xT : Modélisation de grandes images avec tokenisation imbriquée
Sources: http://bair.berkeley.edu/blog/2024/03/21/xt, bair.berkeley.edu
TL;DR
- xT introduit une tokenisation imbriquée pour gérer des images extrêmement grandes en les divisant en régions et en les traitant avec des encodeurs de région, puis un encodeur de contexte qui rapproche les pièces.
- Il permet une modélisation end‑to‑end sur des GPU modernes, en traitant des images jusqu’à 29 000 × 25 000 pixels sur des A100 de 40 Go, bien au-delà de ce que les approches de référence peuvent gérer.
- L’architecture combine des encodeurs régionaux (experts locaux) et un encodeur de contexte (intégrateur global), utilisant des transformeurs de longue séquence pour capturer des dépendances distantes sans sacrifier les détails.
- Il obtient de meilleures performances sur des tâches en aval (p. ex., iNaturalist 2018, xView3-SAR, MS-COCO) avec moins de paramètres et une mémoire par région moindre que les baselines.
- Le travail est documenté dans un billet BAIR et un article arXiv complet, avec une page de projet reliant le code et les poids libérés.
Contexte et arrière-plan
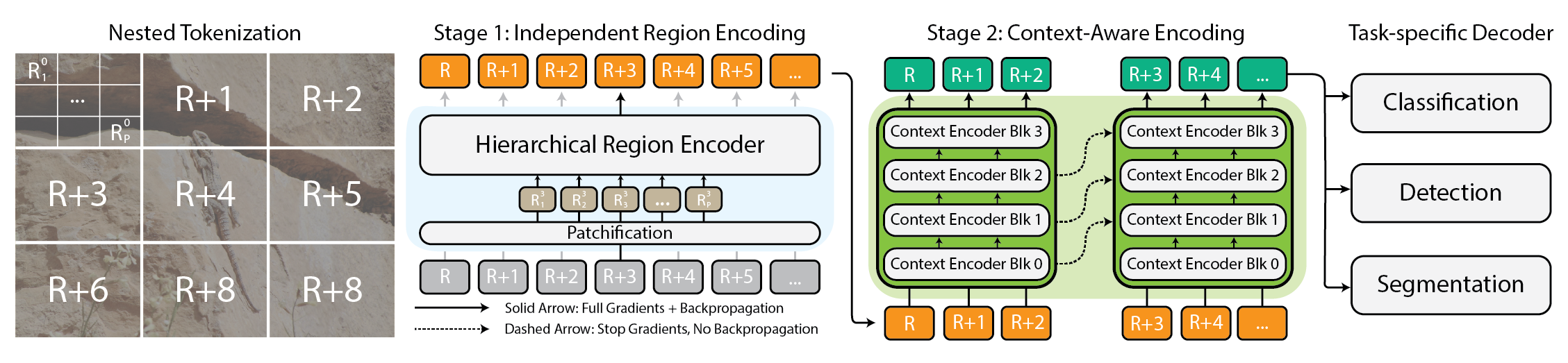
Les images haute résolution sont de plus en plus répandues, des caméras grand public aux images satellites, mais les modèles de vision modernes peinent à suivre lorsque la taille de l’image augmente. L’utilisation de la mémoire tend à croître quadratiquement avec la taille de l’image, ce qui pousse à réduire ou à rogner l’image. Cela entraîne des pertes substantielles d’information et de contexte global, rendant difficile la compréhension à la fois de la scène globale et des détails fins. Les auteurs soutiennent que chaque pixel porte une information et proposent un changement de paradigme : traiter les grandes images comme une hiérarchie de parties gérables analysées localement et globalement. L’idée centrale est une tokenisation imbriquée où l’image est divisée en régions pouvant être subdivisées selon le besoin, avant d’être patchifiée pour être traitée par le backbone de vision. Source.
Ce qui est nouveau
xT propose une architecture scalable pour modéliser des images extrêmement grandes end-to-end grâce à une tokenisation imbriquée et à deux types d’encodeurs :
- L’encodeur de région : un « expert local » qui convertit chaque région en une représentation détaillée. Les régions sont traitées isolément et l’encodeur de région peut être n’importe quel backbone de pointe (par exemple Swin, Hiera, ConvNeXt).
- L’encodeur de contexte : un modèle de longue séquence qui assemble les représentations régionales pour assurer que les informations d’un token sont considérées dans le contexte des autres. Les chercheurs utilisent Transformer-XL et une variante appelée Hyper, ainsi que Mamba; des modèles à longue séquence conçus à l’origine pour le langage peuvent être efficaces pour la vision. Cette combinaison de tokenisation imbriquée, d’encoders locaux et d’un encoder global permet le traitement end-to-end d’images massives sur des GPUs modernes, sans compromettre le contexte global.
Pourquoi c’est important (impact pour les développeurs/entreprises)
Gérer des images ultra-grandes sans perdre le contexte global ouvre des possibilités dans des domaines qui exigent à la fois une vue d’ensemble et des détails fins. En surveillance environnementale, les scientifiques peuvent suivre des changements à travers de vastes paysages tout en examinant des zones d’intérêt spécifiques. En santé, le diagnostic d’images peut bénéficier de l’analyse de lames larges sans négliger les détails microscopiques. Éviter les réductions agressives de résolution ou les recadrages permet des représentations plus fidèles et peut améliorer les tâches en aval dépendantes du contexte et du détail.
Détails techniques ou Mise en œuvre
- Architecture : tokenisation imbriquée qui divise l’image en régions, pouvant être subdivisées, puis patchifiée pour le traitement par l’encodeur de région. L’encodeur de région agit comme un extracteur de caractéristiques locales.
- Encodeurs : les encodeurs de région peuvent être Swin, Hiera, ConvNeXt, etc. Les encodeurs de contexte utilisent des modèles de longue séquence (Transformer-XL et variantes comme Hyper et Mamba) ; le Longformer est mentionné comme option potentielle.
- Capacité end-to-end : xT peut modéliser des images extrêmement grandes end-to-end sur des GPUs modernes.
- Benchmarks et échelle : évaluations sur iNaturalist 2018 (classification fine), xView3-SAR (segmentation dépendante du contexte) et MS-COCO (détection).
- Utilisation des ressources : meilleure précision avec moins de paramètres et mémoire par région par rapport aux baselines. Démonstration clé : modéliser des images jusqu’à 29 000 × 25 000 pixels sur 40 Go A100, les baselines équivalentes se heurtant à la mémoire à des tailles bien plus petites. La page de projet propose le code et les poids libérés. Source
- Disponibilité : le traitement complet est publié sur arXiv, et la page du projet lie le code et les poids libérés. Source
Points à retenir
- La tokenisation imbriquée permet de décomposer des images très grandes en parties gérables sans perdre le contexte global.
- Une architecture en deux volets (encodeurs de région + encodeur de contexte) offre de meilleures performances avec moins de mémoire par région.
- Les modèles de longue séquence peuvent être réutilisés pour agréger les informations entre des régions éloignées d’une image.
- L’approche permet un traitement end-to-end sur des GPUs existants, élargissant la faisabilité de l’analyse d’images gigapixel dans la recherche et les applications.
- Les résultats sur plusieurs benchmarks indiquent une voie pratique pour analyser des images extrêmement grandes dans des domaines comme la surveillance environnementale et la santé.
FAQ
-
Comment xT gère des images extrêmement grandes sans réduction ni recadrage ?
En utilisant une tokenisation imbriquée qui divise l’image en régions, en traitant chaque région avec un encodeur local et en utilisant un encodeur de contexte pour fusionner les régions.
-
Quels modèles pour les encodeurs de région et de contexte ?
Les encodeurs de région peuvent être Swin, Hiera, ConvNeXt; les encodeurs de contexte utilisent des variantes de Transformer-XL (Hyper, Mamba), Longformer est mentionné comme option.
-
Quel matériel a été utilisé pour les images à grande échelle ?
Images jusqu’à 29 000 × 25 000 pixels sur 40 Go d’A100, avec des baselines qui manquent de mémoire à des tailles bien plus petites.
-
Sur quelles tâches xT a-t-il été évalué ?
iNaturalist 2018, xView3-SAR et MS-COCO.
Références
More news

