Programar cargas de trabajo sensibles a la topología con SageMaker HyperPod
Sources: https://aws.amazon.com/blogs/machine-learning/schedule-topology-aware-workloads-using-amazon-sagemaker-hyperpod-task-governance, https://aws.amazon.com/blogs/machine-learning/schedule-topology-aware-workloads-using-amazon-sagemaker-hyperpod-task-governance/, AWS ML Blog
TL;DR
- AWS anunció la programación sensible a la topología como una nueva capacidad de la gobernanza de tareas SageMaker HyperPod para optimizar la eficiencia de entrenamiento y la latencia de red en clústeres Amazon EKS.
- Este enfoque aprovecha la información de topología EC2 para ubicar tareas de entrenamiento interconectadas dentro de los mismos nodos y capas de red, reduciendo saltos de red y latencia.
- Existen dos métodos principales para enviar cargas sensibles a la topología: anotar manifiestos de Kubernetes con una anotación topológica y usar la CLI de SageMaker HyperPod con banderas relacionadas con la topología.
- El flujo de trabajo incluye confirmar la información de topología, identificar los nodos que comparten capas de red y enviar tareas de entrenamiento sensibles a la topología para obtener mayor visibilidad y control sobre la ubicación.
- El artículo ofrece pasos prácticos, un vistazo a la topología e invita a los usuarios a dejar comentarios.
Contexto e antecedentes
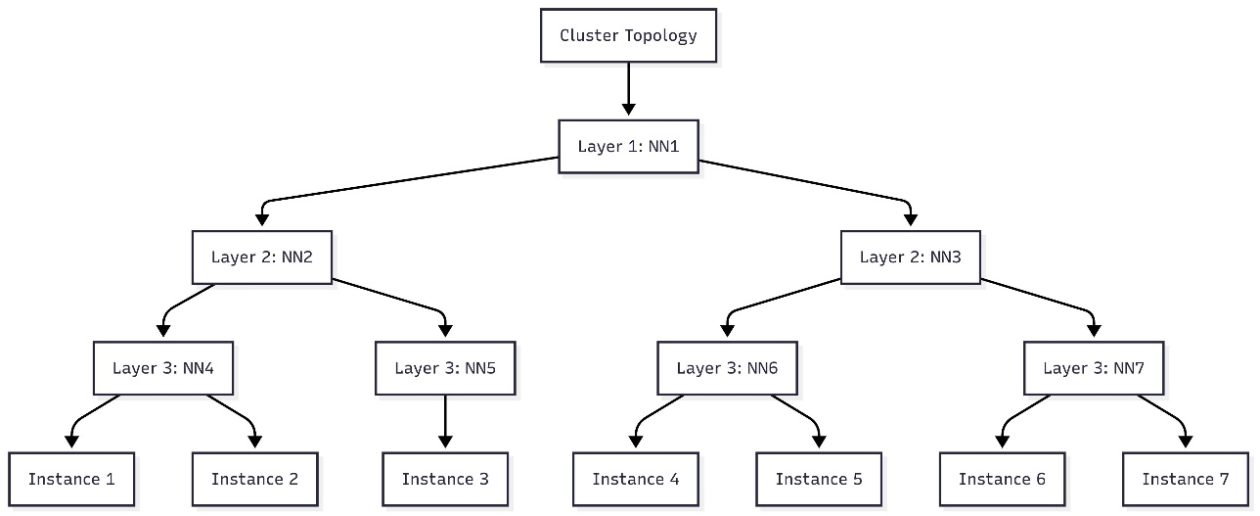
Las cargas de trabajo de IA generativa suelen requerir una comunicación extensa entre nodos EC2. En estos entornos, la latencia de red está influenciada por cómo se organizan física y lógicamente las instancias dentro de una topología de centro de datos jerárquica. AWS describe los centros de datos como conjuntos de unidades organizativas anidadas, como nodos de red y conjuntos de nodos, con varias instancias por nodo y varios nodos por conjunto. Las instancias que comparten nodos de red cercanos tienden a tener tiempos de procesamiento más rápidos debido a menos saltos de red. Para optimizar la colocación de cargas de IA en clústeres de SageMaker HyperPod, se pueden incorporar las informaciones de topología EC2 al enviar trabajos. La topología de una instancia EC2 se describe mediante un conjunto de nodos, con un nodo en cada capa de la red. La topología se organiza en capas y compartir capas informa sobre proximidad y eficiencia de la comunicación. Las etiquetas de topología de red permiten la planificación sensible a la topología para mejorar la eficiencia de las tareas y la utilización de recursos. En este contexto, la gobernanza de tareas de SageMaker HyperPod amplía la capacidad de gobernanza para la asignación acelerada de recursos y la aplicación de políticas de prioridad entre equipos y proyectos en clústeres EKS. Esta gobernanza ayuda a los administradores a alinear la asignación de recursos con las prioridades organizacionales, permitiendo acelerar la innovación en IA y reducir el tiempo de comercialización al minimizar la coordinación para aprovisionar recursos y replantear tareas. Para orientación adicional, AWS señala mejores prácticas para SageMaker HyperPod.
Novedades
Este artículo introduce la programación sensible a la topología como una capacidad de la SageMaker HyperPod Task Governance, con el objetivo de optimizar la eficiencia de entrenamiento y el rendimiento de red al considerar la disposición física y lógica de los recursos en el clúster. Puntos clave:
- La programación sensible a la topología utiliza información de topología EC2 para orientar la ubicación de trabajos, con instancias que comparten las mismas capas de red acercándose entre sí.
- Los administradores pueden gobernar la asignación acelerada de recursos y aplicar políticas de prioridad para mejorar la utilización de recursos.
- Los científicos de datos interactúan con clústeres SageMaker HyperPod para garantizar capacidad y permisos cuando trabajan con recursos de GPU.
- El enfoque admite dos métodos de envío y un flujo de trabajo alternativo, proporcionando flexibilidad para diferentes equipos y flujos de trabajo.
Dos métodos principales de envío (con un flujo alternativo)
- Anotación en manifiestos de Kubernetes: añadir la anotación de topología kueue.x-k8s.io/podset-required-topology para programar pods que compartan la misma capa 3 de red. Para verificar la asignación de pods, use:
- kubectl get pods -n hyperpod-ns-team-a -o wide
- CLI de SageMaker HyperPod: enviar trabajos a través de la CLI de HyperPod usando —preferred-topology o —required-topology al crear un job. Se proporciona un ejemplo para iniciar un entrenamiento MNIST sensible a la topología con un marcador de ID de cuenta de AWS (XXXXXXXXXXXX). El artículo también señala consideraciones prácticas si se han desplegado nuevos recursos y remarca la sección de Limpieza en el taller SageMaker HyperPod EKS para evitar cargos no deseados. Se enfatiza que el entrenamiento de grandes modelos de lenguaje (LLMs) implica comunicación entre pods y que la topología sensible puede mejorar el rendimiento y la latencia.
Cómo empezar
Para comenzar, debe:
- Confirmar la información de topología de todos los nodos de su clúster.
- Ejecutar un script para identificar qué nodos comparten capas de red entre las capas 1–3.
