
La détection d’accent tonique améliore la reconnaissance vocale pré-entraînée
Sources: https://machinelearning.apple.com/research/pitch-accent, machinelearning.apple.com
TL;DR
- Un modèle conjoint de Reconnaissance Automatique de la Parole (ASR) et de détection d’accent tonique améliore les performances des systèmes de parole pré-entraînés.
- La détection d’accent tonique atteint une amélioration significative de l’état de l’art, comblant l’écart du F1-score de 41%.
- Les performances ASR lors de l’entraînement conjoint diminuent le WER de 28,3% sur LibriSpeech en cas de finetuning avec ressources limitées.
- Le travail souligne l’importance d’étendre les modèles de parole pré-entraînés pour préserver ou réapprendre les indices prosodiques tels que l’accent tonique.
Contexte et arrière-plan
La reconnaissance vocale automatique bénéficie des représentations vocales semi-supervisées utilisant de grands volumes de données non étiquetées pour améliorer les tâches en aval. L’étude explore si un module complémentaire de détection d’accent tonique, intégré à un ASR dans un modèle commun, peut renforcer les performances en réapprenant et en préservant les indices prosodiques souvent sous-représentés dans les modèles pré-entraînés. Les auteurs décrivent un modèle conjoint ASR et détection d’accent tonique dont la composante d’accent tonique obtient une amélioration substantielle par rapport à l’état de l’art, en comblant l’écart du F1-score de 41%. Par ailleurs, l’entraînement conjoint résulte en une amélioration notable pour l’ASR: lors d’un finetuning à ressources limitées sur LibriSpeech, le WER diminue de 28,3%. Ces résultats mettent en évidence l’importance d’intégrer explicitement des signaux prosodiques — tels que l’accent tonique — dans les modèles vocaux pré-entraînés pour améliorer la reconnaissance en aval. L’article, rédigé par David Sasu et Natalie Schluter, s’inscrit dans les efforts de recherche d’Apple et est lié à des conférences telles que Interspeech et ICASSP, autour du traitement du discours et du langage. Cette approche s’inscrit dans une ligne de recherche plus générale visant à aller au-delà des seules caractéristiques spectrales et des indices textuels, en réintégrant des informations prosodiques dans des modèles de pointe. Pour accéder à la source principale, Apple présente une page de recherche dédiée à la détection d’accent tonique: https://machinelearning.apple.com/research/pitch-accent.
Ce qu’il y a de nouveau
L’apport central est un modèle qui combine ASR et détection d’accent tonique, entraîné pour optimiser simultanément la décodification lexicale et l’étiquetage prosodique. Les résultats clés indiquent:
- Le détecteur d’accent tonique atteint une amélioration significative par rapport à l’état de l’art pour la détection de l’accent tonique, comblant l’écart du F1-score de 41%.
- Le système ASR, entraîné dans le cadre conjoint, montre une réduction de 28,3% du WER sur LibriSpeech lors d’un finetuning à ressources limitées, démontrant une meilleure généralisation avec des données étiquetées restreintes.
- Ces résultats soulignent l’importance de préserver ou de réapprendre des signaux prosodiques tels que l’accent tonique pendant le préentraînement et le finetuning, afin d’améliorer la reconnaissance downstream.
Points techniques
- Le cadre intègre une branche de détection d’accent tonique avec un backbone ASR, permettant une optimisation conjointe pour le décodage lexical et l’étiquetage prosodique.
- L’amélioration de 41% du F1-score en détection d’accent tonique indique une concordance accrue avec les jugements humains sur la présence et l’emplacement de l’accent tonique.
