Traitement intelligent des documents évolutif avec Amazon Bedrock Data Automation
Sources: https://aws.amazon.com/blogs/machine-learning/scalable-intelligent-document-processing-using-amazon-bedrock-data-automation, aws.amazon.com
TL;DR
- Traitement intelligent des documents (IDP) évolutif et sans serveur avec Amazon Bedrock Data Automation, AWS Step Functions et Amazon A2I.
- Utilisation de blueprints ( standards et personnalisés ) pour appliquer automatiquement la logique d’extraction à divers types de documents (par exemple dossiers de vaccination, certificats fiscaux, formulaires d’inscription, permis de conduire).
- Inclusion de la normalisation des données, d’extractions explicites et implicites, et de règles de validation pour assurer la qualité et la cohérence des données.
- Revue humaine en boucle via A2I avec mise en évidence des bounding boxes pour vérifier les résultats, réduisant les risques tout en permettant un développement rapide et évolutif.
Contexte et arrière-plan
Le traitement intelligent des documents (IDP) automatise l’extraction, l’analyse et l’interprétation d’informations critiques à partir d’un large éventail de documents. En conjuguant apprentissage automatique avancé et traitement du langage naturel, l’IDP peut extraire des données structurées à partir de textes non structurés, rationalisant les flux de documents. Lorsqu’il est enrichi par les capacités d’IA générative, l’IDP permet de transformer les flux documentaires grâce à une meilleure compréhension, à l’extraction de données structurées et à une classification automatisée. Cette approche est pertinente dans de nombreux secteurs, notamment les services à l’enfant, l’assurance, la santé, les services financiers et le secteur public. Les procédés manuels traditionnels créent des goulots d’étranglement et accroissent le risque d’erreurs; les solutions IDP assistées par IA peuvent considérablement améliorer l’efficacité des flux et la récupération d’informations, tout en réduisant les charges administratives. Le billet AWS met en avant comment Bedrock Data Automation porte l’IDP à un niveau supérieur grâce à la pondération de confiance, aux données de bounding box, à la classification automatique et au développement rapide via des blueprints, afin de permettre des solutions IDP plus solides et évolutives, intégrant une revue humaine. Ce billet illustre aussi le déploiement d’un pipeline IDP entièrement sans serveur capable de traiter plusieurs types de documents dans un seul projet, utilisant Bedrock Data Automation, AWS Step Functions et Amazon A2I. Pour le contexte, le billet explique comment traiter une variété de documents — des dossiers d’immunisation aux permis de conduire — dans un flux unifié et comment appliquer automatiquement le blueprint le plus adapté selon l’analyse du contenu. L’objectif est de réduire les délais de développement, d’améliorer la qualité des données et de soutenir les systèmes en aval avec des données formatées et validées de manière cohérente. Le contenu s’appuie sur ces descriptions et exemples pour montrer comment Bedrock Data Automation peut être utilisé pour faire évoluer l’IDP dans les contextes du secteur public et de l’entreprise. AWS Blog.
Nouvelles fonctionnalités
Bedrock Data Automation introduit des fonctionnalités qui améliorent significativement l’évolutivité et la précision des solutions IDP. Dans le pipeline présenté, une architecture entièrement sans serveur combine Bedrock Data Automation avec AWS Step Functions et Amazon A2I pour offrir une montée en charge rentable pour des charges de travail de volumes variables. Le flux Step Functions utilise un état Map pour traiter chaque document d’un fichier et peut gérer des entrées contenant un ou plusieurs documents. Parmi les capacités, on trouve :
- Utilisation de blueprints standards et personnalisés dans un seul projet, ce qui permet d’appliquer automatiquement la logique d’extraction correcte pour différents types de documents (par exemple, formulaires d’inscription, certificats d’imposition, formulaires d’inscription de soutien à l’enfance, permis de conduire).
- Sélection du blueprint basée sur l’analyse de contenu, garantissant que les bons champs sont extraits pour chaque type de document.
- Normalisation des données pour assurer que les systèmes en aval reçoivent des données homogènes (par exemple dates au format YYYY-MM-DD, numéros de sécurité sociale masqués XXX-XX-XXXX).
- Extractions explicites et implicites.
- Transformations de données personnalisées, comme un type d’adresse personnalisé qui segmente les adresses en champs structurés (Rue, Ville, État, Code postal) et réutilise ces champs sur les adresses associées, facilitant l’intégration avec les systèmes existants.
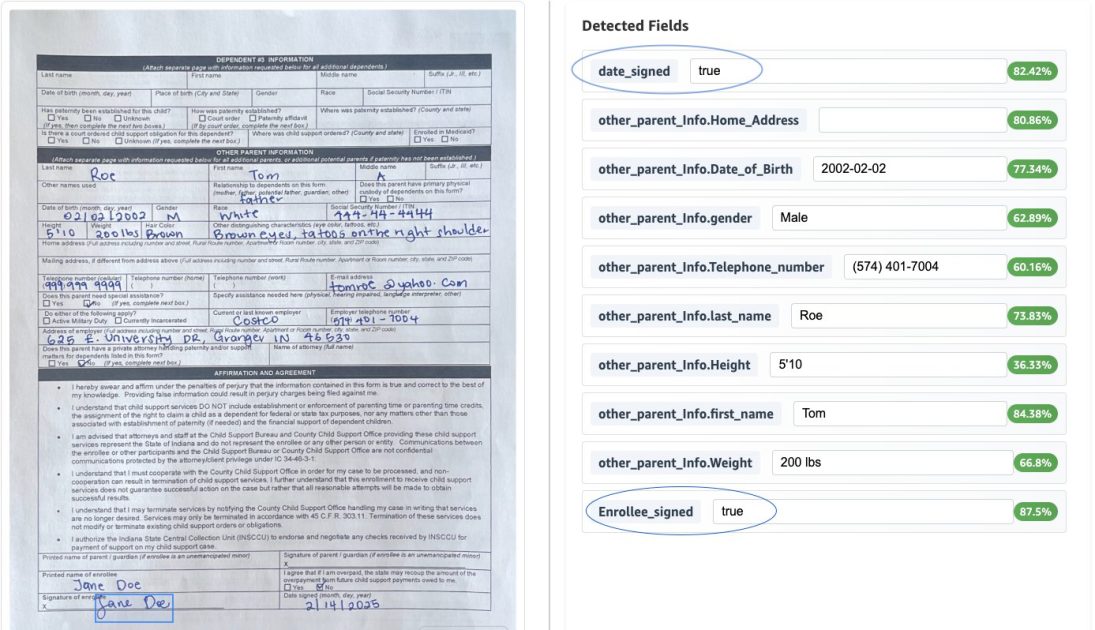
- Règles de validation afin de garantir l’exactitude et la conformité (par exemple, présence de la signature de l’assuré et vérification que la date signée n’est pas dans le futur).
- Notation de confiance et données de bounding box pour évaluer la qualité des extractions et fournir des informations utiles pour la revue humaine.
