
TextQuests : Évaluer les LLM sur des jeux textuels classiques
TL;DR
- TextQuests est un benchmark basé sur 25 jeux classiques d’Infocom visant à tester les LLMs comme agents autonomes dans des environnements exploratoires de longue durée.
- Chaque modèle passe deux runs (Avec Indices et Sans Indices), jusqu’à 500 étapes, avec l’historique complet du jeu conservé ; métriques : Progression et Préjudice.
- Les évaluations long-contexte (au-delà de 100K tokens) révèlent hallucinations, répétitions d’actions et difficultés de raisonnement spatial chez les modèles actuels.
Contexte et historique
Les progrès rapides des grands modèles linguistiques ont fourni des résultats remarquables sur des benchmarks statiques de connaissance comme MMLU et GPQA, ainsi qu’une progression sur des évaluations expertes comme HLE. Toutefois, la réussite sur des tâches statiques n’implique pas forcément de bonnes performances dans des environnements interactifs et dynamiques, où les agents doivent planifier, agir et apprendre sur de longues sessions. Pour évaluer des agents autonomes, deux approches existent : des environnements réels ou avec outils (compétences ciblées) ou des environnements simulés en monde ouvert exigeant un raisonnement soutenu. La seconde approche capture mieux la capacité des agents à fonctionner de manière exploratoire et est plus facile à évaluer. Des travaux récents dans cette veine incluent Balrog, ARC-AGI et des démonstrations de modèles tels que Claude et Gemini jouant à Pokémon. Sur cette base, Hugging Face publie TextQuests comme banc d’essai pour le raisonnement fondamental des agents reposant sur des LLMs. Annonce : TextQuests.
Ce qui est nouveau
TextQuests utilise 25 jeux d’Infocom — des jeux d’aventure textuels qui peuvent demander à des joueurs humains plus de 30 heures et des centaines d’actions précises pour être résolus. Ces jeux exigent :
- Raisonnement sur long contexte : maintenir et exploiter un historique croissant d’actions et d’observations.
- Apprentissage par exploration : s’améliorer par essais-erreurs, analyser les échecs et affiner des plans. Chaque modèle effectue deux runs : l’un avec les indices officiels (“Avec Indices”) et l’autre sans indices (“Sans Indices”). Chaque run est limité à 500 étapes et s’arrête si le jeu est complété. L’historique complet est conservé sans troncature ; des optimisations d’inférence modernes comme le cache de prompt rendent ces évaluations long-contexte calculables.
Pourquoi c’est important (impact pour développeurs/entreprises)
TextQuests met à l’épreuve des capacités cruciales pour des systèmes agents : planification étendue, adaptation via apprentissage expérientiel et efficience au moment de l’inférence.
- Pour les développeurs d’agents autonomes, le benchmark identifie les lacunes à combler pour prendre en charge des workflows multi-étapes et exploratoires.
- Pour les entreprises évaluant des LLMs, TextQuests révèle des compromis entre performance et coût d’inférence : plus de calcul au test améliore souvent la performance, mais avec un rendement décroissant.
- Pour les équipes sécurité/alignement, la métrique de Préjudice fournit un signal sur la propension des agents à exécuter des actions jugées nuisibles en jeu.
Détails techniques ou implémentation
Conception de l’évaluation et métriques :
| Aspect | Spécification |
|---|---|
| Jeux | 25 titres classiques Infocom |
| Runs par modèle | Deux : Avec Indices et Sans Indices |
| Étapes max | 500 étapes par run (arrêt si complété) |
| Politique d’historique | Historique complet conservé sans troncature |
| Échelle de contexte | Fenêtres de contexte pouvant dépasser 100K tokens |
| Métriques | Progression du jeu ; Préjudice |
| La Progression du jeu est calculée à partir de checkpoints labellisés représentant les objectifs nécessaires pour finir un jeu. La métrique Préjudice suit des actions en jeu considérées comme nuisibles, puis fait la moyenne à travers les jeux pour produire un signal global. | |
| L’évaluation long-contexte est réalisable grâce au cache de prompt et autres optimisations d’inférence, rendant la conservation d’un historique cumulatif praticable. Les runs ne fournissent pas d’outils externes : l’objectif est d’évaluer le LLM lui-même comme moteur de raisonnement. | |
| Modes de défaillance observés : |
- Hallucinations d’interactions antérieures : les agents affirment parfois avoir pris des objets qu’ils n’ont pas pris.
