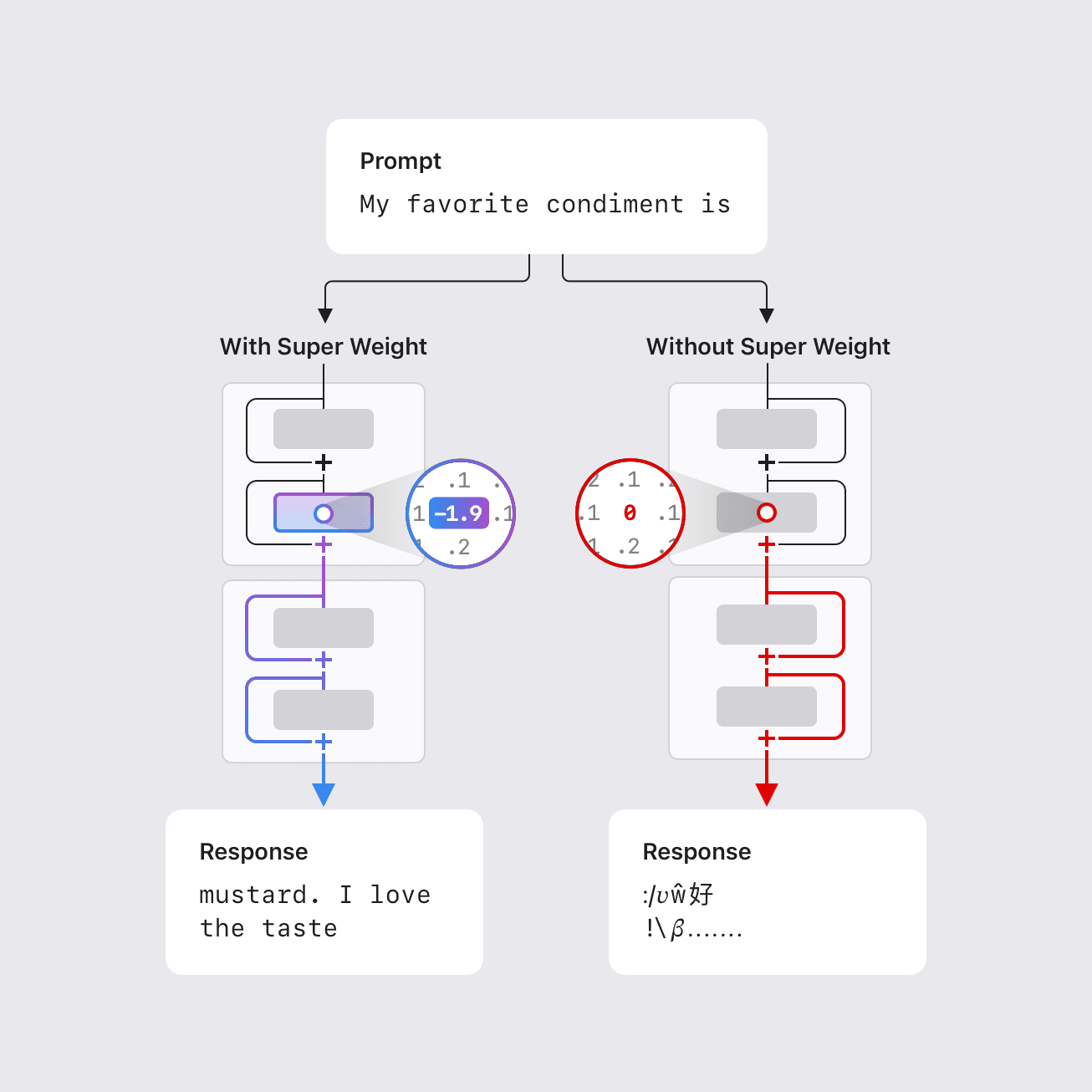
- Un très petit sous-ensemble de paramètres des LLM, appelé « super weights », peut influencer de manière disproportionnée le comportement du modèle.
- Dans certains cas, la suppression d’un seul super weight peut détruire la capacité du modèle à générer un texte cohérent, provoquant une augmentation de perplexité de trois ordres de grandeur et abaissant l’exactitude zéro-shot à des niveaux de devinette aléatoire.
- Les super weights induisent des « super activations » correspondantes qui persistent à travers les couches et influencent les sorties du modèle de manière globale; la suppression du poids élimine cet effet.
- Une méthode en une passe permet de localiser ces poids en détectant des valeurs aberrantes d’activation rares et importantes (super activations) qui s’alignent avec le canal du super weight, typiquement après le bloc d’attention dans la projection descendante du réseau feed-forward.
- Un index de coordonnées de super weights a été compilé pour plusieurs LLMs ouverts afin de faciliter les recherches futures; par exemple, des coordonnées pour Llama-7B sont fournies.\n
Contexte et arrière-plan
Les grands modèles de langage comportent des milliards, voire des centaines de milliards de paramètres, rendant difficile leur déploiement sur du matériel aux ressources limitées comme les appareils mobiles. Réduire la taille et la complexité des calculs est essentiel pour un usage local et privé sans connexion Internet. Des travaux antérieurs montrent qu’une petite fraction de poids outliers peut être vitale pour maintenir la qualité: cette fraction peut être aussi faible que 0,01% des poids. Le travail d’Apple identifie un ensemble remarquablement petit de paramètres, appelés « super weights », dont la modification peut détruire la capacité d’un LLM à générer du texte cohérent. Par exemple, dans le modèle Llama-7B, la suppression d’un seul super weight empêche le modèle de produire une sortie significative. À l’inverse, la suppression de milliers d’autres outliers — même s’ils sont plus grands en magnitude — entraîne seulement une dégradation modeste de la qualité. Le travail propose une méthode pour localiser ces super weights en une seule passe, en s’appuyant sur l’observation que les super weights induisent des activations rares et importantes (super activations) qui persistent à travers les couches et s’alignent sur le canal du poids. Le poids super se trouve généralement dans la projection descendante du réseau feed-forward après le bloc d’attention, souvent dans une couche précoce. Un index de coordonnées a été compilé pour plusieurs modèles ouverts courants afin de faciliter les investigations de la communauté.\n
Ce qu’il y a de nouveau
Les chercheurs d’Apple identifient un phénomène encore peu exploité: un nombre extrêmement petit de paramètres peut guider le comportement d’un LLM. Les conclusions clés incluent:
- L’existence de « super weights » dont la modification peut dégrader gravement la qualité de génération; dans certains cas, un seul paramètre suffit pour interrompre le fonctionnement.
- Le concept de « super activations » : des activations grandes et rares qui apparaissent après le super weight et persistent à travers les couches avec une position et une magnitude constantes, en ligne avec le canal du poids.
