Optimiser les endpoints de modèles Salesforce avec les composants d’inférence IA SageMaker
Sources: https://aws.amazon.com/blogs/machine-learning/optimizing-salesforces-model-endpoints-with-amazon-sagemaker-ai-inference-components, aws.amazon.com
TL;DR
- Salesforce a utilisé les composants d’inférence d’Amazon SageMaker AI pour déployer plusieurs modèles fondation sur un seul endpoint, avec un contrôle des ressources par modèle (accélérateurs et mémoire).
- Cette approche a amélioré l’utilisation des GPU, réduit les coûts d’infrastructure et supporte le scaling dynamique lorsque le trafic fluctue.
- Une stratégie hybride a été adoptée, combinant les endpoints SMEs traditionnels et les composants d’inférence pour équilibrer stabilité et efficacité.
- La solution a permis d’héberger efficacement l’ensemble CodeGen et d’autres modèles propriétaires tout en permettant le partage économique des GPU.
- Salesforce rapporte des réductions substantielles des coûts, notamment une réduction des coûts de déploiement et d’infrastructure allant jusqu’à huit fois.
Contexte et arrière-plan
Cette collaboration entre Salesforce et AWS est publiée conjointement sur les blogs d’ingénierie de Salesforce et le AWS Machine Learning Blog. L’équipe Model Serving de la plateforme IA de Salesforce se concentre sur l’intégration des modèles et la fourniture d’une infrastructure robuste pour héberger une diversité de modèles ML, y compris des grands modèles de langage (LLMs). Leur mission est de simplifier le déploiement des modèles, améliorer les performances d’inférence et optimiser l’efficacité des coûts afin d’assurer une intégration fluide dans des plateformes telles qu’Agentforce et d’autres applications dépendantes d’inférence. L’objectif est de proposer une IA avancée tout en optimisant le rapport coût/performance de l’infrastructure de service. Salesforce exploite des modèles propriétaires comme CodeGen sur SageMaker AI et les optimise pour l’inférence. Le portefeuille comprend des modèles allant de quelques gigaoctets à environ 30 Go, distribués sur des endpoints de modèle unique (SMEs) avec des besoins de performance variés. Les défis étaient doubles: (1) les grands modèles (20–30 Go) ayant peu de trafic étaient sous-utilisés sur des GPUs hautes performances, entraînant des instances multi-GPU sous-utilisées; (2) les modèles de taille moyenne (~15 Go) avec trafic élevé nécessitaient une faible latence et un débit élevé, mais coûtaient cher en raison d’un sur-approvisionnement similaire au matériel utilisé. L’objectif était une stratégie scalable et efficace en ressources sans compromettre les performances. Actuellement, Salesforce opère sur des instances EC2 P4d et prévoit de passer aux dernières instances P5en avec GPUs NVIDIA H200 Tensor Core. Ce défi reflète le besoin plus large des entreprises de maximiser les performances des workloads IA tout en maîtrisant les coûts d’infrastructure et le gaspillage de ressources. Salesforce cherchait une base flexible adaptée à ses initiatives IA en évolution et à une diversité de modèles. Pour plus de détails sur l’approche, consultez l’article conjoint Salesforce/AWS décrivant les composants d’inférence SageMaker AI et leur rôle dans l’optimisation des endpoints de modèle.
Ce qui est nouveau
- Les composants d’inférence SageMaker AI permettent de déployer un ou plusieurs modèles fondation sur un seul endpoint SageMaker AI, avec un contrôle granulaire des ressources par modèle (accélérateurs, mémoire, artefacts, image du conteneur, et copies).
- Chaque modèle fondation peut disposer de ses propres politiques de scaling; SageMaker AI gère l’empaquetage et le placement pour optimiser coût et disponibilité.
- Le scaling des instances géré peut ajuster les ressources de calcul en fonction du nombre de composants d’inférence chargés pour servir le trafic.
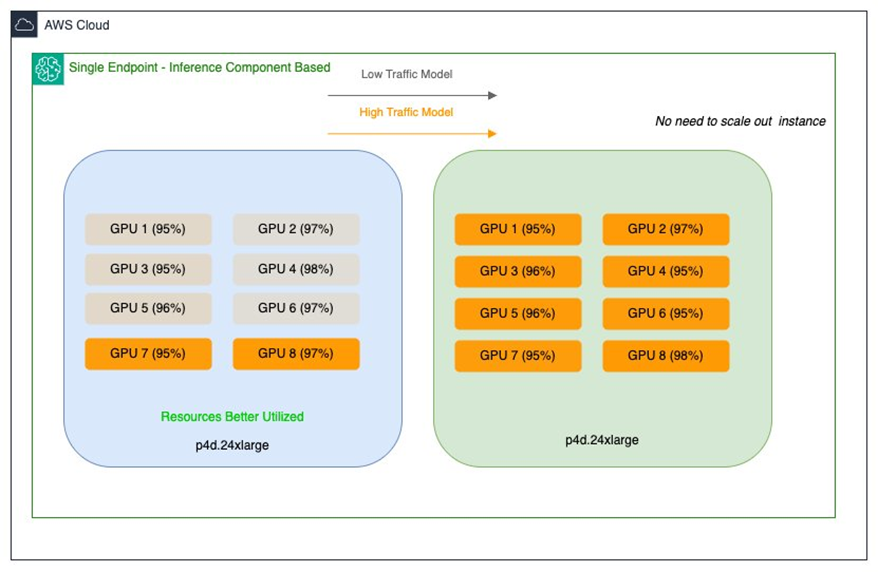
- Salesforce a introduit des endpoints de composants d’inférence parallèlement aux SMEs existants pour élargir les options d’hébergement sans sacrifier stabilité ou convivialité. Les SMEs offrent un hébergement dédié et des performances prévisibles pour les charges constantes, tandis que les composants d’inférence optimisent l’utilisation des ressources pour des charges variables via un scaling dynamique et un partage efficace des GPUs.
- L’approche permet d’héberger plusieurs modèles sur le même endpoint, avec allocation de ressources par modèle et scaling indépendant selon le trafic.
Pourquoi cela compte (impact pour les développeurs/entreprises)
- Utilisation efficace des GPUs: partager des GPUs entre plusieurs modèles sur le même endpoint améliore l’efficacité et réduit les coûts.
