Amazon Bedrock AgentCore Memory : construire des agents conscients du contexte
Sources: https://aws.amazon.com/blogs/machine-learning/amazon-bedrock-agentcore-memory-building-context-aware-agents, aws.amazon.com
TL;DR
- Amazon Bedrock AgentCore Memory est un service de mémoire entièrement géré pour agents IA, équilibrant contexte à court terme et insights à long terme.
- Il élimine les infrastructures mémoire complexes, permettant des interactions persistantes, contextuelles et personnalisées sur plusieurs sessions.
- Caractéristiques clés : ressource mémoire avec expiration des événements, chiffrement au repos et en transit, espaces de noms, stratégies mémoire et support du branching et des checkpoints.
- Il s’intègre aux composants Bedrock AgentCore et prend en charge des stratégies mémoire intégrées et personnalisées pour des cas d’usage variés.
- Des fonctionnalités avancées comme le branching et les checkpoints étendent la gestion mémoire au-delà de la simple rétention de contexte.
Contexte et arrière-plan
Les grands modèles de langage (LLMs) excellent à générer des réponses proches du langage humain mais sont par essence sans état, oubliant des détails entre les interactions. Les développeurs ont traditionnellement dû mettre en place des couches mémoire pour suivre l’historique, les préférences des utilisateurs et le contexte entre les sessions. Lors du AWS Summit New York City 2025, AWS a présenté Amazon Bedrock AgentCore Memory, un service entièrement géré conçu pour simplifier la gestion de mémoire des IA tout en donnant le contrôle sur ce qui est mémorisé. En fournissant une mémoire à court terme et une mémoire intelligente à long terme, les agents peuvent se souvenir des conversations, apprendre les préférences et offrir des expériences plus personnalisées https://aws.amazon.com/blogs/machine-learning/amazon-bedrock-agentcore-memory-building-context-aware-agents.
Quoi de neuf
AgentCore Memory est présenté comme un service entièrement géré permettant aux agents IA de livrer des interactions intelligentes, contextuelles et personnalisées en conservant une mémoire de travail à court terme et une mémoire à long terme intelligente. Le service s’intègre aux autres composants Bedrock AgentCore (Runtime et Observability) et adopte une conception API-first avec des defaults vérifiés, tout en restant extensible pour des scénarios avancés. Concepts et capacités clés :
- Ressource mémoire : conteneur logique qui regroupe des événements bruts et des mémoires à long terme traitées. Vous pouvez définir une expiration des événements pour la mémoire à court terme (jusqu’à 365 jours) et gérer la rétention, la sécurité et la transformation des données en insights. Les données sont chiffrées au repos et en transit ; par défaut, des clés gérées par AWS sont utilisées, avec option d’utiliser des clés KMS gérées par le client.
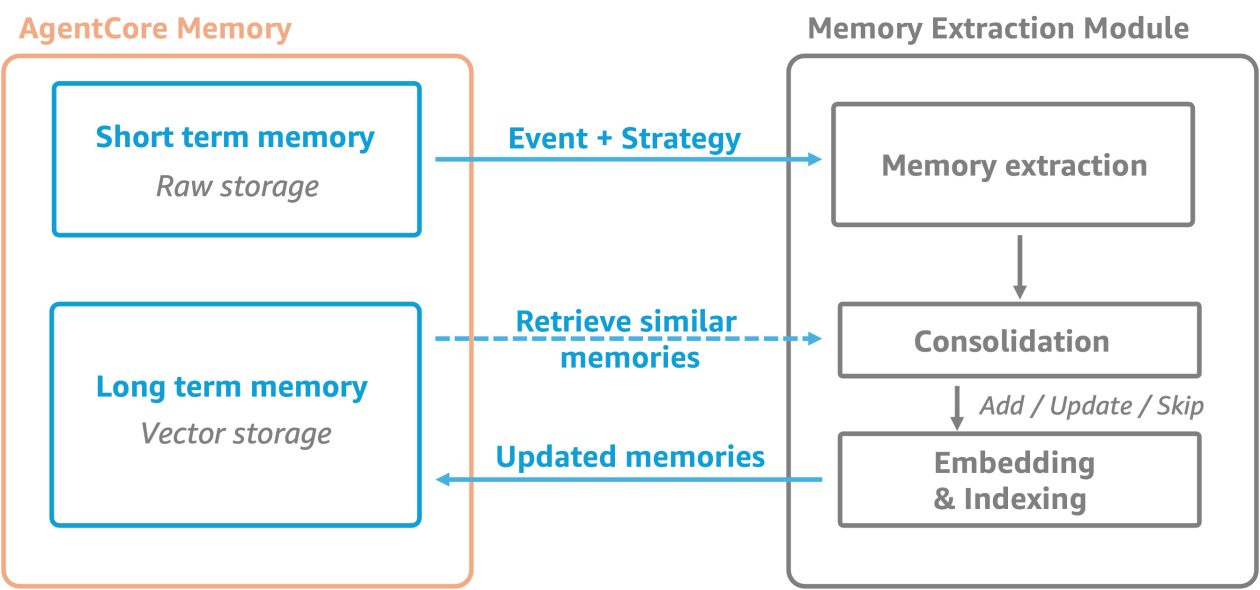
- Mémoire à court terme : capture les données d’interaction brutes sous forme d’événements immuables, organisés par acteur et session. Les événements peuvent être Conversationnels (USER/ASSISTANT/TOOL ou types similaires) ou blob (contenu binaire). Seuls les événements Conversationnels alimentent l’extraction de mémoire à long terme.
- Mémoire à long terme : stocke les insights, préférences et connaissances dérivés des événements bruts. Contrairement à la mémoire à court terme, elle conserve des informations significatives entre les sessions. L’extraction se fait de manière asynchrone après la création des événements, selon les stratégies de mémoire définies.
- Namespaces : structure hiérarchique dans la mémoire à long terme pour organiser les mémoires. Les namespaces facilitent les déploiements multi-locataires et peuvent être dynamiquement créés avec des variables de remplacement. La récupération peut être exacte ou par préfixe.
- Stratégies mémoire : couche d’intelligence qui détermine quoi extraire et comment stocker les mémoires; trois stratégies intégrées et la possibilité de stratégies personnalisées (Custom). Par défaut, les stratégies ignorent les données PII.
- Architecture et intégration : les composants fonctionnent ensemble pour offrir contexte immédiat et compréhension à long terme, avec des visuels de l’architecture AgentCore Memory. Des capacités avancées incluent :
- Branching : créer des chemins de conversation alternatifs à partir d’un point précis de l’historique, en créant une nouvelle branche au sein du même ressource mémoire et en utilisant le même actor_id et session_id, avec un rootEventId d’origine.
- Checkpoints : enregistrer et marquer des états spécifiques de la conversation pour référence ultérieure; les checkpoints peuvent être implémentés via des événements bruts sous une isolation différente et récupérés via GetEvent.
- Événements blob : ingestion de données non conversationnelles dans divers formats, non utilisés pour l’extraction mémoire à long terme.
- Exemple pratique : le billet de blog mentionne la création d’une ressource mémoire pour un agent de support client en utilisant le client Boto3, illustrant l’application dans un scénario réel.
Pourquoi c’est important (impact pour les développeurs/entreprises)
