TinyAgent : appel de fonction à la périphérie avec de petits modèles linguistiques
Sources: http://bair.berkeley.edu/blog/2024/05/29/tiny-agent, bair.berkeley.edu
TL;DR
- Le déploiement en périphérie d’agents basés sur des LLM peut réduire les risques de vie privée et la latence en évitant l’inférence dans le cloud.
- TinyAgent démontre que des petits modèles de langage peuvent être entraînés pour exécuter des appels de fonction avec précision en périphérie.
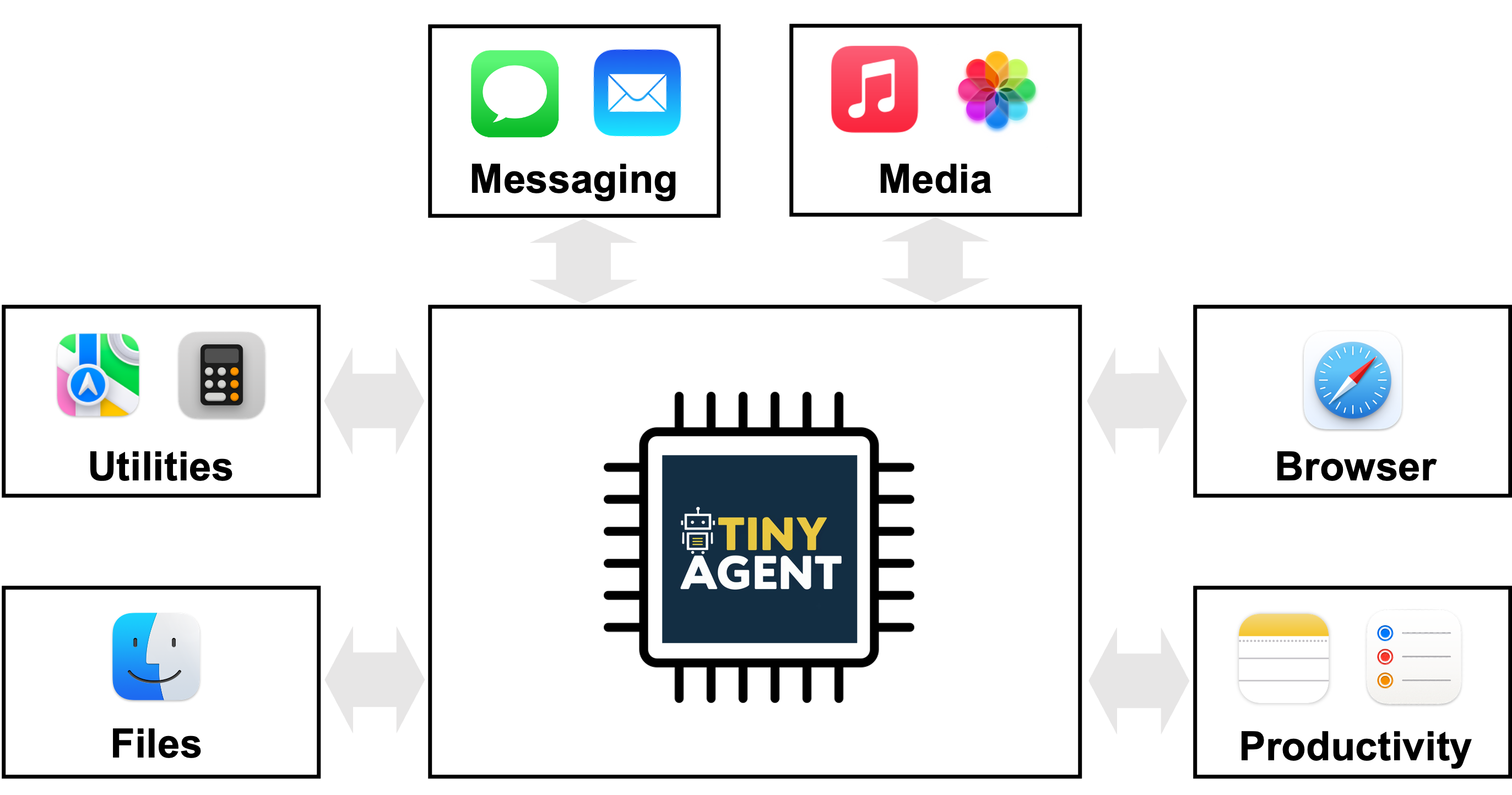
- Un assistant MacOS pilote utilise 16 fonctions pré-définies pour interagir avec des applications locales, démontré sur un MacBook avec Whisper-v3 fonctionnant localement.
