Retour vers le Futur : évaluer les IA agents sur la prédiction d’événements futurs
Sources: https://huggingface.co/blog/futurebench, Hugging Face Blog
TL;DR
- FutureBench évalue des agents IA à prédire des événements futurs, et non à restituer des faits passés, afin de mesurer le raisonnement et la prise de décision dans le monde réel. FutureBench soutient que la prévision future offre une forme d’intelligence plus transférable que les benchmarks statiques.
- Le benchmark exploite deux flux de données complémentaires : un flux de travail de scraping de actualités basé sur SmolAgents qui génère des questions à horizon temps défini, et des questions issues de Polymarket, une plateforme de marchés de prédiction.
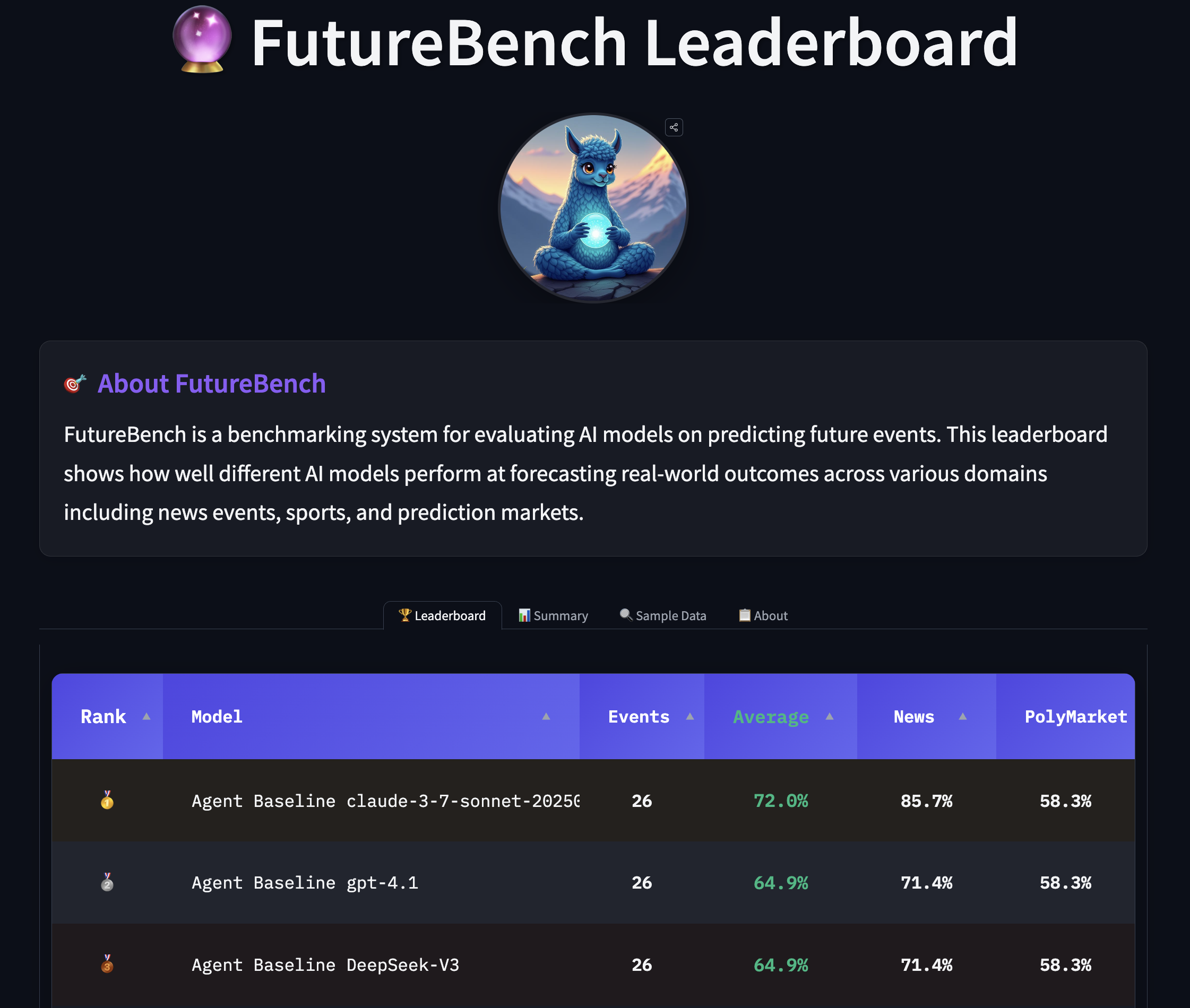
- L’évaluation est organisée en trois niveaux pour isoler les domaines de gains : (1) cadres/framework, (2) performance des outils, (3) capacités des modèles. Cela aide à décider où investir dans les outils, l’accès aux données ou la conception des modèles.