Pour les développeurs et les organisations, AgentCore Memory réduit le fardeau opérationnel lié à l’implémentation de la mémoire pour les agents IA et permet des interactions plus naturelles et persistantes. En conservant les préférences des utilisateurs, le contexte et l’historique des conversations à travers les sessions, les agents évitent les questions répétitives et s’adaptent avec le temps. La capacité de structurer les mémoires avec des namespaces soutient les déploiements multi-tenant et des écosystèmes d’agents évolutifs, tandis que les branching et checkpoints permettent une gestion avancée des conversations et l’orchestration de workflows. En somme, cette solution rapproche la mémoire humaine de la mémoire machine, réduisant latence et coûts liés à la re-demande d’informations et offrant des expériences plus personnalisées.
Détails techniques ou Mise en œuvre
- Resource mémoire et rétention des données : chaque ressource mémoire définit la durée de conservation des données brutes dans la mémoire à court terme via une durée d’expiration des événements (jusqu’à 365 jours). Les données sont chiffrées au repos et en transit par défaut, avec des clés gérées par AWS ou des clés KMS du client.
- Types d’événements et stockage : mémoire à court terme stocke des événements immuables organisés par acteur et session. Les événements peuvent être Conversationnels ou blob. Seuls les événements Conversationnels alimentent l’extraction de mémoire à long terme.
- Mémoire à long terme et extraction : les mémoires sont dérivées des événements bruts de manière asynchrone selon les stratégies de mémoire. Elles persistent entre les sessions et reflètent des insights et préférences significatifs.
- Namespaces et organisation : les namespaces permettent une organisation hiérarchique dans la mémoire à long terme pour les scénarios multi-locataires. La récupération peut se faire par namespace exact ou par préfixe. Définition dynamique avec variables pour éviter les identifiants codés en dur.
- Stratégies de mémoire : trois stratégies intégrées et la possibilité de stratégies personnalisées (Custom) qui permettent de choisir un LLM et d’ajuster les invites pour l’extraction et la consolidation selon le domaine. Par défaut, les stratégies ignorent les données PII pour les mémoires à long terme.
- Fonctionnalités avancées : branching et checkpoints étendent les capacités au-delà de la simple rétention de contexte. Branching autorise des chemins de conversation multiples; checkpoints offrent des points de référence pour revenir plus tard. Les événements blob permettent l’ingestion de données non conversationnelles et ne participent pas à l’extraction mémoire à long terme.
- Intégration et écosystème : AgentCore Memory est conçu pour s’intégrer avec d’autres composants Bedrock AgentCore (Runtime et Observability) et repose sur une approche API-first avec des defaults sensés et une extensibilité pour les scénarios avancés.
- Contexte pratique : l’approche répond au besoin de relations utilisateur-agent continues, transformant des conversations isolées en interactions évolutives où les préférences et le contexte peuvent être mémorisés et exploités.
Tableau: aspects clés de la mémoire
| Aspect | Description |
|---|---|
| Ressource mémoire | Conteneur logique pour les événements bruts et les mémoires à long terme; configure retenue et sécurité. |
| Types d’événements | Conversationnels (utilisés pour l’extraction à long terme) et blob (non-conversationnel). |
| Mémoire à court terme | Événements immuables, organisés par acteur et session; stockage synchrone. |
| Mémoire à long terme | Insights dérivés des événements; persiste à travers les sessions. |
| Namespaces | Organisation hiérarchique pour multi-locataires. |
| Stratégies mémoire | Définissent l’extraction et le stockage; options intégrées et personnalisées. |
| Fonctions avancées | Branching et checkpoints, plus ingestion de blobs. |
Points clés
- AgentCore Memory offre une solution mémoire entièrement gérée pour les agents IA, couvrant mémoire de court et long terme.
- Permet un contexte persistant, des préférences utilisateur et des expériences personnalisées sur plusieurs sessions, tout en réduisant la charge de gestion mémoire pour les développeurs.
- Introduit ressources mémoire, espaces de noms, stratégies et fonctions avancées (branching et checkpoints) pour des workflows sophistiqués.
- Les données sont chiffrées par défaut et peuvent être protégées par des clés KMS client; gestion prudente des données PII.
- L’intégration avec les composants Bedrock AgentCore est au cœur, avec support des stratégies mémoire intégrées et personnalisées pour divers usages.
FAQ
-
- **Q : Qu’est-ce que Amazon Bedrock AgentCore Memory ?**
C’est un service entièrement géré qui fournit mémoire à court terme et mémoire à long terme pour des agents IA, permettant des interactions contextuelles et personnalisées. - **Q : Comment gère-t-on la mémoire des conversations entre sessions ?** **A :** On stocke les événements bruts dans la mémoire à court terme et on extrait la mémoire à long terme de manière asynchrone, avec organisation par acteur, session et namespaces. - **Q : Quelles fonctionnalités avancées offre-t-il ?** **A :** Branching permet des chemins de conversation parallèles; les checkpoints mémorisent des états; les événements blob acceptent des données non conversationnelles (non utilisés pour l’extraction de mémoire à long terme). - **Q : Comment la sécurité et la rétention des données sont-elles gérées ?** **A :** Les données sont chiffrées au repos et en transit par défaut, avec des clés AWS gérées ou des clés KMS client; l’expiration des événements peut atteindre 365 jours pour la mémoire à court terme.
Références
More news