- Programar tareas de entrenamiento sensibles a la topología en su clúster utilizando cualquiera de los métodos de envío. Este flujo de trabajo busca proporcionar mayor visibilidad y control sobre la ubicación de las tareas de entrenamiento, lo que puede traducirse en un rendimiento más predecible para cargas de trabajo distribuidas de IA. El artículo señala que las etiquetas de topología de red ayudan a lograr estos beneficios y propone visualizaciones (a través de Mermaid.js.org) para facilitar la comprensión de la topología.
Por qué importa (impacto para desarrolladores/empresas)
La programación sensible a la topología aborda un factor crítico de rendimiento para el entrenamiento distribuido de IA: la comunicación entre nodos. Para entrenamientos distribuidos y, en particular, para modelos grandes, reducir los saltos de red entre GPUs en nodos diferentes puede disminuir el tiempo de entrenamiento y la latencia de sincronización. Al incorporar información de topología EC2 en el SageMaker HyperPod Task Governance, las organizaciones pueden:
- Mejorar la utilización de recursos alineando la ubicación computacional con la proximidad de red.
- Simplificar la gobernanza de la asignación de recursos acelerados entre equipos y proyectos.
- Acelerar el time-to-market de innovaciones en IA al reducir la coordinación necesaria para aprovisionar recursos y replantear tareas.
- Proporcionar a los científicos de datos una mayor visibilidad sobre dónde se ejecutarán sus tareas, facilitando la experimentación y la optimización. Estas capacidades son especialmente útiles para entrenamientos distribuidos de gran escala, donde la comunicación entre pods es frecuente. La gobernanza busca equilibrar rendimiento (colocación topológica) con control administrativo (políticas de prioridad y gobernanza de recursos).
Detalles técnicos o Implementación
Prerrequisitos y configuración:
- Comience por mostrar etiquetas de topología de los nodos en su clúster. Etiquetas comunes incluyen topology.k8s.aws/network-node-layer-3; una salida de ejemplo puede mostrar topology.k8s.aws/network-node-layer-3: nn-33333example, revelando cómo las instancias están organizadas por capas.
- Use un script para identificar qué nodos comparten capas de red entre los niveles 1–3. La salida puede usarse para construir una visualización de topología (por ejemplo, en Mermaid.js.org).
- El artículo propone dos caminos prácticos para enviar cargas sensibles a la topología:
- Annotación en manifests de Kubernetes: agregue la anotación kueue.x-k8s.io/podset-required-topology para programar pods que compartan la misma capa 3 de red.
- CLI de SageMaker HyperPod: use la CLI HyperPod con —preferred-topology o —required-topology al crear un job. Este enfoque permite un plan de colocación basado en topología dentro de la gobernanza HyperPod.
- Verificación de la ubicación: después de lanzar los pods, verifique la asignación de nodos con el comando kubectl get pods -n hyperpod-ns-team-a -o wide.
- El artículo proporciona un ejemplo de comando para iniciar un entrenamiento MNIST sensible a la topología a través de la CLI HyperPod, sustituyendo XXXXXXXXXXXX por el ID de su cuenta AWS. El objetivo es ilustrar el flujo de la CLI, aunque el comando exacto no está reproducido aquí. Notas prácticas:
- Si despliega nuevos recursos al adoptar la planificación sensible a la topología, siga las recomendaciones de Limpieza en el workshop SageMaker HyperPod EKS para evitar cargos no deseados.
- Este enfoque es particularmente relevante para entrenamientos de grandes modelos de lenguaje (LLMs), donde la comunicación entre pods es frecuente.
- AWS destaca que la planificación sensible a la topología puede proporcionar mayor visibilidad y control sobre la colocación de entrenamientos, lo que puede traducirse en un rendimiento más predecible para cargas de trabajo distribuidas de IA.
Ejemplo práctico y visualización
El flujo incluye la generación de un diagrama de flujo que muestra cómo los nodos se relacionan entre las capas 1–3. Puedes visualizar esta topología en herramientas como Mermaid.js.org para planificar la colocación de pods antes de enviar tareas sensibles a la topología. El cluster de ejemplo del artículo demuestra cómo siete instancias se asignan a la topología jerárquica e informan decisiones sobre las capas de red compartidas.
Consideraciones al implementar
- Decide entre el enfoque basado en manifiestos o el enfoque CLI, según tu flujo de trabajo y automatización.
- Asegúrate de que tu equipo tenga permisos para interactuar con el clúster SageMaker HyperPod y para anotar recursos de Kubernetes.
- Planifica un monitoreo continuo de la colocación por topología y métricas de desempeño para validar mejoras en throughput y latencia.
Conclusiones clave
- SageMaker HyperPod Task Governance ahora admite la planificación sensible a la topología para mejorar la eficiencia del entrenamiento y la latencia de la red.
- Puedes implementar esta planificación vía anotaciones en manifiestos de Kubernetes o vía CLI HyperPod, ofreciendo flexibilidad para diferentes equipos.
- El uso de información de topología EC2 guía el placement de pods para reducir la comunicación entre nodos y optimizar recursos.
- Este flujo de trabajo proporciona mayor visibilidad y control sobre la colocación de tareas de entrenamiento, con un desempeño más predecible para cargas de IA distribuidas.
- Es especialmente beneficioso para entrenamientos distribuidos de gran escala, donde la comunicación entre pods es frecuente.
Preguntas Frecuentes
Referencias
More news

