Análisis de bases de datos basado en lenguaje natural con Amazon Nova
Sources: https://aws.amazon.com/blogs/machine-learning/natural-language-based-database-analytics-with-amazon-nova, https://aws.amazon.com/blogs/machine-learning/natural-language-based-database-analytics-with-amazon-nova/, AWS ML Blog
TL;DR
- El análisis de bases de datos en lenguaje natural está habilitado por la familia de modelos de base Amazon Nova (Nova Pro, Nova Lite, Nova Micro) y el patrón ReAct implementado a través de LangGraph, permitiendo interacciones tipo conversación con sistemas de bases de datos complejos.
- La solución se organiza en tres componentes principales: UI, IA generativa y datos, y utiliza un agente como coordinador central para preguntas, razonamiento, orquestación de flujos y respuestas en lenguaje natural, con autorrecuperación y HITL.
- Ofrece auto-corrección y flujos HITL para validar y refinar consultas SQL, asegurando que los resultados coincidan con la intención del usuario y los requisitos del esquema.
- Las evaluaciones en el dataset Spider (texto-a-SQL) muestran rendimiento competitivo y baja latencia en tareas cross-domain, con ventajas en las consultas más complejas. En producción, se señalan consideraciones de seguridad para Streamlit en la demostración.
- La colaboración con GenAIIC brinda acceso a expertos para identificar casos de uso valiosos y adaptar soluciones de IA generativa; la arquitectura se apoya en Amazon Bedrock para habilitar NL->SQL y visualizaciones de datos.
Contexto y antecedentes
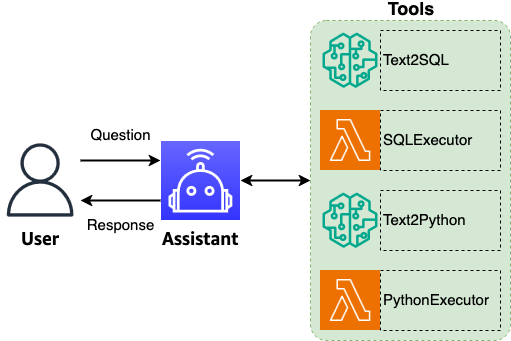
Las interfaces en lenguaje natural para bases de datos han sido un objetivo durante mucho tiempo en la gestión de datos. El enfoque descrito utiliza agentes de LLM para descomponer consultas complejas en pasos de razonamiento explícitos y permitir la autorrecuperación mediante ciclos de validación. Al detectar errores, analizar fallos y refinar consultas, el sistema busca alinear la intención del usuario con los requisitos del esquema con precisión y fiabilidad, permitiendo interacciones intuitivas al estilo de conversación con sistemas de bases de datos sofisticados. Para lograr un rendimiento óptimo con compromisos mínimos, la solución usa la familia de modelos de base Amazon Nova (Nova Pro, Nova Lite, Nova Micro). Estos FMs codifican una gran cantidad de conocimiento global, facilitando razonamiento matizado y comprensión contextual necesaria para análisis de datos complejos. El patrón ReAct (razonamiento y acción) se implementa mediante la arquitectura flexible de LangGraph, combinando las fortalezas de los LLM de Nova para comprensión del lenguaje natural con pasos de razonamiento explícitos y acciones. Este enfoque moderno permite análisis de bases de datos mediante lenguaje natural y la traducción NL->SQL con consultas complejas a través de conjuntos de datos. Muchos clientes en transformación de IA reconocen que sus grandes almacenes de datos esconden potencial para análisis automatizados. Este insight los lleva a explorar soluciones SQL, que van desde simples SELECT hasta consultas multipágina con agregaciones y funciones sofisticadas. El desafío central es traducir la intención del usuario —expresada o implícita— en consultas SQL con rendimiento, precisión y validez que permitan recuperar el conjunto de datos correcto para visualización y exploración. Nuestra solución se destaca por generar consultas con contexto y metadatos para obtener conjuntos de datos precisos y realizar análisis complejos. Una interfaz de usuario amigable es crucial, y hemos desarrollado una interfaz intuitiva que guía al usuario en su trayectoria de análisis con capacidades de HITL, permitiendo entradas, aprobaciones y modificaciones en puntos de decisión críticos. Este enfoque facilita un recorrido analítico cohesionado, no solo una consulta aislada.
Novedades
La arquitectura describe tres componentes centrales—UI, IA generativa y datos—con un agente central que coordina preguntas, enrutamiento y salidas. El agente realiza comprensión de preguntas, toma de decisiones, orquestación de flujos e generación de respuestas completas en lenguaje natural. Mejora la calidad del texto, estandariza la terminología y mantiene el contexto de la conversación para permitir una serie de consultas relacionadas con una intención analítica precisa. Capacidades clave incluyen enrutamiento inteligente para invocar las herramientas adecuadas para cada pregunta, permitiendo procesamiento end-to-end de consultas. El flujo también procesa datos tabulares y visuales y utiliza el contexto completo para generar resúmenes y hallazgos. Un beneficio notable es la capacidad del agente para proponer preguntas de seguimiento para profundizar la exploración y descubrir ideas inesperadas. El agente mantiene el contexto entre conversaciones y puede reconstruir preguntas abreviadas para confirmación, además de sugerir preguntas de seguimiento tras cada intercambio. La estandarización terminológica garantiza coherencia con normas de la industria, directrices del cliente y requisitos de la marca, expandiendo abreviaturas a sus formas completas para mayor claridad. La solución también incluye autocorrección: si ocurre un error de ejecución, el agente utiliza el error y el contexto para regenerar una consulta SQL corregida. Este enfoque aumenta la robustez del procesamiento de consultas en escenarios complejos. El resultado del agente incluye un resumen en lenguaje natural, resultados tabulares con razonamiento, visualizaciones con explicaciones y un resumen conciso de ideas clave. Se utiliza Streamlit para la demo; para despliegues de producción es necesario revisar configuraciones de seguridad. El GenAIIC ofrece acceso a expertos para identificar casos de uso valiosos y diseñar soluciones prácticas de IA generativa adaptadas a necesidades específicas. El conjunto está construido sobre Amazon Bedrock, que permite traducir consultas en lenguaje natural a SQL y generar visualizaciones útiles. Para más información, consulte Amazon Nova Foundation Models y Amazon Bedrock. Si está interesado en colaborar con GenAIIC, puede encontrar más información en AWS Generative AI Innovation Center.