- Les données d’entraînement sont synthétiques mais de haute qualité : 80k exemples d’entraînement, 1k validation, 1k test, générés avec GPT-4-Turbo; coût total d’environ 500 $.
- Le cadre, y compris LLMCompiler et la nouvelle méthode Tool RAG, permet une exécution en périphérie avec des réponses en temps réel et est open source sur GitHub. Source et GitHub.
Contexte et arrière-plan
Beaucoup de modèles de langage modernes peuvent exécuter des commandes en langage naturel en orchestrant un ensemble d’outils. Cette capacité a donné naissance à des systèmes agentisés capables de résoudre des requêtes utilisateur en coordonnant les API appropriées. Cependant, les plus grands modèles nécessitent souvent une inférence dans le cloud, ce qui soulève des questions de confidentialité lorsque des données (vidéo, audio, texte) sont envoyées à des tiers et dépend d’une connectivité stable. La latence peut aussi nuire au temps de réponse lorsque les données doivent être envoyées au cloud et en revenir. Ces défis freinent l’adoption des agents IA dans des environnements réels ou sensibles à la confidentialité. Cela motive l’intérêt pour déployer les LLM localement à la périphérie. Toutefois, des modèles volumineux comme GPT-4o ou Gemini-1.5 sont trop lourds pour tourner sur des appareils périphériques courants. De plus, une grande partie de leur taille est liée à la mémorisation de connaissances générales, qui peut ne pas être nécessaire pour des tâches spécialisées. L’objectif est de créer des Small Language Models (SLM) capables d’un raisonnement complexe pour appeler des fonctions, tout en étant déployables en edge de manière sécurisée et privée. Le projet TinyAgent explore cette direction via des données spécialisées et de haute qualité qui minimisent la nécessité de mémoriser des connaissances générales et favorisent l’orchestration d’outils et d’APIs. Pour plus de contexte, le billet BAIR décrit TinyAgent et ses objectifs. Source.
Nouvelles annonces
TinyAgent se concentre sur la capacité des petits modèles open-source à réaliser des appels de fonction précis comme cœur d’un agent en périphérie. Les éléments clés incluent :
- Défi : les petits modèles prêts à l’emploi (p. ex. TinyLLaMA-1.1B, Wizard-2-7B) démontrent des capacités très faibles à produire des plans d’appels de fonction corrects.
- Solution : curer des données de haute qualité pour l’appel de fonction et la planification, avec une application MacOS qui dispose de scripts Apple pré-définis comme domaine cible.
- Stratégie de données : générer des données synthétiques via un LLM compétent (GPT-4-Turbo) pour créer des requêtes utilisateur réalistes nécessitant ces fonctions et le plan d’appel correspondant, puis effectuer des vérifications de sanité pour assurer la faisabilité du graphe et l’exactitude des noms et types d’arguments.
- Échelle et résultats : 80 000 exemples d’entraînement, 1 000 de validation et 1 000 de test, coût total d’environ 500 $.
- Impact sur les modèles : un affinement des petits modèles sur ces données peut surpasser les performances de GPT-4-Turbo sur la tâche d’appel de fonction. Une nouvelle méthode Tool RAG peut renforcer encore l’efficacité.
- Démo : TinyAgent-1B et Whisper-v3 fonctionnent localement sur un MacBook M3 Pro. Le cadre est open source sur GitHub. Un composant central est LLMCompiler, un planificateur d’appel de fonction qui comprend la requête de l’utilisateur et génère une séquence de tâches avec leurs dépendances. Le plan est ensuite exécuté en dispatchant les appels de fonction dans le bon ordre, les variables étant remplacées par les résultats au fur et à mesure. Cette approche privilégie l’orchestration des fonctions plutôt que l’écriture d’une définition de fonction nouvelle. Source.
