Infosys Topaz utilise Amazon Bedrock pour transformer les opérations du help desk technique
TL;DR
- Infosys Topaz s’appuie sur Amazon Bedrock pour alimenter un help desk technique basé sur l’IA générative pour un grand fournisseur d’énergie. AWS blog
- Le système ingère des transcriptions passées et nouvelles, construit une base de connaissances et utilise la génération avec récupération (RAG) pour fournir des résolutions, réduisant le temps de recherche manuel.
- La sécurité des données et les contrôles d’accès reposent sur les services AWS tels que IAM, KMS, Secrets Manager, TLS, CloudTrail et OpenSearch Serverless avec contrôle d’accès basé sur les rôles.
- L’architecture s’appuie sur AWS Step Functions, Lambda, S3, DynamoDB, et une interface Streamlit pour offrir une expérience en production avec traçabilité du temps et métriques de QoS.
Contexte et antécédents
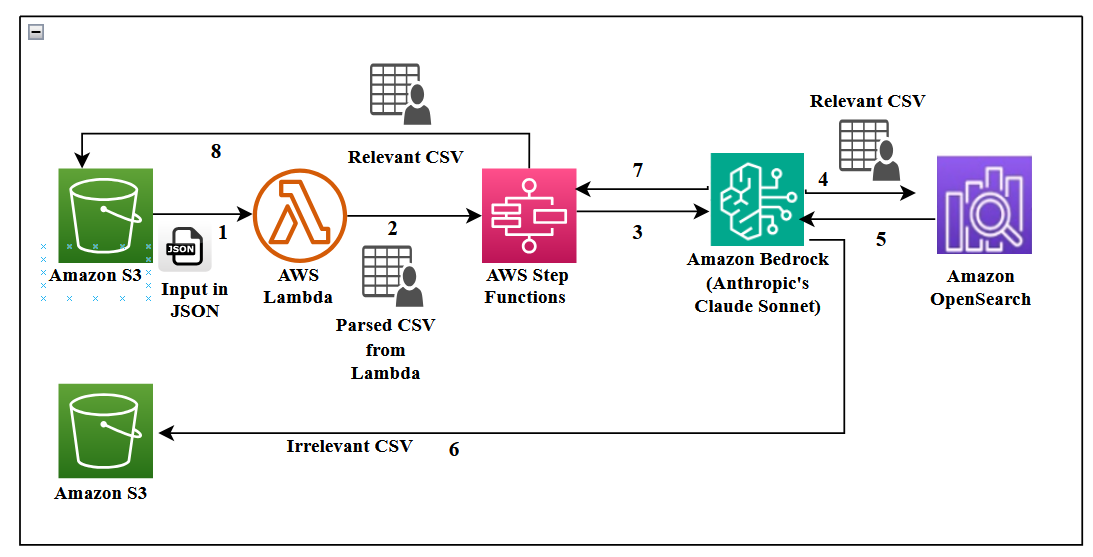
Un important fournisseur d’énergie s’appuie sur un help desk technique où les agents répondent aux appels des clients et assistent des techniciens de terrain qui installent, échangent, entretiennent et réparent des compteurs. Le volume est conséquent: environ 5 000 appels par semaine (environ 20 000 par mois). Recruter davantage d’agents et les former avec les connaissances requises est coûteux et difficile à scaler. Pour remédier à cela, Infosys Topaz s’intègre aux capacités d’AWS Bedrock pour créer un help desk piloté par l’IA qui ingère des transcriptions, construit une base de connaissances consultable et propose des résolutions quasi en temps réel. L’objectif est de réduire le temps d’accueil, d’automatiser les tâches répétitives et d’améliorer la qualité du support. L’architecture met en évidence une intégration serrée avec les services AWS pour le flux et la gestion des données dans un unique cloud, incluant Step Functions, DynamoDB et OpenSearch Service. AWS blog Les conversations sont enregistrées à des fins de qualité et d’analyse. Les transcriptions sont stockées en JSON dans un seau S3, puis analysées pour créer une base de connaissances consultable par l’IA. L’importance du contrôle d’accès basé sur les rôles et le traitement sûr des données, notamment des données PII, est mise en évidence. L’architecture illustre un flux de bout en bout des transcriptions brutes à une interface interactive utilisée par les agents. L’approche couvre également des métriques telles que le sentiment, le ton et la satisfaction.
Nouveautés
L’implémentation associe Infosys Topaz à Amazon Bedrock, en incluant Claude Sonnet d’Anthropic comme modèle de langage pour la synthèse et l’évaluation du contexte. Titan Text Embeddings sur Bedrock alimente une recherche vectorielle efficace pour le flux RAG via un store vectoriel OpenSearch Serverless. Les choix de conception clés comprennent le découpage des transcriptions en blocs de 1 000 tokens avec une fenêtre de recouvrement de 150–200 tokens pour améliorer la qualité des résultats. Un événement Lambda déclenche le flux Step Functions lorsque de nouvelles transcriptions sont chargées dans S3. Les transcriptions brutes sont converties en CSV pour filtrage (champs: identifiant unique du contact, intervenant et contenu). Le pipeline alimente les embeddings dans OpenSearch Serverless pour la récupération. OpenSearch Serverless offre un stockage vectoriel évolutif et des recherches performantes, avec la possibilité d’ajouter, mettre à jour et supprimer des embeddings presque en temps réel. Le système s’appuie sur une configuration RAG prête pour la production, avec un stockage vectoriel robuste et des modèles d embeddings adaptés pour récupérer les informations les plus pertinentes contextuellement. Du côté sécurité, Secrets Manager protège les identifiants, KMS assure le chiffrement au repos et TLS 1.2 les communications; CloudTrail assure l’audit. L’accès est géré par des politiques IAM et une architecture RBAC qui utilise trois personas: administrateur (accès total), analyste technique (accès moyen) et agent technique (accès minimal). Des collections OpenSearch Serverless distinctes permettent de contrôler le niveau d’accès par type de transcription. L’interface Streamlit fournit une UI avec une section FAQ et un panneau de métriques de recherche. L’authentification via authenticate.login assigne l’ID utilisateur et st.cache_data() met en cache les résultats entre les sessions.
Pourquoi c’est important (impact pour les développeurs/entreprises)
Cette solution montre comment opérationnaliser une IA générative qui complète les agents humains plutôt que de les remplacer. En construisant une base de connaissances à partir de transcriptions réelles et en utilisant une recherche vectorielle robuste (RAG), les organisations peuvent réduire le temps d’accueil, standardiser les résolutions et dimensionner le support sans augmenter proportionnellement le personnel. L’architecture démontre comment Bedrock s’intègre aux services AWS de base pour offrir un flux de données complet, une gouvernance de données sécurisée et une traçabilité. Pour les entreprises, ce modèle propose des étapes concrètes pour déployer des assistants IA en entreprise dans le support client, le CRM et les help desks tout en respectant les exigences de conformité et de sécurité.
Détails techniques ou mise en œuvre
Le flux commence par des transcriptions d’appels enregistrées par les agents et les techniciens. Les transcriptions sont stockées dans S3 au format JSON, puis analysées pour générer un CSV structuré avec des champs tels que l’ID du contact, le rôle du participant et le contenu de la conversation. Step Functions orchestre le flux d’ingestion qui convertit les transcriptions brutes en une base de connaissances prête à l’emploi. La couche embedding et récupération utilise Titan Text Embeddings pour vectoriser le texte et OpenSearch Serverless pour le stockage et la recherche vectorielle, permettant une récupération avec génération (RAG) via Claude Sonnet sur Bedrock pour résumer les conversations et identifier les informations pertinentes. La stratégie de découpage utilise des blocs de 1 000 tokens avec 150–200 tokens de recouvrement, associée à une récupération par fenêtre de phrases afin d’améliorer la qualité sans traiter des documents volumineux en une seule fois. L’interface Streamlit sert de frontend, avec une authentification simple (authenticate.login) pour attribuer l’ID utilisateur. L’interface présente une section FAQ et un panneau de métriques de recherche (sentiment, ton, satisfaction). Les résultats sont mis en cache via st.cache_data() pour accélérer les réponses entre les sessions. Sur le plan sécurité, Secrets Manager protège les identifiants, KMS assure le chiffrement au repos, TLS 1.2 protège les données en transit et CloudTrail assure l’audit. L’accès est contrôlé par des politiques IAM et une gestion RBAC avec des collections OpenSearch Serverless distinctes. Trois personas définissent les niveaux d’accès: administrateur, analyste technique de bureau et agent technique. Cette approche garantit que seules les personnes autorisées accèdent au contenu sensible, tout en permettant un flux de travail efficace pour le support.
Conclusions clés
- L’IA appliquée au help desk est faisable lorsque soutenue par une ingestion et une récupération bien conçues.
- Claude Sonnet sur Bedrock et Titan Embeddings permettent une récupération contextuelle efficace sur des transcripts opérationnels.
- La sécurité, le chiffrement et la gouvernance auditable sont essentiels pour gérer les données clients et les PII dans des applications d’IA d’entreprise.
- Une architecture intégrant Step Functions, Lambda, S3 et OpenSearch Serverless offre une évolutivité adaptée à la production.
- Le RBAC avec trois personas assure une protection des données sensibles tout en permettant des flux de support efficaces.
FAQ
Références
More news