- Revue humaine dans le flux via l’interface A2I avec surlignage des bounding boxes pour les champs sélectionnés lors de la vérification, puis reprise du flux lorsque la vérification est terminée et stockage du résultat révisé dans S3. L’approche illustre comment Bedrock Data Automation peut accélérer le développement IDP, améliorer la qualité des données et offrir des solutions robustes et évolutives qui s’intègrent à des processus de révision humaine. Pour explorer les étapes exactes et les exemples, le billet propose un répertoire GitHub associé offrant des instructions de déploiement. AWS Blog.
Pourquoi c’est important (impact pour les développeurs/entreprises)
- Évolutivité et rentabilité : une architecture entièrement sans serveur peut s’adapter à différentes combinaisons de documents et volumes, réduisant les coûts opérationnels et la gestion d’infrastructure.
- Temps de mise en valeur plus rapide : développement rapide grâce aux blueprints et transformations de données automatisées.
- Qualité et cohérence des données : normalisation et validations assurent que les données sont propres et prêtes pour les systèmes en aval.
- Gouvernance et supervision humaine : l’intégration avec A2I permet une revue humaine lorsque nécessaire, tout en préservant le contrôle.
- Applicabilité étendue : l’approche convient à de multiples domaines, y compris les formulaires d’inscription et les documents liés au secteur public, aidant les organisations à améliorer le service.
Détails techniques ou Mise en œuvre
La solution est présentée comme une architecture entièrement sans serveur utilisant Bedrock Data Automation avec AWS Step Functions et Amazon A2I. Le flux traite un fichier contenant un ou plusieurs documents via un état Map, en appliquant la blueprint d’extraction appropriée pour chaque élément. Si la confiances des extractions atteint le seuil, la sortie est stockée dans un bucket S3 ; sinon, elle est envoyée à Amazon A2I pour révision humaine. L’interface A2I permet le surlignage des bounding boxes pendant la vérification, puis le flux reprend et la sortie révisée est stockée dans S3. | Composant | Rôle | Remarques |---|---|---| | Amazon Bedrock Data Automation | Traitement IDP et transformations | Fournit score de confiance, classification automatique, blueprints et normalisation/validations |AWS Step Functions | Orchestration | État Map permet le traitement par document dans un fichier |Amazon A2I | Revue humaine | UI avec surlignage bounding box pour les champs |Amazon S3 | Stockage | Sorties automatiques et révisées stockées ici | La solution gère divers types de documents dans un seul projet, appliquant automatiquement le blueprint approprié basé sur l’analyse du contenu. La normalisation des données assure une consommation homogène en aval, tandis que les extractions explicites et implicites offrent la flexibilité pour des champs clairement indiqués et des champs nécessitant des transformations (format de date, structure d’adresse). Dans l’exemple de formation d’inscription au soutien infantil, un type de données d’adresse personnalisé décompose les adresses en champs structurés (Rue, Ville, État, Code postal) et réutilise ces champs dans d’autres adresses pour favoriser la cohérence et l’intégration. Des règles de validation assurent la présence de la signature et que la date n’est pas future. Pour les praticiens, le billet souligne que Bedrock Data Automation peut réduire considérablement les délais de développement, améliorer la qualité des données et offrir des solutions IDP robustes et évolutives fonctionnant avec des processus de révision humaine. Si vous souhaitez explorer les étapes exactes et les exemples, le répertoire GitHub associé donne des instructions de déploiement. AWS Blog.
Points clés à retenir
- Bedrock Data Automation élève l’IDP avec des scores de confiance, données de bounding box, classification automatique et développement rapide via des blueprints.
- Une architecture entièrement sans serveur avec Step Functions et A2I autorise un traitement évolutif pour des charges variées et types de documents.
- La normalisation des données et les transformations personnalisées améliorent la qualité et l’intégration.
- La revue humaine via A2I est intégrée aux points critiques pour assurer l’exactitude sans réduire l’efficacité.
- L’approche convient à de multiples domaines, y compris les services d’inscription et d’autres flux du secteur public.
FAQ
-
- **Q : Qu’est-ce que Bedrock Data Automation dans le cadre de l’IDP ?**
Il offre des capacités de traitement de documents avec une pondération de confiance, des bounding boxes, une classification automatique et un développement rapide basé sur des blueprints pour faire évoluer les flux IDP. - **Q : Comment les différents types de documents sont-ils gérés dans le flux ?** **A :** Le système applique automatiquement le blueprint approprié selon l’analyse du contenu, ce qui permet d’extraire les champs adéquats pour chaque type de document dans un seul projet. - **Q : Que se passe-t-il si la confiance de l’extraction est inférieure au seuil ?** **A :** Le document est envoyé à la révision humaine via Amazon A2I, où les bounding boxes aident les réviseurs à vérifier et corriger les résultats avant de les renvoyer dans le pipeline. - **Q : Quels documents sont démontrés dans l’exemple ?** **A :** Le billet couvre les formulaires d’inscription au soutien infantile, les dossiers d’immunisation, les certificats fiscaux et les permis de conduire, traités via un pipeline entièrement sans serveur.
Références
More news