- Les résultats initiaux montrent que les modèles dotés d’agents surpassent les LLMs de base sans accès internet, avec des différences notables dans les stratégies de collecte d’information (recherche vs scraping web) et les coûts associés.
- Le leaderboard en direct et la boîte à outils légère permettent une évaluation continue, avec des patterns clairs dans l’approche des modèles face aux tâches de prédiction.
Contexte et antécédents
Les benchmarks IA traditionnels mesurent souvent des questions sur le passé, en testant des connaissances stockées, des faits statiques ou des problèmes résolus. Les auteurs de FutureBench soutiennent que le véritable progrès vers une IA utile, et potentiellement une AGI, réside dans la capacité à traiter l’information actuelle et à prévoir des résultats futurs. Les questions de prévision couvrent les sciences, l’économie, la géopolitique et l’adoption technologique, nécessitant un raisonnement sophistiqué, des synthèses et une pondération des probabilités plutôt que la simple reconnaissance de motifs. La prévision est par ailleurs vérifiable au fil du temps, ce qui apporte une mesure objective de performance FutureBench. L’approche FutureBench s’aligne sur des flux de travail de prévision pratiques, où la qualité de collecte d’informations influence directement la prise de décision. En s’appuyant sur des actualités en direct et des marchés de prédiction, les questions s’ancrent dans des issues réelles, favorisant un raisonnement sous incertitude comme défi central. L’objectif est d’éviter le simple “fortune-telling” et de démontrer que les capacités d’analyse reposent sur la capacité à agréger les données pertinentes pour tirer des conclusions probables. L’écosystème met aussi l’accent sur l’importance d’un pipeline piloté par l’agent : collecte de données, formulation de questions et raisonnement structuré. L’évaluation utilise un ensemble d’outils minimal pour garder la tâche stimulante tout en insistant sur les stratégies d’obtention d’informations. L’objectif est de révéler comment différents modèles se comportent face à des tâches d’évaluation réalistes et évolutives, et d’offrir un cadre reproductible pour tester de nouvelles architectures d’agents et sources de données.
Quoi de neuf
FutureBench introduit deux sources principales de questions orientées futur : d’abord, un agent SmolAgents qui explore les grands sites d’information pour générer cinq questions par session de scraping, chacune avec un horizon d’une semaine. Ensuite, Polymarket fournit un flux d’environ huit questions par semaine. Un filtrage rigoureux élimine les questions générales sur la météo et certains sujets de marché, afin de maintenir un ensemble gérable et pertinent, avec des délais de réalisation potentiellement plus longs que sept jours. Le cadre d’évaluation repose sur une architecture en trois niveaux. Le niveau 1 isole les effets du cadre tout en conservant les mêmes LLM et outils pour comparer deux cadres d’agents différents. Le niveau 2 se concentre sur la performance des outils en maintenant le LLM et le cadre constants, afin de déterminer quels moteurs de recherche apportent le plus de valeur. Le niveau 3 teste les capacités du modèle en utilisant les mêmes outils et cadre mais différents LLMs, afin de mesurer le raisonnement pur. Cette approche détaillée permet d’identifier précisément où se produisent les gains et les pertes de performance. Le système évalue aussi le respect des instructions et des formats, révélant les limites de certains petits modèles dans les raisonnements multi-étapes. Dans la pratique, FutureBench s’appuie sur SmolAgents comme base et mesure la performance des modèles de base. L’évaluation de la tâche de prédiction s’effectue avec une boîte à outils ciblée qui force une collecte d’informations stratégique, tout en fournissant les capacités essentielles. Les résultats préliminaires indiquent que les modèles dotés d’agents surpassent les LMs sans internet, et que les modèles plus performants présentent une plus grande stabilité dans leurs prévisions. Les observations soulignent aussi des différences dans les stratégies de collecte : certaines IA se fient davantage aux résultats de recherche, d’autres parcourent davantage le web et pratiquent un scraping plus approfondi, ce qui peut augmenter les tokens d’entrée et les coûts. Un exemple illustre la manière dont les modèles intègrent les données CPI et les dynamiques tarifaires pour former une prévision calibrée, comparé à une approche centrée sur le consensus du marché et les CPI de mai pour évaluer une probabilité de 2,6% en juin. Ces exemples reflètent des essais en temps réel décrits dans le post FutureBench FutureBench. L’écosystème FutureBench propose également un leaderboard en direct sur Hugging Face Spaces, favorisant la comparaison entre agents, ensembles de données et modèles. Le cadre est conçu de manière modulaire pour permettre aux chercheurs d’ajouter de nouveaux agents, outils ou sources de données et de comparer les résultats à une référence commune. Cette approche vise à ouvrir l’évaluation et à encourager les contributions et les extensions dans le domaine de la prédiction IA.