- En termes d’ASR, le modèle conjoint réduit le WER de 28,3% sur LibriSpeech en finetuning à ressources limitées, démontrant une meilleure efficacité des données.
- Le travail met en exergue l’importance d’étendre les représentations de parole pré-entraînées pour préserver ou réapprendre des indices prosodiques, suggérant des directions futures sur la robustesse inter-domaines et multilingue.
En quoi cela compte (impact pour les développeurs/entreprises)
- Pour les développeurs de produits basés sur l’ASR, intégrer un module de détection d’accent tonique dans un modèle conjoint peut conduire à des améliorations tangibles de la précision de transcription, particulièrement lorsque les données étiquetées sont limitées.
- Les entreprises déployant des interfaces vocales, des assistants ou des services de transcription peuvent bénéficier d’un WER plus faible et d’un prosodie plus naturelle dans les sorties, améliorant ainsi l’expérience utilisateur et la confiance.
- Le travail illustre le principe de conception selon lequel étendre les modèles pré-entraînés pour retenir des indices prosodiques importants peut améliorer la robustesse et la généralisabilité des systèmes de parole.
- Compte tenu des besoins en accessibilité et en support multilingue, une meilleure gestion du prosodie pourrait améliorer la lisibilité des services de parole dans des langues et dialectes où le prosodie joue un rôle plus important.
Détails techniques ou Mise en œuvre
- L’approche repose sur un cadre ASR conjoint avec une branche de détection d’accent tonique, permettant une optimisation simultanée pour le contenu lexical et l’étiquetage prosodique.
- Les améliorations rapportées incluent un gain relatif de 41% du F1-score pour la détection d’accent tonique, indiquant une correspondance plus fidèle avec les jugements humains.
- En termes d’ASR, le modèle conjoint réduit le WER de 28,3% sur LibriSpeech lors d’un finetuning à ressources limités, démontrant une meilleure efficacité des données.
- Le travail réaffirme l’importance d’étendre les modèles de parole pré-entraînés pour préserver ou réapprendre des indices prosodiques tels que l’accent tonique, suggérant des pistes futures pour explorer comment différents signaux prosodiques contribuent à la robustesse entre domaines et langues.
Mesures clés (points forts)
| Métrique | Changement | Description |---|---|---| | F1-score (Détection d’accent tonique) | +41% | Comble l’écart avec l’état de l’art |WER sur LibriSpeech (finetuning ressources limitées) | -28,3% | Amélioration avec apprentissage conjoint |
Conclusions clés
- Les modèles conjoints ASR et détection d’accent tonique peuvent améliorer à la fois l’étiquetage prosodique et la transcription.
- L’intégration explicite d’indices prosodiques aide à préserver l’information durant le pré-entraînement et le finetuning, surtout lorsque les données étiquetées sont limitées.
- Les gains rapportés sur LibriSpeech démontrent une meilleure efficacité des données pour les systèmes ASR.
- Ce travail renforce l’idée que la prosodie est un élément crucial pour des technologies de parole plus robustes et généralisables.
FAQ
-
- **Q : Qu’est-ce que la détection d’accent tonique dans ce contexte ?**
C’est une composante du modèle qui détecte des indices prosodiques, comme l’accent tonique, pour améliorer l’ASR. - **Q : De quels ordres de grandeur sont les améliorations ?** **A :** Amélioration significative du F1-score (41% de réduction de l’écart à l’état de l’art) et réduction de 28,3% du WER sur LibriSpeech en finetuning limité. - **Q : Où trouver les détails officiels ?** **A :** Les détails sont sur la page de recherche d’Apple : https://machinelearning.apple.com/research/pitch-accent.
Références
More news