Faire passer vos agents IA du concept à la production avec Amazon Bedrock AgentCore
Une exploration détaillée de la façon dont Amazon Bedrock AgentCore aide à faire passer des applications IA basées sur des agents du proof of concept à des systèmes de production de niveau entreprise, en préservant mémoire, sécurité, observabilité et gestion d’outils à l’échelle.

Surveiller l’inférence par lot Bedrock d’AWS via les métriques CloudWatch
Apprenez à surveiller et optimiser les jobs d’inférence par lot Bedrock via CloudWatch, with alertes et tableaux de bord pour améliorer les performances, les coûts et l’exploitation.

Prompting pour la précision avec Stability AI Image Services sur Amazon Bedrock
Bedrock intègre Stability AI Image Services avec neuf outils pour créer et modifier des images avec précision. Apprenez les techniques de prompting adaptées à l’entreprise.

Utiliser les AWS Deep Learning Containers avec SageMaker AI géré MLflow
Découvrez comment les AWS Deep Learning Containers (DLCs) s’intègrent à SageMaker AI géré par MLflow pour équilibrer le contrôle de l’infrastructure et une gouvernance ML robuste. Un flux TensorFlow pour la prédiction de l’âge des abalones illustre le suivi de bout en bout et la traçabilité des modè

Évoluer la production visuelle avec Stability AI Image Services dans Amazon Bedrock
Stability AI Image Services est désormais disponible dans Amazon Bedrock, offrant des capacités d’édition d’images prêtes à l’emploi via l’API Bedrock et étendant les modèles Stable Diffusion 3.5 et Stable Image Core/Ultra déjà présents.

Créer des flux de travail agentiques avec GPT OSS d’OpenAI sur SageMaker AI et Bedrock AgentCore
Vue d’ensemble complète sur le déploiement des modèles GPT OSS d’OpenAI sur SageMaker AI et Bedrock AgentCore pour alimenter un analyseur d’actions multi-agents avec LangGraph, incluant la quantification MXFP4 en 4 bits et une orchestration sans serveur.