- Optimisation des coûts: le scaling dynamique et le contrôle de ressources par modèle réduisent le surdimensionnement et les dépenses opérationnelles.
- Simplicité opérationnelle: réunir plusieurs modèles sur moins d’endpoints diminue la charge de gestion tout en préservant les performances.
- Flexibilité et évolutivité: les entreprises peuvent introduire de nouveaux modèles sans prolifération d’endpoints dédiés.
- Architecture hybride: associer SMEs et composants d’inférence offre une stratégie de hosting équilibrée et résiliente.
Détails techniques ou Mise en œuvre
- Configuration de l’endpoint: Salesforce crée un endpoint SageMaker AI avec un type d’instance et une quantité initiale pour couvrir les besoins de base en inférence.
- Composants d’inférence: un modèle est configuré en tant que composant d’inférence, précisant le nombre d’accélérateurs et la mémoire allouée à chaque copie, les artefacts du modèle, l’image du conteneur, et le nombre de copies à déployer. Cette construction permet un contrôle granulaire par modèle au sein de l’endpoint.
- Hébergement multi-modèles: il est possible d’attacher dynamiquement plusieurs paquets de modèles à l’endpoint, en démarrant des conteneurs individuels selon les besoins. Par exemple, BlockGen et TextEval peuvent être configurés en tant que composants d’inférence distincts avec des allocations de ressources explicites.
- Scaling et empaquetage: à mesure que le trafic augmente ou diminue, les composants d’inférence peuvent scaler vers le haut ou le bas via des politiques de scaling automatique. SageMaker AI gère le placement pour optimiser l’empaquetage des modèles pour la disponibilité et le coût. Si le scaling d’instances géré est activé, SageMaker AI dimensionne les instances de calcul en fonction du nombre de composants à charger pour servir le trafic, et empaquette les instances et les composants pour optimiser le coût sans compromettre les performances.
- Approche d’hébergement hybride: Salesforce utilise des endpoints de composants d’inférence aux côtés des SMEs pour élargir les options d’hébergement sans perturber la stabilité. Les SMEs offrent un hébergement dédié et des performances prévisibles pour les charges constantes, tandis que les composants d’inférence optimisent l’utilisation des ressources pour les charges variables par le biais d’un scaling dynamique et d’un partage efficace des GPUs.
- Modèles de référence: l’ensemble CodeGen de Salesforce comprend Inline (complétion automatique de code), BlockGen (génération de blocs de code) et FlowGPT (génération de flux de processus), ajustés pour le langage Apex. Ces modèles illustrent les bénéfices du partage des ressources tout en conservant une allocation et un scaling spécifiques par modèle dans le même endpoint.
- Impact sur les ressources et les coûts: en affinant l’allocation GPU au niveau du modèle et en permettant une allocation dynamique, Salesforce obtient une meilleure efficacité et des économies significatives, avec une réduction notable des coûts de déploiement et d’infrastructure. Le texte souligne que le bon empaquetage des modèles et l’allocation dynamique des ressources ont été déterminants pour répondre aux besoins variés de GPU.
- Contexte matériel actuel et futur: Salesforce opère sur des instances P4d et prévoit d’adopter des instances P5en avec GPU NVIDIA H200 Tensor Core pour optimiser davantage les performances et les coûts.
Tableaux: faits clés (illustratif)
| Aspect | SMEs traditionnels | Composants d’inférence (sur un seul endpoint) |
|---|---|---|
| Contrôle des ressources | Allocation par endpoint, granularité limitée par modèle | |
| Accélérateurs et mémoire par modèle, copies multiples | ||
| Escalade | Escalade par endpoint | |
| Escalade par modèle, empaquetage intelligent | ||
| Partage GPU | Partage limité entre modèles | |
| Partage efficace entre plusieurs modèles sur le même endpoint | ||
| Déploiement | Plusieurs endpoints pour plusieurs modèles | |
| Moins d’endpoints, plusieurs modèles par endpoint |
Points clés
- Les composants d’inférence permettent à plusieurs modèles de partager des ressources GPU sur le même endpoint, améliorant l’efficience et réduisant les coûts.
- Le contrôle granulaire par modèle (accélérateurs, mémoire, copies) soutient des exigences variées sans surdimensionnement.
- Le scaling automatique et l’empaquetage intelligent réduisent les gaspillages et maintiennent les performances lors des variations de trafic.
- L’approche hybride (SMEs + composants) offre un équilibre entre stabilité et expansion des options d’hébergement.
- L’implémentation de Salesforce illustre des économies substantielles et une meilleure capacité de débit pour des workloads IA avancés, tout en conservant une faible latence pour les charges à fort trafic.
FAQ
Références
More news

