Construye un flujo sin servidor para orquestar trabajos por lotes de Bedrock con AWS Step Functions
Sources: https://aws.amazon.com/blogs/machine-learning/build-a-serverless-amazon-bedrock-batch-job-orchestration-workflow-using-aws-step-functions, https://aws.amazon.com/blogs/machine-learning/build-a-serverless-amazon-bedrock-batch-job-orchestration-workflow-using-aws-step-functions/, AWS ML Blog
TL;DR
- Bedrock batch inference ofrece una ruta rentable y escalable para cargas de trabajo de gran volumen, con un descuento del 50% frente al procesamiento bajo demanda.
- Este artículo presenta un patrón de orquestación sin servidor utilizando AWS Step Functions y una pila de AWS CDK para gestionar el preprocesamiento, trabajos por lotes en paralelo y el postprocesamiento.
- La demostración utiliza 2,2 millones de filas del conjunto SimpleCoT, para tareas de generación de texto o embeddings.
- Las plantillas de prompts y el formateo de entrada se centralizan en código (prompt_templates.py y prompt_id_to_template), con orígenes de entrada configurables (datasets de Hugging Face o CSV/Parquet en S3).
- La solución está diseñada para ser rentable y escalable, con orientaciones sobre monitoreo, concurrencia y limpieza de recursos.
Contexto y antecedentes
A medida que las organizaciones adoptan modelos de base para cargas de trabajo de IA/ML, existen dos patrones amplios de inferencia: en tiempo real y por lote. La inferencia por lote es adecuada para procesar conjuntos de datos masivos donde no se requieren resultados inmediatos, y Bedrock ofrece una opción rentable con un descuento del 50% frente al procesamiento a demanda. Implementar la inferencia por lote a gran escala conlleva desafíos, como formatear las entradas, gestionar cuotas de trabajos, orquestar ejecuciones concurrentes y realizar el postprocesamiento para interpretar las salidas del modelo. Este enfoque reúne componentes escalables y sin servidor para simplificar la orquestación de flujos por lote. El flujo abarca tres fases: preprocesamiento de conjuntos de datos (por ejemplo, formateo de prompts), ejecución de trabajos por lote en paralelo y postprocesamiento para analizar las salidas del modelo. La solución es flexible y escalable, permitiendo casos de uso como generar embeddings para millones de documentos o realizar tareas de evaluación o finalización en grandes conjuntos de datos. La arquitectura se implementa mediante AWS Cloud Development Kit (CDK) y orquesta una máquina de estados de Step Functions para gestionar el proceso de extremo a extremo. En el caso de uso presentado, se utilizan 2,2 millones de filas del conjunto SimpleCoT de Hugging Face para demostrar el pipeline. SimpleCoT es un conjunto diverso de ejemplos orientados a tareas para demostrar el razonamiento en cadena en modelos de lenguaje. El patrón de orquestación Bedrock por lotes utiliza componentes escalables y sin servidor para cubrir consideraciones arquitectónicas específicas de flujos de procesamiento por lote. En las secciones siguientes se describen los pasos para desplegar el stack de AWS CDK y ejecutar el flujo en su entorno de AWS.
Novedades
Este artículo presenta una arquitectura sin servidor y escalable para el procesamiento por lotes con Bedrock, orquestado por AWS Step Functions. Muestra cómo:
- Preprocesar entradas y formatear prompts mediante el módulo prompt_templates.py y el mapeo prompt_id_to_template que vincula una tarea a un prompt específico.
- Lanzar trabajos por lote en paralelo y gestionarlos con una máquina de estados de Step Functions desplegada con CDK.
- Postprocesar salidas para extraer resultados y agregarlos en archivos Parquet que conservan las columnas de entrada y añaden la salida (respuesta o embedding). Un caso concreto utiliza 2,2 millones de filas de SimpleCoT. El entorno CDK despliega el flujo y el proceso puede adaptarse a otros conjuntos de datos o cargas de FM. El número máximo de trabajos simultáneos se controla con la variable maxConcurrentJobs en cdk.json, lo que permite ajustar el rendimiento y el costo. El ejemplo también ilustra cómo localizar las salidas de CloudFormation que muestran los nombres del bucket de datos y del flujo de Step Functions.
Por qué importa (impacto para desarrolladores/empresas)
Para desarrolladores y organizaciones, este enfoque permite gestionar inferencias por lote a escala con Bedrock de manera rentable. Beneficios clave:
- Ahorro de costos para inferencias por lote con Bedrock, haciendo viable procesar millones de registros para embeddings o generación.
- Arquitectura sin servidor centrada en la orquestación, reduciendo la carga operativa de pipelines de inferencia por lote.
- Separación clara entre preprocesamiento, cómputo y postprocesamiento, facilitando el mantenimiento y la extensión del flujo para diferentes modelos y datasets.
- Integración sencilla con fuentes de datos como S3 o datasets de Hugging Face, facilitando la reutilización entre proyectos.