NVIDIA HGX B200 réduit l’intensité des émissions de carbone incorporé
Le HGX B200 de NVIDIA abaisse l’intensité des émissions de carbone incorporé de 24% par rapport au HGX H100, tout en offrant de meilleures performances IA et une efficacité énergétique accrue. Cet article résume les données PCF et les nouveautés matérielles.

Faire passer vos agents IA du concept à la production avec Amazon Bedrock AgentCore
Une exploration détaillée de la façon dont Amazon Bedrock AgentCore aide à faire passer des applications IA basées sur des agents du proof of concept à des systèmes de production de niveau entreprise, en préservant mémoire, sécurité, observabilité et gestion d’outils à l’échelle.

Surveiller l’inférence par lot Bedrock d’AWS via les métriques CloudWatch
Apprenez à surveiller et optimiser les jobs d’inférence par lot Bedrock via CloudWatch, with alertes et tableaux de bord pour améliorer les performances, les coûts et l’exploitation.

Prompting pour la précision avec Stability AI Image Services sur Amazon Bedrock
Bedrock intègre Stability AI Image Services avec neuf outils pour créer et modifier des images avec précision. Apprenez les techniques de prompting adaptées à l’entreprise.

Utiliser les AWS Deep Learning Containers avec SageMaker AI géré MLflow
Découvrez comment les AWS Deep Learning Containers (DLCs) s’intègrent à SageMaker AI géré par MLflow pour équilibrer le contrôle de l’infrastructure et une gouvernance ML robuste. Un flux TensorFlow pour la prédiction de l’âge des abalones illustre le suivi de bout en bout et la traçabilité des modè

Évoluer la production visuelle avec Stability AI Image Services dans Amazon Bedrock
Stability AI Image Services est désormais disponible dans Amazon Bedrock, offrant des capacités d’édition d’images prêtes à l’emploi via l’API Bedrock et étendant les modèles Stable Diffusion 3.5 et Stable Image Core/Ultra déjà présents.