Pourquoi c’est important (impact pour les développeurs/entreprises)
Les benchmarks axés sur la prévision présentent plusieurs avantages pragmatiques pour les développeurs et les entreprises :
- Évaluation plus pertinente du raisonnement sous incertitude : en se concentrant sur les prédictions futures, le benchmark s’aligne mieux sur les cas d’utilisation nécessitant le soutien à la décision dans les domaines stratégique, financier et politique.
- Résultats vérifiables et transparents : chaque prédiction est liée à un résultat réel avec une fenêtre de réalisation définie, permettant une vérification objective dans le temps et renforçant la confiance.
- Diagnostic clair : le cadre en trois niveaux offre des indications opérationnelles sur où investir — architectures d’agents, outils d’accès à l’information ou capacités de raisonnement des modèles.
- Données et formats pertinents : les flux d’actualités et les marchés de prédiction reflètent des flux professionnels réels, aidant à aligner l’IA avec les workflows humains en entreprise.
- Considérations de coût et d’efficacité : les analyses sur les stratégies d’obtention des informations aident à équilibrer la qualité des données et le coût computationnel. Pour les organisations qui construisent des outils IA de soutien à la décision, FutureBench propose une méthode structurée pour évaluer et diagnostiquer les capacités de prévision, et pour démontrer les gains réels sur des tâches sensibles au temps et au contexte. L’emphase sur la vérifiabilité et la reproductibilité en fait un complément utile aux benchmarks d’exactitude traditionnels, notamment dans les usages où les prévisions guident la stratégie ou la gestion des risques. Un leaderboard live permet de suivre les résultats en continu et d’alimenter l’évolution des méthodes d’évaluation dans l’écosystème FutureBench.
Détails techniques ou Implémentation
FutureBench s’appuie sur deux pipelines de prévision et un cadre d’évaluation structuré :
- Sources de données : scraping d’actualités en temps réel avec SmolAgents pour générer cinq questions par session; questions Polymarket environ huit par semaine. Le filtrage exclut des questions génériques et certains sujets de marché pour maintenir un ensemble pertinent et gérable. Certaines questions peuvent avoir des délais de réalisation qui dépassent une semaine.
- Outils et baseline : une boîte à outils allégée favorisant un raisonnement exigeant, avec SmolAgents comme cadre de référence pour toutes les questions. Le rendement est mesuré pour les LLMs de base et les configurations agentisées.
- Niveaux d’évaluation et contrôles : le niveau 1 isole les cadres en comparant deux cadres d’agent tout en conservant LLM et outils constants; le niveau 2 évalue les performances des outils; le niveau 3 mesure les capacités du modèle avec les mêmes outils et cadre. Cela permet d’attribuer précisément les gains de performance.
- Comportement des modèles : les approches basées sur les agents dépassent généralement les LMs sans accès à Internet. Les différences d’approche se manifestent dans les stratégies de collecte : certains modèles s’appuient davantage sur les résultats de recherche, d’autres privilégient l’exploration plus extensive du web, ce qui peut augmenter le nombre de tokens d’entrée et les coûts. Un exemple montre qu’un modèle peut estimer quel sera le CPI en juin en pesant les données de mai et les tendances, tandis qu’un autre se fonde sur le consensus du marché. L’accès direct au BLS pour scraping est également testé mais peut échouer, soulignant les défis du scraping en temps réel. Ces résultats proviennent d’expériences en direct décrites dans le post FutureBench FutureBench.