- Controles explícitos de concurrencia y despliegue mediante CDK, permitiendo adaptar el pipeline a las necesidades de la empresa. Para equipos que trabajan en etiquetado de datos, generación de datos sintéticos o destilación de modelos, este patrón ofrece una guía práctica para pipelines de inferencia por lote en la nube.
Detalles técnicos o Implementación
A continuación se ofrece una visión general de cómo implementar el flujo de Bedrock por lote con AWS Step Functions, destacando los pasos y puntos de configuración clave.
- Requisitos previos: Instale los paquetes necesarios con el comando npm i.
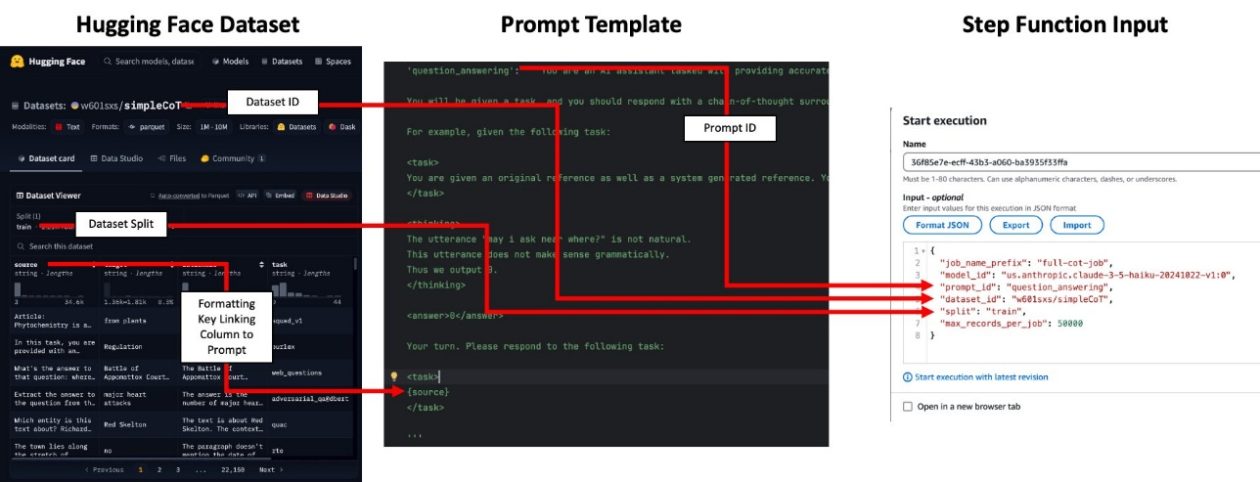
- Prompts y mapeo: Revise prompt_templates.py y agregue un nuevo template de prompt al mapeo prompt_id_to_template para su caso de uso. El mapeo vincula una tarea a un prompt específico. Asegúrese de que las claves de formato del template coincidan con las columnas del conjunto de datos de entrada requeridas por los prompts. Nota: los prompts no se usan para trabajos de embeddings.
- Implementación del stack: Implemente el stack CDK con npm run cdk deploy. Tras la implementación, registre las salidas de CloudFormation que indiquen los nombres del bucket de datos y del flujo Step Functions.
- Preparación de datos: Su entrada puede ser un Hugging Face dataset ID (p. ej., w601sxs/simpleCoT) o un conjunto de datos en S3 (CSV o Parquet). Si se usa Hugging Face, haga referencia al dataset ID y a la split (p. ej., train); el dataset se extrae desde Hugging Face Hub. Las columnas del dataset deben cumplir con las claves de formato requeridas por los prompts.
- Mapeo de prompts y formato de datos: La columna utilizada para prompts se expone mediante una clave de formato (p. ej., topic). El dataset debe contener una columna correspondiente para que el prompt se llene correctamente. Para embeddings, no es necesario proporcionar prompt_id, pero el CSV de entrada debe contener la columna input_text con el texto a embedir.
- Ingesta de datos y orquestación: Cargue su CSV o Parquet en el bucket S3 designado (p. ej., aws s3 cp topics.csv s3://batch-inference-bucket-/inputs/jokes/topics.csv). Abra la consola de Step Functions y envíe una entrada con un s3_uri que apunte a su conjunto de datos. El prompt_id mapea a un template de prompt que genera la justificación y la respuesta para cada fila (o, para embeddings, opera sobre input_text).
- Observabilidad y monitoreo: El máximo de trabajos concurrentes está controlado por maxConcurrentJobs en el archivo cdk.json. Los archivos Parquet de salida contienen las mismas columnas que la entrada más la salida del modelo. Para generación de texto, la salida está en la columna response; para embeddings, en la columna embedding (una lista de flotantes).
- Tiempo y costos: no hay SLA garantizado para la API de Batch Inference; los tiempos varían según la demanda del modelo. En una demostración, procesando 2,2 millones de registros en 45 trabajos con hasta 20 concurrencias, cada trabajo tardó en promedio 9 horas, para un total de aproximadamente 27 horas de procesamiento de extremo a extremo.
- Limpieza: para evitar costos continuos, ejecute cdk destroy para deshacer los recursos creados por la stack CDK. La solución y el proceso se describen en un repositorio público de GitHub vinculado en el artículo.
| Configuración clave | Descripción |
|---|---|
| maxConcurrentJobs | Controla la cantidad máxima de trabajos en paralelo mediante el contexto CDK en cdk.json, permitiendo ajustar throughput y costo |
| Formatos de entrada | Hugging Face dataset ID o CSV/Parquet en S3 |
| Salida | Archivos Parquet que conservan las columnas de entrada más la salida del modelo; generación de texto produce la columna response y embeddings la columna embedding |
Flujo de trabajo práctico
- Paso 1: Preprocesar sus datos para que coincidan con los prompts y asegurar que todas las claves de formato estén presentes.
- Paso 2: Lanzar trabajos en paralelo y gestionarlos con la máquina de estados de Step Functions, respetando el límite de concurrencia.
- Paso 3: Postprocesar las salidas para extraer resultados y agregarlos en Parquet con las columnas de entrada y la salida del modelo.
Puntos clave
- La inferencia por lote con Bedrock es escalable y rentable para grandes volúmenes cuando no se requieren resultados inmediatos.
- Un patrón de orquestación sin servidor con Step Functions simplifica pipelines de inferencia por lote al separar preprocesamiento, cómputo y postprocesamiento.
- El flujo admite diferentes fuentes de datos (Hugging Face o S3) y tareas de generación de texto o embeddings, con salidas almacenadas en Parquet para análisis posterior.
- Controles de concurrencia y despliegue con CDK permiten pipelines reproducibles y auditable, aptos para las necesidades de la empresa.
- El artículo ofrece un ejemplo práctico con 2,2 millones de filas y sirve como base para adaptar el flujo a otros modelos y conjuntos de datos.
FAQ
Referencias
More news