Pourquoi cela compte (impact pour les développeurs/entreprises)
- Vie privée et fonctionnement hors ligne : le déploiement en bordure réduit le besoin d’envoyer des données vers le cloud, ce qui répond à des préoccupations de confidentialité.
- Latence et fiabilité : l’exécution locale peut offrir des temps de réponse plus rapides et une opération sans connectivité constante.
- Spécialisation plutôt que mémorisation : TinyAgent montre qu’un petit modèle peut être entraîné pour un raisonnement robuste autour de l’invocation d’outils, sans dépendre de connaissances générales mémorisées.
- Écosystème ouvert : le projet est open source, permettant à des chercheurs et développeurs d’adapter l’approche à leurs ensembles d’outils et à leur matériel périphérique. TinyAgent illustre une voie concrète vers des agents IA nés pour bordure qui orchestrent outils et APIs, en mettant l’accent sur des données de haute qualité et sur un entraînement ciblé. Source.
Détails techniques ou Mise en œuvre
TinyAgent vise à permettre à des modèles ouverts et petits de réaliser des appels de fonction précis en apprenant à générer un plan d’appel de fonction avec la syntaxe correcte, les arguments d’entrée et les dépendances entre appels. Les éléments clés incluent :
- LLMCompiler : le planificateur qui comprend la requête et produit une séquence de tâches avec leurs dépendances et les appels de fonction à effectuer. Le plan est interprété et exécuté dans l’ordre, en remplaçant les variables par les résultats réels au fur et à mesure.
- Le défi des petits modèles : les petits modèles prêts à l’emploi ne produisent pas des plans corrects.
- Approche de données : générer des données synthétiques avec un LLM compétent pour produire des requêtes utilisateur réalistes et leurs plans d’appel associés, orientés vers le domaine MacOS.
- Validation : des vérifications de sanité garantissent que le DAG des appels est faisable et que les noms de fonctions et les types d’arguments sont corrects.
- Ensemble de données et coût : 80k entraînement, 1k validation, 1k test, coût ~US$500.
- Performance et amélioration : le fine-tuning sur ces données peut surpasser les grands modèles sur la tâche d’appel de fonction. Tool RAG est proposé pour accroître l’efficacité.
- Démo matérielle : TinyAgent-1B et Whisper-v3 tournent localement sur un MacBook M3 Pro. Le projet est open source sur https://github.com/SqueezeAILab/TinyAgent. Le flux de travail de données consiste à donner au LLM des ensembles variés de fonctions et à lui demander de générer des requêtes utilisateur qui nécessitent ces fonctions, ainsi que le plan d’appel et les arguments associés. Des vérifications garantissent que le DAG d’appels est faisable et que les noms de fonctions et les types d’arguments correspondent. Cela produit des données d’entraînement axées sur la sélection correcte des fonctions, l’extraction des arguments et l’enchaînement approprié des appels. Source. Tableau rapide : comparaison entre les petits LMs et les baselines de grands modèles dans le contexte des appels de fonction | Type de modèle | Capacité d’appel de fonction (selon l’étude) | Notes |--- |--- |--- |Modèles petits prêts à l’emploi (pas. TinyLLaMA-1.1B, Wizard-2-7B) | Très faible ; incapables de générer des plans d’appel corrects | Amélioration via des données de haute qualité et un ajustement ciblé |Modèles grandes tailles (GPT-4-Turbo, autres) | Capables d’appeler des fonctions | Utilisé comme référence; l’infrastructure repose souvent sur l’inférence cloud | L’approche TinyAgent montre qu’avec une curation soignée des données et un entraînement ciblé, des modèles petits peuvent atteindre des performances robustes sur la tâche d’appel de fonction, et des outils comme Tool RAG peuvent augmenter encore l’efficacité. Le cadre est open source. Source.
Points clés
- L’IA orientée périphérie est réalisable pour les appels de fonction avec des petits modèles quand on s’appuie sur des données bien ciblées.
- Le fine-tuning sur des données curées permet à des modèles petits de dépasser des baselines plus grandes dans cette tâche spécifique.
- Un planificateur dédié (LLMCompiler) transforme l’intention de l’utilisateur en une séquence d’appels de fonction dépendants.
- Tool RAG et méthodes associées peuvent améliorer l’efficacité et la latence pour les déploiements en périphérie.