Llevar agentes de IA de concepto a producción con Amazon Bedrock AgentCore
Análisis detallado de cómo Amazon Bedrock AgentCore facilita la transición de aplicaciones de IA basadas en agentes desde un concepto de prueba hasta sistemas de producción empresariales, conservando memoria, seguridad, observabilidad y gestión escalable de herramientas.

Monitorear la inferencia por lotes de Bedrock de AWS con métricas de CloudWatch
Descubra cómo monitorear y optimizar trabajos de inferencia por lotes de Bedrock con métricas, alarmas y paneles de CloudWatch para mejorar rendimiento, costos y operación.

Solicitando precisión con Stability AI Image Services en Amazon Bedrock
Bedrock incorpora Stability AI Image Services con nueve herramientas para crear y editar imágenes con mayor precisión. Descubre técnicas de prompting para uso empresarial.

Escala la producción visual con Stability AI Image Services en Amazon Bedrock
Stability AI Image Services ya está disponible en Amazon Bedrock, ofreciendo capacidades de edición de imágenes listas para usar a través de la API de Bedrock y ampliando los modelos Stable Diffusion 3.5 y Stable Image Core/Ultra ya presentes.

Usar AWS Deep Learning Containers con Amazon SageMaker AI MLflow gestionado
Vea cómo los AWS Deep Learning Containers (DLCs) se integran con SageMaker AI gestionado por MLflow para equilibrar el control de la infraestructura y una gobernanza de ML sólida. Un flujo de TensorFlow para predicción de edad de abalones ilustra el seguimiento de extremo a extremo y la trazabilidad

Construir Flujos de Trabajo Agenticos con GPT OSS de OpenAI en SageMaker AI y Bedrock AgentCore
Visión general de extremo a extremo para implementar modelos GPT OSS de OpenAI en SageMaker AI y Bedrock AgentCore, impulsando un analizador de acciones multiagente con LangGraph, con cuantización MXFP4 de 4 bits y orquestación serverless.