
Sam Altman sur le fiasco du lancement GPT‑5, les data centers, Chrome et les interfaces neuronales
TL;DR
- Sam Altman a admis qu’OpenAI a “plutôt foiré” certains aspects du lancement de GPT‑5 et a rétabli la “chaleur” du modèle 4o après la réaction des utilisateurs.
- Le trafic API a doublé en 48 heures, OpenAI manque de GPU et Altman a déclaré que la société devra investir des billions de dollars dans des centres de données.
- Altman a confirmé un projet de financement d’une startup d’interface cerveau‑ordinateur et a exprimé des ambitions pour des applications autonomes, des expériences sociales et la possibilité de regarder Chrome s’il était vendu.
Contexte et arrière‑plan
Lors d’un dîner à San Francisco, Sam Altman et plusieurs dirigeants d’OpenAI ont répondu aux questions d’un petit groupe de journalistes. Tout a été « on the record » à l’exception des échanges tenus pendant le dessert. Les sujets abordés ont couvert le récent lancement de GPT‑5, les réactions des utilisateurs, la posture produit, les contraintes d’infrastructure et des mouvements stratégiques éventuels tels qu’un intérêt pour Chrome si Google devait le vendre. Altman a rappelé la croissance rapide de ChatGPT : le produit aurait “grossi d’environ quatre fois” en un an et atteint “plus de 700 millions de personnes chaque semaine”, plaçant ChatGPT parmi les sites les plus visités au monde — un élément central pour comprendre les décisions opérationnelles évoquées.
Quoi de neuf
- Réponse au déploiement : Environ une heure avant le dîner, OpenAI a publié une mise à jour pour réintroduire la “chaleur” du modèle 4o (ancien défaut) comme option pour les abonnés payants. Altman a déclaré qu’il a pris la décision après des protestations sur Reddit et X.
- Trafic et capacité : Altman a indiqué que le trafic API a doublé en 48 heures suite au déploiement et que l’entreprise est “à court de GPU” tandis que ChatGPT enregistre de nouveaux records quotidiens d’utilisateurs.
- Investissements et infrastructure : Altman a dit : “Vous devez vous attendre à ce qu’OpenAI dépense des billions de dollars en construction de centres de données dans un avenir pas très lointain.”
- Nouveaux paris techniques : Il a confirmé que la société envisage de financer une startup d’interface neuronale pour explorer la possibilité de penser quelque chose et voir ChatGPT y répondre.
- Portée produit : L’arrivée de Fidji Simo pour diriger les “applications” implique des applications autonomes en plus de ChatGPT. Altman a aussi évoqué des ambitions sociales et un intérêt pour Chrome si celui‑ci devait être vendu.
- Position publique : Altman a reconnu que l’entreprise tient de nombreuses réunions sur les utilisateurs développant des relations malsaines avec ChatGPT, qu’il estime être “bien en dessous de 1 %”. Il a ajouté qu’OpenAI n’ira pas vers des usages exploitants (mentionnant des « anime sex bots ») et souhaite que le produit reste « centre‑route » mais personnalisable.
Pourquoi c’est important (impact pour développeurs / entreprises)
- Les contraintes de capacité influent sur la disponibilité des fonctionnalités et les calendriers de déploiement. Les entreprises utilisant les API d’OpenAI doivent s’attendre à une variabilité d’accès ou à des limitations jusqu’à l’augmentation des ressources GPU.
- L’annonce d’investissements massifs pour les centres de données indique une volonté de montée en échelle durable, mais implique aussi des effets sur la tarification et les contrats à long terme.
- La confirmation du financement d’interfaces neuronales suggère de nouvelles modalités d’entrée potentielles; développeurs et partenaires matériels devront suivre l’évolution des API et standards.
- Le développement d’applications autonomes et d’expériences sociales implique des surfaces produit supplémentaires à intégrer, avec de possibles SDKs, nouvelles interfaces et exigences de conformité.