- TinyAgent est open source et démontre un raisonnement en temps réel sur appareil avec intégration MacOS et inférence locale Whisper-v3.
FAQ
-
- **Q : Qu’est-ce que TinyAgent ?**
C’est un effort de recherche pour permettre à de petits modèles de langage d’effectuer des appels de fonction avec précision pour un déploiement en périphérie, en utilisant un ensemble de fonctions MacOS pré-définies et le planificateur LLMCompiler. [Source](http://bair.berkeley.edu/blog/2024/05/29/tiny-agent). - **Q : Comment les données sont-elles générées pour l’entraînement ?** **A :** Un LLM compétent (GPT-4-Turbo) génère des requêtes utilisateur réalistes et les plans d’appel correspondants, avec des vérifications de sanité pour assurer faisabilité et exactitude des noms et types d’arguments. 80k exemples d’entraînement, 1k validation et 1k test ont été produits pour environ 500 $. [Source](http://bair.berkeley.edu/blog/2024/05/29/tiny-agent). - **Q : Comment TinyAgent se compare-t-il à GPT-4-Turbo pour l’appel de fonction ?** **A :** Le fine-tuning de petits modèles sur ces données peut les dépasser dans la tâche ciblée d’appel de fonction. [Source](http://bair.berkeley.edu/blog/2024/05/29/tiny-agent). - **Q : Quel matériel a été utilisé pour la démonstration ?** **A :** TinyAgent-1B avec Whisper-v3 tourne localement sur un MacBook M3 Pro. [Source](http://bair.berkeley.edu/blog/2024/05/29/tiny-agent). - **Q : Où trouver le code ?** **A :** Le projet est open source sur GitHub : https://github.com/SqueezeAILab/TinyAgent. [Source](http://bair.berkeley.edu/blog/2024/05/29/tiny-agent).
Références
- TinyAgent : Function Calling at the Edge — BAIR Blog. http://bair.berkeley.edu/blog/2024/05/29/tiny-agent
- Dépôt GitHub TinyAgent. https://github.com/SqueezeAILab/TinyAgent
More news

Scaleway rejoint les Fournisseurs d’Inference de Hugging Face pour une Inférence Serverless et Faible Latence
Scaleway est désormais un Fournisseur d’Inference pris en charge sur Hugging Face Hub, permettant l’inférence serverless directement sur les pages de modèles avec les SDK JS et Python. Accédez à des modèles open-weight populaires et bénéficiez d’une latence réduite.

Prévoir les phénomènes météorologiques extrêmes en quelques minutes sans superordinateur : Huge Ensembles (HENS)
NVIDIA et le Lawrence Berkeley National Laboratory présentent Huge Ensembles (HENS), un outil IA open source qui prévoit des événements météorologiques rares et à fort impact sur 27 000 années de données, avec des options open source ou prêtes à l’emploi.

Comment réduire les goulots d’étranglement KV Cache avec NVIDIA Dynamo
NVIDIA Dynamo déporte le KV Cache depuis la mémoire GPU vers un stockage économique, permettant des contextes plus longs, une meilleure concurrence et des coûts d’inférence réduits pour les grands modèles et les charges AI génératives.

Créer des flux de travail agentiques avec GPT OSS d’OpenAI sur SageMaker AI et Bedrock AgentCore
Vue d’ensemble complète sur le déploiement des modèles GPT OSS d’OpenAI sur SageMaker AI et Bedrock AgentCore pour alimenter un analyseur d’actions multi-agents avec LangGraph, incluant la quantification MXFP4 en 4 bits et une orchestration sans serveur.

Autodesk Research mène la CFD à vitesse Warp sur le NVIDIA GH200
Autodesk Research, Warp de NVIDIA et le GH200 démontrent une CFD Python-native avec XLB, atteignant environ 8x de vitesse et évoluant jusqu’à 50 milliards de cellules.

Réduire la latence de démarrage à froid pour l’inférence LLM avec NVIDIA Run:ai Model Streamer
Analyse approfondie sur la façon dont NVIDIA Run:ai Model Streamer abaisse les temps de démarrage à froid pour l’inférence des LLM en diffusant les poids vers la mémoire GPU, avec des benchmarks sur GP3, IO2 et S3.