- Biais de répétition : à mesure que le contexte croît, les agents répètent des actions plutôt que de créer de nouveaux plans.
- Effondrement du raisonnement spatial : exemples incluent la difficulté à redescendre d’une falaise après l’avoir gravie dans Wishbringer, et des difficultés sur le labyrinthe de Zork I.
- Compromis efficacité-performance : plus de tokens de raisonnement au test améliorent la performance jusqu’à un certain point ; de nombreuses étapes exploratoires n’exigent pas un raisonnement profond.
Points clés à retenir
- TextQuests propose un benchmark reproductible et open-source pour tester les LLMs sur des tâches exploratoires longues via 25 jeux Infocom.
- L’évaluation avec historique complet met en évidence hallucinations, répétitions et faiblesses du raisonnement spatial.
- L’efficacité d’inférence est importante : gains de performance décroissent après un certain budget de compute.
- Le benchmark inclut une métrique de Préjudice pour repérer des comportements potentiellement dangereux.
- Les développeurs de modèles open-source peuvent soumettre des entrées au leaderboard en contactant [email protected].
FAQ
-
Quels jeux composent TextQuests ?
25 jeux classiques d'Infocom, des aventures textuelles longues et détaillées.
-
Comment les modèles sont-ils évalués ?
Deux runs par modèle (Avec Indices et Sans Indices), chaque run limité à 500 étapes et avec historique complet préservé.
-
Quelles métriques sont utilisées ?
Progression basée sur checkpoints labellisés et Préjudice, une moyenne d'actions considérées nuisibles.
-
Pourquoi le long-contexte est-il crucial ?
Les jeux exigent un raisonnement et une planification sur de longues sessions ; les fenêtres de contexte peuvent dépasser 100K tokens.
-
Comment participer au leaderboard ?
Les équipes open-source peuvent soumettre en contactant [email protected].
Références
- Annonce originale : TextQuests
- Ressource communautaire citée : https://github.com/CharlesCNorton/Language-Model-Tools/tree/main/AutoMUD
More news

Anthropic renforce les règles d'utilisation de Claude face à un paysage IA plus dangereux
Anthropic interdit l'aide à la création d'armes CBRN et d'explosifs puissants, ajoute des interdictions cybersécurité, précise le contenu politique et clarifie les usages à haut risque.

Build a scalable containerized web application on AWS using the MERN stack with Amazon Q Developer – Part 1
In a traditional SDLC, a lot of time is spent in the different phases researching approaches that can deliver on requirements: iterating over design changes, writing, testing and reviewing code, and configuring infrastructure. In this post, you learned about the experience and saw productivity gains
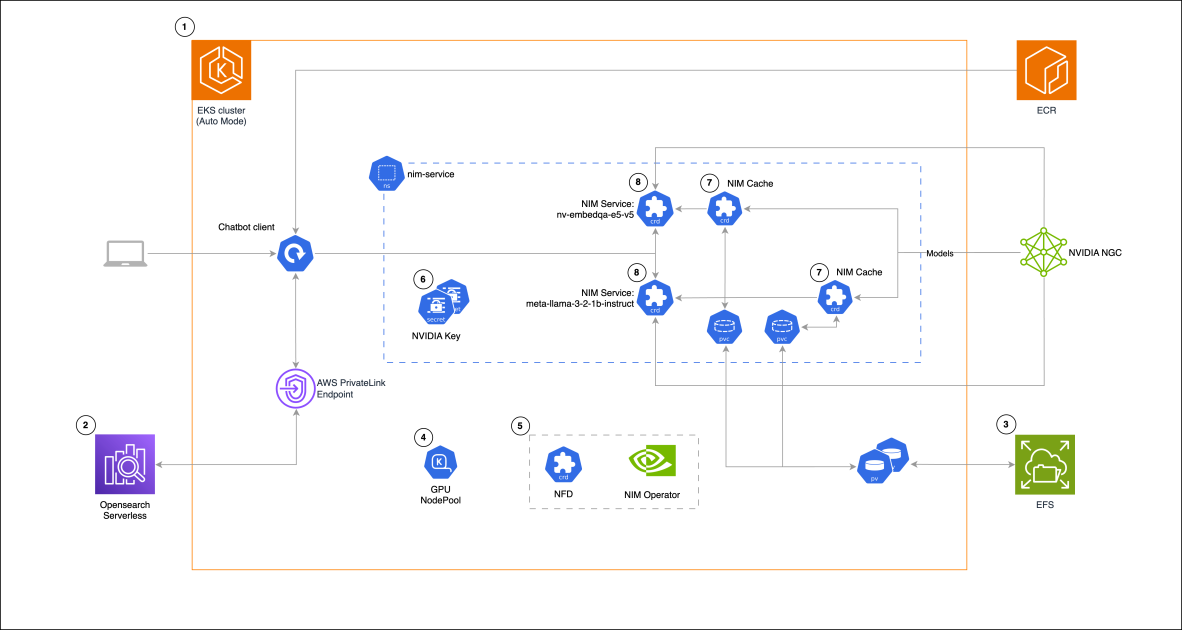
Building a RAG chat-based assistant on Amazon EKS Auto Mode and NVIDIA NIMs
In this post, we demonstrate the implementation of a practical RAG chat-based assistant using a comprehensive stack of modern technologies. The solution uses NVIDIA NIMs for both LLM inference and text embedding services, with the NIM Operator handling their deployment and management. The architectu

GPT-5 a déçu les attentes élevées mais améliore coût, rapidité et codage
Le lancement de GPT-5 a suscité des réactions mitigées : progrès incrémentaux aux benchmarks, coût et latence réduits, meilleure performance en codage, mais critiques sur le ton rédactionnel et des erreurs inattendues.