Les checklists surpassent les modèles de récompense pour l’alignement des modèles de langage
Une approche RL utilisant des checklists dérivées des instructions guide l’alignement et surpasse les modèles de récompense fixes sur plusieurs benchmarks du Qwen2.5-7B-Instruct, présentée à l’ICLR 2025.

SlowFast-LLaVA-1.5 : LLMs vidéo économes en jetons pour la compréhension du long terme
La recherche ML d’Apple présente SlowFast-LLaVA-1.5 (SF-LLaVA-1.5), une famille de LLMs vidéo à faible coût en jetons pour la compréhension de vidéos longues, utilisant le mécanisme SlowFast à deux flux et des données publiques pour atteindre des performances de pointe entre 1B et 7B.
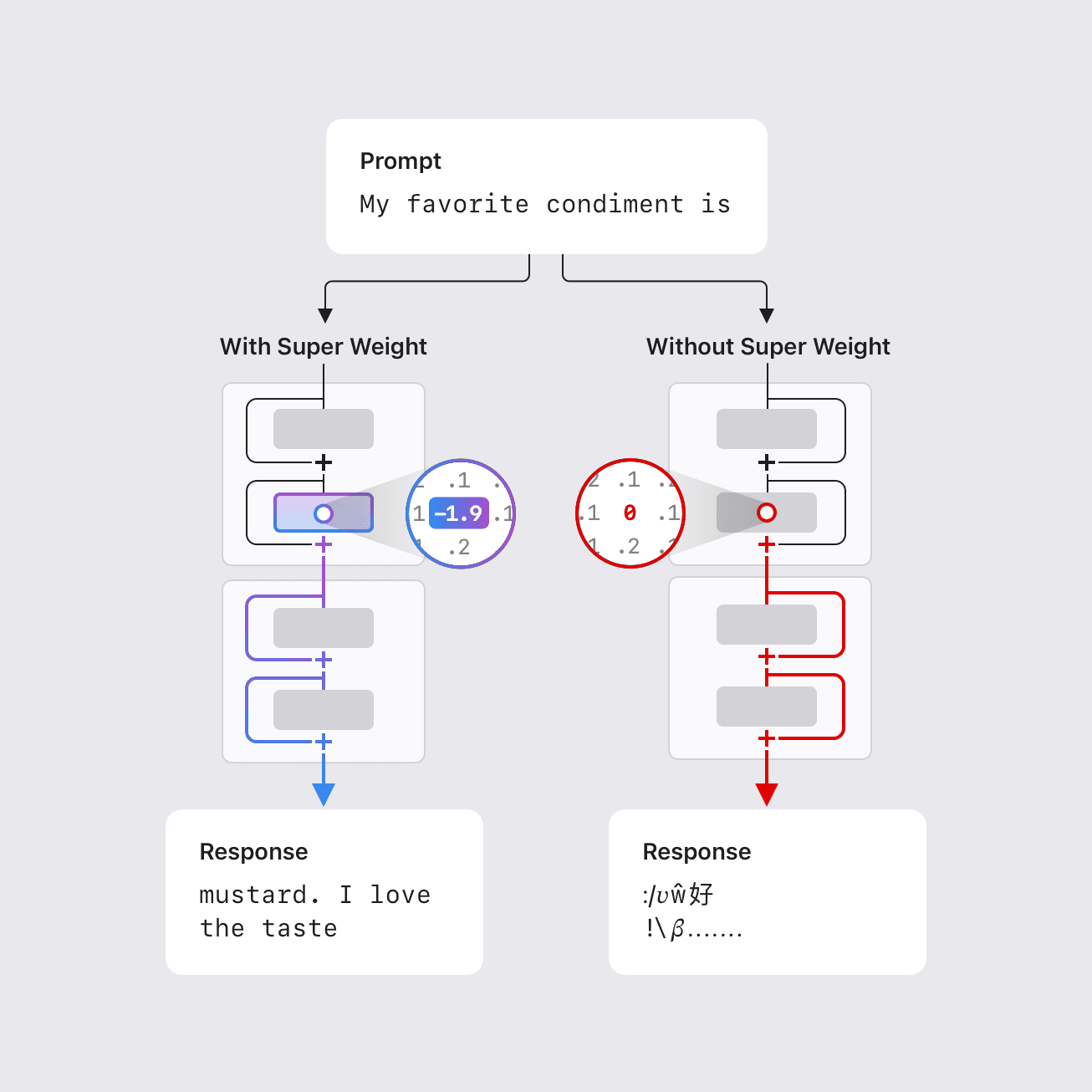
Le 'Super Weight' : comment un seul paramètre peut déterminer le comportement d'un grand modèle de langage
Des chercheurs d'Apple identifient des « super poids » — une très petite sous-ensemble de paramètres — qui peuvent influencer de manière décisive le comportement d'un LLM, ouvrant des perspectives de compression et soulevant des questions sur la dynamique interne.

Enquêter sur les biais intersectionnels dans les grands modèles de langage via des disparités de confiance en coreference
Analyse approfondie de la manifestation des biais intersectionnels dans les LLMs au moyen de disparités de confiance en coreference. Le travail présente WinoIdentity et la métrique Coreference Confidence Disparity.

Réinventer la Factorisation Non Négative par des Représentations Neurales Implicites pour des Transformées Audio Irrégulières
Des chercheurs d'Apple reformulent la Factorisation de Matrice Non Négative (NMF) sous forme de fonctions apprenables afin de l'appliquer à des représentations temps-fréquence irrégulières en audio.

Misty : prototypage UI par mélange conceptuel interactif
Misty présente un flux de travail de prototypage UI inspiré du mélange conceptuel pour intégrer rapidement des exemples de design dans des prototypes, testé avec 14 développeurs frontend lors d'une première utilisation.