- Une approche pratique de détection nécessitant une seule passe pour trouver ces poids en repérant des pics dans les distributions d’activation au niveau de composants spécifiques, notamment la projection descendante du réseau feed-forward après le bloc d’attention.
- Les emplacements sont cohérents entre modèles: le super weight se situe dans la projection descendante après l’attention, typiquement dans une couche précoce. Un exemple explicite est donné pour Llama-7B sur HuggingFace: accéder au super weight via layers[2].mlp.down_proj.weight[3968, 7003]. L’étude fournit aussi un index de coordonnées pour plusieurs modèles.\n
Pourquoi c’est important (impact pour les développeurs/entreprises)
Comprendre et identifier les super weights a des implications pratiques pour la compression:
- La préservation des super activations avec une haute précision peut permettre une quantification simple tout en conservant une qualité élevée.
- Pour la quantification des poids, préserver le super weight tout en tronquant d’autres outliers peut permettre des tailles de blocs de quantification plus grandes et efficaces, menant à de meilleures ratios de compression.
- Cette approche ciblée offre une voie adaptée au matériel pour faire fonctionner des LLMs puissants sur des appareils à ressources limitées, tout en maintenant une qualité plus élevée que les stratégies de suppression générales.
- La découverte ouvre aussi des questions sur la conception et l’entraînement, suggérant que certains outliers peuvent influencer les sorties sémantiques et que leur préservation est critique pendant la compression. Un répertoire de super weights est mis à disposition pour encourager l’exploration continue.\n
Détails techniques ou Implémentation
Les points clefs:
- Les super weights constituent un sous-ensemble extrêmement restreint de paramètres qui exercent une influence disproportionnée sur le comportement du modèle.
- Les super activations sont des activations grandes et rares apparaissant après le super weight et persistant à travers les couches, alignées sur le canal du poids et conservant leur magnitude dans les connexions résiduelles.
- La méthode proposée nécessite une seule passe et s’appuie sur des pics dans les distributions d’activation dans des composants spécifiques, notamment la projection descendante du réseau feed-forward après le bloc d’attention, pour localiser le super weight et son activation correspondante.
- Les schémas de localisation sont robustes à travers les modèles: le poids super se situe dans la projection descendante après l’attention, généralement à une couche précoce.\n | Modèle (exemple) | Coordonnée du poids super (échantillon) |--- |--- |Llama-7B (HuggingFace) | layers[2].mlp.down_proj.weight[3968, 7003] |
Points clés à retenir
- Un ensemble extrêmement petit de paramètres peut piloter le comportement d’un LLM, et leur suppression peut avoir des effets dramatiques.
- Les concepts de “super weights” et de “super activations” offrent une perspective utile sur la dynamique interne des LLM et ont des implications pratiques pour la compression.
- Une approche pratique en une passe permet de localiser ces poids via les pics d’activation, facilitant la préservation ciblée lors de la quantification et de la suppression.
- Un index officiel de coordonnées pour des modèles bien connus est fourni pour encourager des validations et des expériences communautaires.\n
FAQ
Références
More news