NVIDIA HGX B200 réduit l’intensité des émissions de carbone incorporé
Le HGX B200 de NVIDIA abaisse l’intensité des émissions de carbone incorporé de 24% par rapport au HGX H100, tout en offrant de meilleures performances IA et une efficacité énergétique accrue. Cet article résume les données PCF et les nouveautés matérielles.

Comment réduire les goulots d’étranglement KV Cache avec NVIDIA Dynamo
NVIDIA Dynamo déporte le KV Cache depuis la mémoire GPU vers un stockage économique, permettant des contextes plus longs, une meilleure concurrence et des coûts d’inférence réduits pour les grands modèles et les charges AI génératives.

Le Playbook des Grands Maîtres Kaggle: 7 Techniques de Modélisation pour Données Tabulaires
Analyse approfondie de sept techniques éprouvées par les Grands Maîtres Kaggle pour résoudre rapidement des ensembles de données tabulaires à l’aide d’une accélération GPU, des baselines divers à l’assemblage et à la pseudo-étiquetage.

Microsoft transforme le site Foxconn en data center Fairwater AI, présenté comme le plus puissant au monde
Microsoft dévoile des plans pour un data center Fairwater AI de 1,2 million de mètres carrés au Wisconsin, abritant des centaines de milliers de GPU Nvidia GB200. Le projet de 3,3 milliards de dollars promet un entraînement IA sans précédent.

NVIDIA RAPIDS 25.08 Ajoute un Nouveau Profiler pour cuML, Améliorations du moteur GPU Polars et Support d’Algorithmes Étendu
RAPIDS 25.08 introduit deux profils pour cuml.accel (fonctionnel et ligne), l’exécuteur streaming par défaut du moteur Polars GPU, un support de types et chaînes étendu, Spectral Embedding dans cuML et des accélérations zéro-code pour plusieurs estimateurs.

Créer des flux de travail agentiques avec GPT OSS d’OpenAI sur SageMaker AI et Bedrock AgentCore
Vue d’ensemble complète sur le déploiement des modèles GPT OSS d’OpenAI sur SageMaker AI et Bedrock AgentCore pour alimenter un analyseur d’actions multi-agents avec LangGraph, incluant la quantification MXFP4 en 4 bits et une orchestration sans serveur.