Détails techniques ou mise en œuvre
Voici un tableau synthétique des éléments techniques et opérationnels évoqués par Altman :
| Sujet | Fait / Citation |
|---|---|
| Rétablissement du modèle | OpenAI a rétabli la “chaleur” du 4o comme option pour les abonnés payants; Altman a indiqué qu’il a pris la décision après les critiques. |
| Pic de trafic | Le trafic API a doublé en 48 heures après le déploiement de GPT‑5. |
| Capacité | OpenAI est “à court de GPU” et bat des records d’utilisateurs quotidiens. |
| Dépenses data center | Altman : “Vous devriez vous attendre à ce qu’OpenAI dépense des billions de dollars…” |
| Interfaces neurales | Altman a confirmé le projet de financement d’une startup d’interface neuronale. |
| Portée produit | Fidji Simo en charge des “applications” implique des apps autonomes; Altman discute aussi d’ambitions sociales et du Chrome possible. |
| Conséquences opérationnelles : |
- Attendre des limitations basées sur la capacité jusqu’à l’arrivée de nouvelles ressources GPU.
- Se préparer à de nouveaux endpoints et exigences de sécurité si des interfaces neurales sont développées.
- Surveiller les annonces de tarification et de quotas en lien avec des investissements massifs en infrastructure.
Principaux enseignements
- OpenAI a reconnu des erreurs de déploiement et a restauré le modèle 4o.
- La demande a explosé et l’entreprise fait face à des contraintes GPU.
- Altman prévoit des investissements massifs en centres de données pour résoudre ces problèmes.
- OpenAI explore les interfaces cerveau‑ordinateur et financera des startups dans ce domaine.
- L’entreprise souhaite aller au‑delà du ChatGPT avec des applications autonomes et des expériences sociales.
FAQ
Références
- Article original : The Verge — I talked to Sam Altman about the GPT‑5 launch fiasco: https://www.theverge.com/command-line-newsletter/759897/sam-altman-chatgpt-openai-social-media-google-chrome-interview
More news

Anthropic renforce les règles d'utilisation de Claude face à un paysage IA plus dangereux
Anthropic interdit l'aide à la création d'armes CBRN et d'explosifs puissants, ajoute des interdictions cybersécurité, précise le contenu politique et clarifie les usages à haut risque.

Build a scalable containerized web application on AWS using the MERN stack with Amazon Q Developer – Part 1
In a traditional SDLC, a lot of time is spent in the different phases researching approaches that can deliver on requirements: iterating over design changes, writing, testing and reviewing code, and configuring infrastructure. In this post, you learned about the experience and saw productivity gains
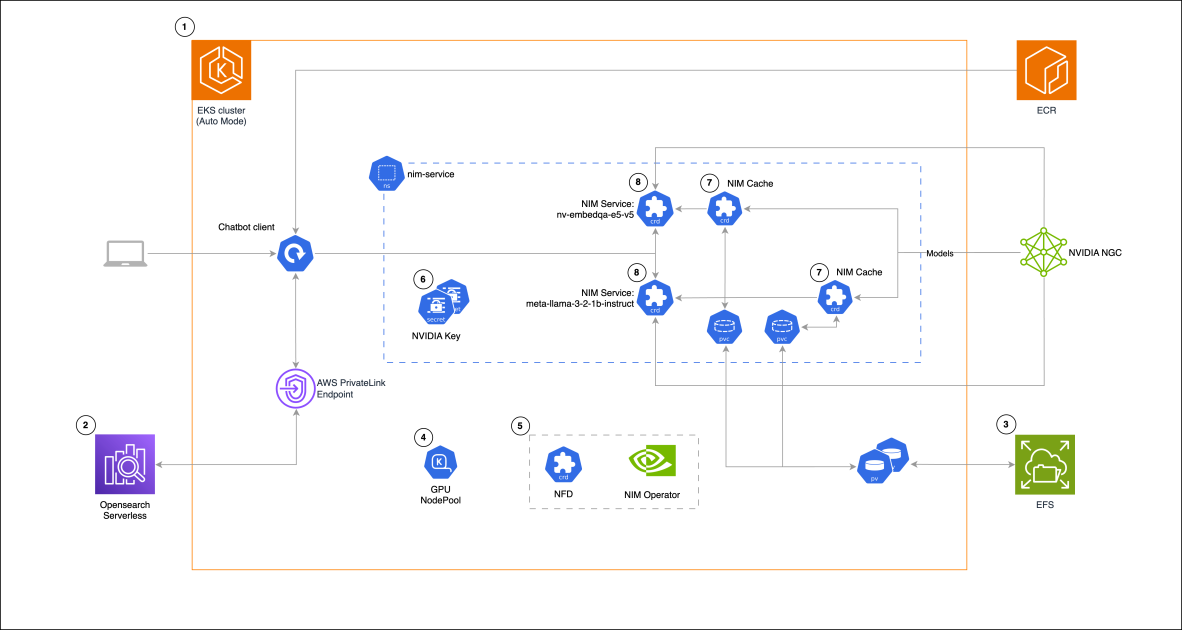
Building a RAG chat-based assistant on Amazon EKS Auto Mode and NVIDIA NIMs
In this post, we demonstrate the implementation of a practical RAG chat-based assistant using a comprehensive stack of modern technologies. The solution uses NVIDIA NIMs for both LLM inference and text embedding services, with the NIM Operator handling their deployment and management. The architectu

GPT-5 a déçu les attentes élevées mais améliore coût, rapidité et codage
Le lancement de GPT-5 a suscité des réactions mitigées : progrès incrémentaux aux benchmarks, coût et latence réduits, meilleure performance en codage, mais critiques sur le ton rédactionnel et des erreurs inattendues.