Detalles técnicos o Implementación
Arquitectura y componentes centrales
La solución se basa en tres componentes: UI, IA generativa y datos. Un agente central coordina preguntas, enrutamiento y salidas, con capacidades de comprensión de preguntas, toma de decisiones y orquestación de flujos. El agente mejora la calidad del texto, estandariza la terminología y mantiene el contexto para permitir una cadena de consultas relacionadas con una intención analítica precisa. El enrutamiento inteligente garantiza que se invoquen las herramientas correctas para cada pregunta y que el procesamiento end-to-end funcione. También puede procesar datos tabulares y visuales y usar el contexto para generar resúmenes y percepciones.
Agente y capacidades de auto-corrección
Una característica clave es la capacidad de auto-corrección del agente. Cuando ocurre un error de ejecución, el agente utiliza el error y el contexto para regenerar una consulta SQL corregida, mejorando la robustez del procesamiento de consultas. El agente procesa entradas (pregunta reescrita, resultados de análisis y contexto) para producir un resumen en lenguaje natural y una respuesta que incluye resultados tabulares con razonamiento, explicaciones de visualizaciones y un resumen de insights. Mantiene el contexto entre conversaciones y propone preguntas de seguimiento tras cada interacción.
Procesamiento de datos, visualización y estandarización de lenguaje
La solución admite el procesamiento de datos tabulares y visuales y genera salidas que explican hallazgos y destacan insights. Se estandariza la terminología para alinearla con normas de la industria, directrices del cliente y requisitos de marca, expandiendo abreviaturas a formas completas para mayor claridad.
Evaluación y consideraciones de producción
La solución se evaluó con el Spider dataset de text-to-SQL, un conjunto de referencia ampliamente utilizado para parsing semántico cross-domain. Spider comprende 10,181 preguntas y 5,693 consultas SQL únicas en 200 bases de datos con 138 dominios. La evaluación fue en configuración zero-shot (sin ajuste fino) para medir la generalización de la traducción NL-to-SQL. Los resultados muestran desempeño competitivo y baja latencia, especialmente para consultas complejas. La evaluación ayuda a comparar Amazon Nova con enfoques de vanguardia y demuestra el potencial de un acceso de lenguaje natural a datos a gran escala.
Demostración y consideraciones de producción
La interfaz Streamlit se usa para fines ilustrativos en la demostración. Para despliegues en producción, se deben revisar las configuraciones de seguridad y la arquitectura de despliegue para asegurar el alineamiento con los requisitos de seguridad de la organización. GenAIIC ofrece acceso a expertos para ayudar a identificar casos de uso valiosos y adaptar soluciones de IA generativa.
Prerrequisitos y pasos de despliegue (visión general)
- Utilice cuadernos de SageMaker para experimentar con la solución.
- Descargue y prepare la base de datos utilizada para consultas.
- Inicie la aplicación Streamlit con el comando: streamlit run app.py. La demo ilustra la interfaz y el flujo; en producción, considere seguridad y escalabilidad.
Tabla de hechos clave
| Componente | Descripción |
|---|---|
| Modelos centrales | Amazon Nova Pro, Nova Lite, Nova Micro |
| Patrón | ReAct (razonamiento y acción) vía LangGraph |
| Plataforma | Amazon Bedrock |
| Conjunto de evaluación | Spider Text-to-SQL (zero-shot) |
| Dominios de datos | 138 en 200 bases de datos |
Por qué importa (impacto para desarrolladores/empresas)
- Permite consultas naturales de extremo a extremo sobre datos estructurados con generación de SQL precisa, reduciendo la barrera de acceso a datos para analistas y decisores.
- Utiliza pasos de razonamiento explícitos y acciones para aumentar la transparencia y trazabilidad del proceso analítico.
- Soporta auto-corrección y HITL para mejorar la robustez y fiabilidad en despliegues.
- Ofrece un enfoque escalable para la traducción cross-domain con baja latencia, incluso para consultas complejas.
- Proporciona acceso a orientación experta a través de GenAIIC para identificar casos de uso de alto impacto y adaptar soluciones a necesidades específicas.
Conclusiones clave
- Amazon Nova, guiado por ReAct y LangGraph, permite la traducción NL a SQL con razonamiento explícito.
- Un agente central coordina preguntas, enrutamiento y salidas, manteniendo contexto entre conversaciones.
- Auto-corrección y HITL aumentan la robustez ante errores y refinan los resultados.
- La evaluación Spider indica desempeño competitivo y baja latencia para tareas NL-to-SQL cross-domain.
- La demostración con Streamlit es ilustrativa; despliegues en producción requieren configuraciones de seguridad adecuadas.
FAQ
Referencias
- https://aws.amazon.com/blogs/machine-learning/natural-language-based-database-analytics-with-amazon-nova/
- Las referencias a Amazon Nova Foundation Models y Amazon Bedrock se mencionan en el artículo como contexto de la solución.
More news