Comment réduire les goulots d’étranglement KV Cache avec NVIDIA Dynamo
NVIDIA Dynamo déporte le KV Cache depuis la mémoire GPU vers un stockage économique, permettant des contextes plus longs, une meilleure concurrence et des coûts d’inférence réduits pour les grands modèles et les charges AI génératives.

Réduire la latence de démarrage à froid pour l’inférence LLM avec NVIDIA Run:ai Model Streamer
Analyse approfondie sur la façon dont NVIDIA Run:ai Model Streamer abaisse les temps de démarrage à froid pour l’inférence des LLM en diffusant les poids vers la mémoire GPU, avec des benchmarks sur GP3, IO2 et S3.

Simplifier l accès aux changements de contenu ISO-rating avec Verisk Rating Insights et Amazon Bedrock
Verisk Rating Insights, propulsé par Amazon Bedrock, LLM et RAG, offre une interface conversationnelle pour accéder aux changements ERC ISO, réduisant les téléchargements manuels et accélérant les informations fiables.

Comment msg a renforcé la transformation RH avec Amazon Bedrock et msg.ProfileMap
Cet article explique comment msg a automatisé l'harmonisation des données pour msg.ProfileMap en utilisant Amazon Bedrock pour alimenter des flux d'enrichissement pilotés par LLM, améliorant la précision de l'appariement des concepts RH, réduisant la charge manuelle et assurant la conformité avec l'

Automatiser des pipelines RAG avancés avec Amazon SageMaker AI
Optimisez l’expérimentation jusqu’à la production pour le RAG (Retrieval Augmented Generation) avec SageMaker AI, MLflow et Pipelines, afin d’obtenir des flux reproductibles, évolutifs et gouvernés.

Déployer une inférence IA scalable avec NVIDIA NIM Operator 3.0.0
NVIDIA NIM Operator 3.0.0 étend l’inférence IA scalable sur Kubernetes, avec déploiements multi-LLM et multi-nœud, intégration KServe et support DRA en version technologique, en collaboration avec Red Hat et NeMo Guardrails.