NVIDIA HGX B200 réduit l’intensité des émissions de carbone incorporé
Le HGX B200 de NVIDIA abaisse l’intensité des émissions de carbone incorporé de 24% par rapport au HGX H100, tout en offrant de meilleures performances IA et une efficacité énergétique accrue. Cet article résume les données PCF et les nouveautés matérielles.

Faire passer vos agents IA du concept à la production avec Amazon Bedrock AgentCore
Une exploration détaillée de la façon dont Amazon Bedrock AgentCore aide à faire passer des applications IA basées sur des agents du proof of concept à des systèmes de production de niveau entreprise, en préservant mémoire, sécurité, observabilité et gestion d’outils à l’échelle.

Comment réduire les goulots d’étranglement KV Cache avec NVIDIA Dynamo
NVIDIA Dynamo déporte le KV Cache depuis la mémoire GPU vers un stockage économique, permettant des contextes plus longs, une meilleure concurrence et des coûts d’inférence réduits pour les grands modèles et les charges AI génératives.

Le Playbook des Grands Maîtres Kaggle: 7 Techniques de Modélisation pour Données Tabulaires
Analyse approfondie de sept techniques éprouvées par les Grands Maîtres Kaggle pour résoudre rapidement des ensembles de données tabulaires à l’aide d’une accélération GPU, des baselines divers à l’assemblage et à la pseudo-étiquetage.

Microsoft transforme le site Foxconn en data center Fairwater AI, présenté comme le plus puissant au monde
Microsoft dévoile des plans pour un data center Fairwater AI de 1,2 million de mètres carrés au Wisconsin, abritant des centaines de milliers de GPU Nvidia GB200. Le projet de 3,3 milliards de dollars promet un entraînement IA sans précédent.

Surveiller l’inférence par lot Bedrock d’AWS via les métriques CloudWatch
Apprenez à surveiller et optimiser les jobs d’inférence par lot Bedrock via CloudWatch, with alertes et tableaux de bord pour améliorer les performances, les coûts et l’exploitation.