Introducing Amazon Bedrock AgentCore Gateway: Transforming enterprise AI agent tool development
In this post, we discuss Amazon Bedrock AgentCore Gateway, a fully managed service that revolutionizes how enterprises connect AI agents with tools and services by providing a centralized tool server with unified interface for agent-tool communication. The service offers key capabilities including S
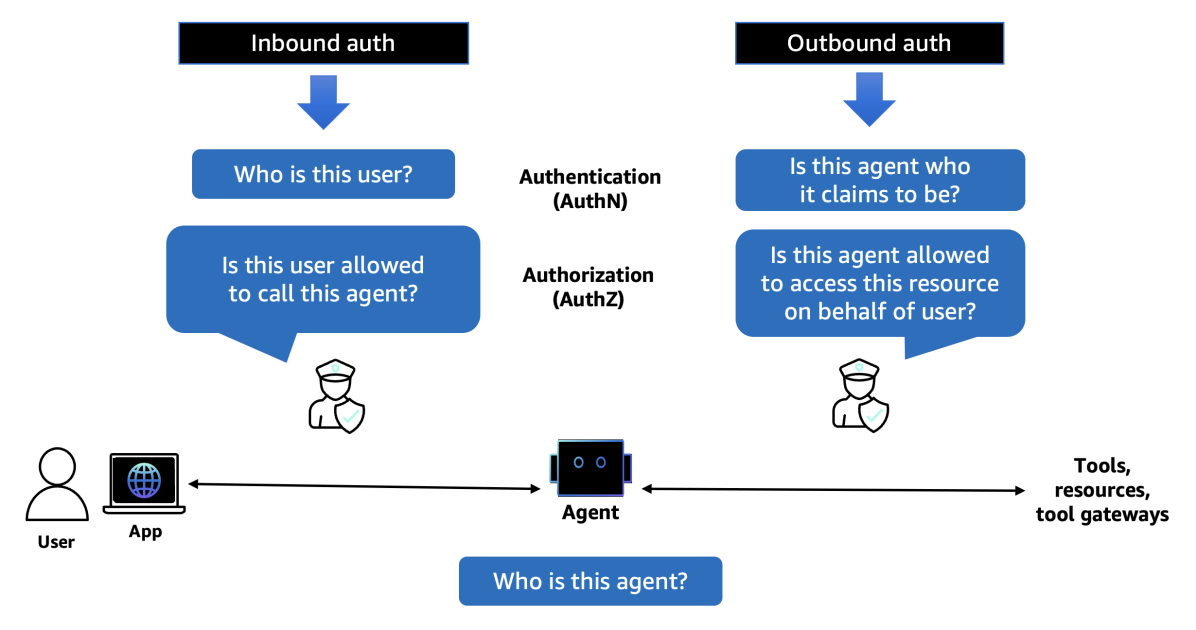
Introducing Amazon Bedrock AgentCore Identity: Securing agentic AI at scale
In this post, we explore Amazon Bedrock AgentCore Identity, a comprehensive identity and access management service purpose-built for AI agents that enables secure access to AWS resources and third-party tools. The service provides robust identity management features including agent identity director