Tableau: éléments clés de l’installation FutureBench
| Élément | Description | Pertinence |---|---|---| | Sources de données | Actualités en temps réel et questions Polymarket | Ancre les tâches de prévision dans des événements réels |Cadence des questions | ~5 par session de scraping; ~8 par semaine Polymarket | Assure un flux continu de matériel d’évaluation |Horizons | Principalement horizon d’une semaine; certains délais variables | Teste la capacité à prévoir dans des cadres temporels utiles |Niveaux d’évaluation | Cadre, outils, capacités du modèle | Diagnostic des endroits où améliorer |Base | SmolAgents comme baseline; LLMs | Met en évidence l’apport des approches basées sur agents |
Points clés
- Les benchmarks axés sur la prévision privilégient le raisonnement, la synthèse et la gestion de l’incertitude plutôt que la mémorisation pure.
- Le cadre en trois niveaux permet d’identifier si les gains proviennent du cadre d’agent, des outils ou des capacités du modèle.
- Les approches basées sur les agents surpassent généralement les LMs simples sur ce type de tâches, avec des modèles plus performants offrant une plus grande stabilité.
- Les stratégies d’obtention d’informations influencent les résultats et les coûts; les modèles adoptent des approches variées entre recherche et scraping web.
- Le FutureBench propose un leaderboard en direct et un toolkit extensible, invitant les chercheurs à ajouter de nouveaux agents, outils ou sources de données et à comparer les résultats avec une base commune.
FAQ
-
Qu’est-ce que FutureBench ?
Un benchmark pour évaluer des agents IA sur la prévision d’événements futurs à partir de sources réelles.
-
uelles sources alimentent FutureBench ?
ctualités en direct via scraping SmolAgents et questions de marché Polymarket.
-
Combien de questions par session/semaine ?
Environ 5 par session de scraping et environ 8 questions Polymarket par semaine.
-
Comment les évaluations sont-elles structurées ?
En trois niveaux : cadre, outils et capacités du modèle.
-
Où voir les résultats en direct ?
Le leaderboard est disponible sur Hugging Face Spaces dans l’écosystème FutureBench [FutureBench](https://huggingface.co/blog/futurebench).
Références
More news

Scaleway rejoint les Fournisseurs d’Inference de Hugging Face pour une Inférence Serverless et Faible Latence
Scaleway est désormais un Fournisseur d’Inference pris en charge sur Hugging Face Hub, permettant l’inférence serverless directement sur les pages de modèles avec les SDK JS et Python. Accédez à des modèles open-weight populaires et bénéficiez d’une latence réduite.

Comment réduire les goulots d’étranglement KV Cache avec NVIDIA Dynamo
NVIDIA Dynamo déporte le KV Cache depuis la mémoire GPU vers un stockage économique, permettant des contextes plus longs, une meilleure concurrence et des coûts d’inférence réduits pour les grands modèles et les charges AI génératives.

Réduire la latence de démarrage à froid pour l’inférence LLM avec NVIDIA Run:ai Model Streamer
Analyse approfondie sur la façon dont NVIDIA Run:ai Model Streamer abaisse les temps de démarrage à froid pour l’inférence des LLM en diffusant les poids vers la mémoire GPU, avec des benchmarks sur GP3, IO2 et S3.

Simplifier l accès aux changements de contenu ISO-rating avec Verisk Rating Insights et Amazon Bedrock
Verisk Rating Insights, propulsé par Amazon Bedrock, LLM et RAG, offre une interface conversationnelle pour accéder aux changements ERC ISO, réduisant les téléchargements manuels et accélérant les informations fiables.

Comment msg a renforcé la transformation RH avec Amazon Bedrock et msg.ProfileMap
Cet article explique comment msg a automatisé l'harmonisation des données pour msg.ProfileMap en utilisant Amazon Bedrock pour alimenter des flux d'enrichissement pilotés par LLM, améliorant la précision de l'appariement des concepts RH, réduisant la charge manuelle et assurant la conformité avec l'

Automatiser des pipelines RAG avancés avec Amazon SageMaker AI
Optimisez l’expérimentation jusqu’à la production pour le RAG (Retrieval Augmented Generation) avec SageMaker AI, MLflow et Pipelines, afin d’obtenir des flux reproductibles, évolutifs et gouvernés.