Llevar agentes de IA de concepto a producción con Amazon Bedrock AgentCore
Análisis detallado de cómo Amazon Bedrock AgentCore facilita la transición de aplicaciones de IA basadas en agentes desde un concepto de prueba hasta sistemas de producción empresariales, conservando memoria, seguridad, observabilidad y gestión escalable de herramientas.

Scaleway se une a los Proveedores de Inferencia de Hugging Face para Inferencia Serverless y de Baja Latencia
Scaleway es ahora un Proveedor de Inferencia soportado en Hugging Face Hub, lo que permite inferencia serverless directamente en las páginas de modelos con los SDK de JS y Python. Accede a modelos open-weight populares y disfruta de flujos de IA escalables y de baja latencia.

Monitorear la inferencia por lotes de Bedrock de AWS con métricas de CloudWatch
Descubra cómo monitorear y optimizar trabajos de inferencia por lotes de Bedrock con métricas, alarmas y paneles de CloudWatch para mejorar rendimiento, costos y operación.

Solicitando precisión con Stability AI Image Services en Amazon Bedrock
Bedrock incorpora Stability AI Image Services con nueve herramientas para crear y editar imágenes con mayor precisión. Descubre técnicas de prompting para uso empresarial.

Escala la producción visual con Stability AI Image Services en Amazon Bedrock
Stability AI Image Services ya está disponible en Amazon Bedrock, ofreciendo capacidades de edición de imágenes listas para usar a través de la API de Bedrock y ampliando los modelos Stable Diffusion 3.5 y Stable Image Core/Ultra ya presentes.

Usar AWS Deep Learning Containers con Amazon SageMaker AI MLflow gestionado
Vea cómo los AWS Deep Learning Containers (DLCs) se integran con SageMaker AI gestionado por MLflow para equilibrar el control de la infraestructura y una gobernanza de ML sólida. Un flujo de TensorFlow para predicción de edad de abalones ilustra el seguimiento de extremo a extremo y la trazabilidad