Introducing Amazon Bedrock AgentCore Gateway: Transforming enterprise AI agent tool development
In this post, we discuss Amazon Bedrock AgentCore Gateway, a fully managed service that revolutionizes how enterprises connect AI agents with tools and services by providing a centralized tool server with unified interface for agent-tool communication. The service offers key capabilities including S
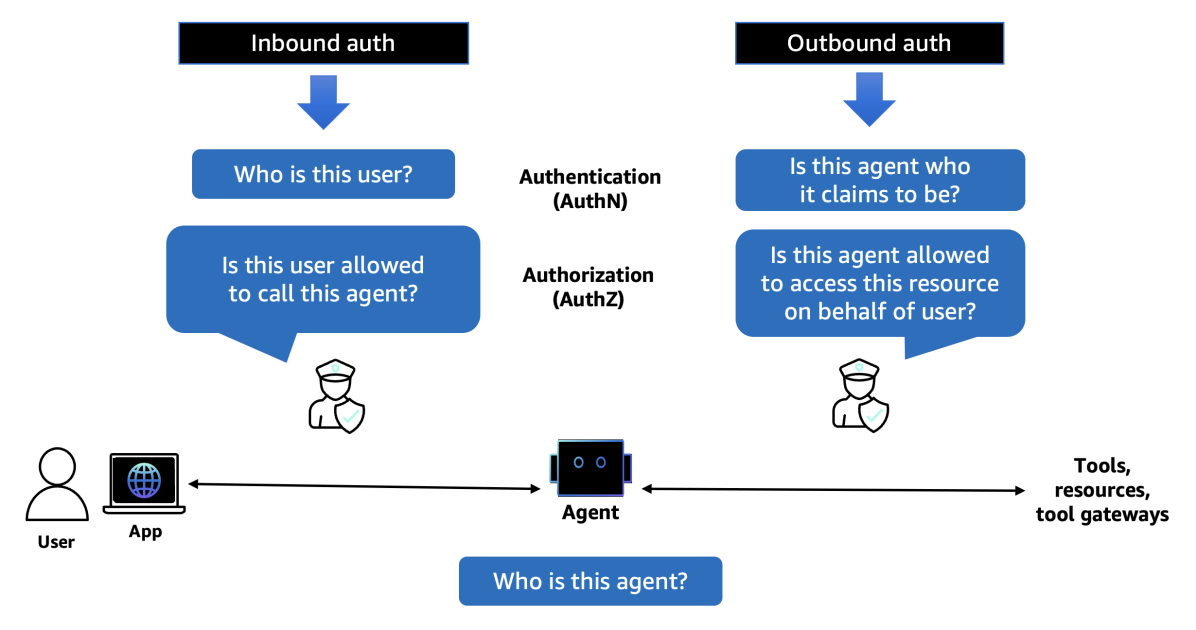
Introducing Amazon Bedrock AgentCore Identity: Securing agentic AI at scale
In this post, we explore Amazon Bedrock AgentCore Identity, a comprehensive identity and access management service purpose-built for AI agents that enables secure access to AWS resources and third-party tools. The service provides robust identity management features including agent identity director