Faire passer vos agents IA du concept à la production avec Amazon Bedrock AgentCore
Une exploration détaillée de la façon dont Amazon Bedrock AgentCore aide à faire passer des applications IA basées sur des agents du proof of concept à des systèmes de production de niveau entreprise, en préservant mémoire, sécurité, observabilité et gestion d’outils à l’échelle.

Comment réduire les goulots d’étranglement KV Cache avec NVIDIA Dynamo
NVIDIA Dynamo déporte le KV Cache depuis la mémoire GPU vers un stockage économique, permettant des contextes plus longs, une meilleure concurrence et des coûts d’inférence réduits pour les grands modèles et les charges AI génératives.

Surveiller l’inférence par lot Bedrock d’AWS via les métriques CloudWatch
Apprenez à surveiller et optimiser les jobs d’inférence par lot Bedrock via CloudWatch, with alertes et tableaux de bord pour améliorer les performances, les coûts et l’exploitation.

Prompting pour la précision avec Stability AI Image Services sur Amazon Bedrock
Bedrock intègre Stability AI Image Services avec neuf outils pour créer et modifier des images avec précision. Apprenez les techniques de prompting adaptées à l’entreprise.

Utiliser les AWS Deep Learning Containers avec SageMaker AI géré MLflow
Découvrez comment les AWS Deep Learning Containers (DLCs) s’intègrent à SageMaker AI géré par MLflow pour équilibrer le contrôle de l’infrastructure et une gouvernance ML robuste. Un flux TensorFlow pour la prédiction de l’âge des abalones illustre le suivi de bout en bout et la traçabilité des modè

Évoluer la production visuelle avec Stability AI Image Services dans Amazon Bedrock
Stability AI Image Services est désormais disponible dans Amazon Bedrock, offrant des capacités d’édition d’images prêtes à l’emploi via l’API Bedrock et étendant les modèles Stable Diffusion 3.5 et Stable Image Core/Ultra déjà présents.