Llevar agentes de IA de concepto a producción con Amazon Bedrock AgentCore
Análisis detallado de cómo Amazon Bedrock AgentCore facilita la transición de aplicaciones de IA basadas en agentes desde un concepto de prueba hasta sistemas de producción empresariales, conservando memoria, seguridad, observabilidad y gestión escalable de herramientas.

Monitorear la inferencia por lotes de Bedrock de AWS con métricas de CloudWatch
Descubra cómo monitorear y optimizar trabajos de inferencia por lotes de Bedrock con métricas, alarmas y paneles de CloudWatch para mejorar rendimiento, costos y operación.

Solicitando precisión con Stability AI Image Services en Amazon Bedrock
Bedrock incorpora Stability AI Image Services con nueve herramientas para crear y editar imágenes con mayor precisión. Descubre técnicas de prompting para uso empresarial.

Escala la producción visual con Stability AI Image Services en Amazon Bedrock
Stability AI Image Services ya está disponible en Amazon Bedrock, ofreciendo capacidades de edición de imágenes listas para usar a través de la API de Bedrock y ampliando los modelos Stable Diffusion 3.5 y Stable Image Core/Ultra ya presentes.

Usar AWS Deep Learning Containers con Amazon SageMaker AI MLflow gestionado
Vea cómo los AWS Deep Learning Containers (DLCs) se integran con SageMaker AI gestionado por MLflow para equilibrar el control de la infraestructura y una gobernanza de ML sólida. Un flujo de TensorFlow para predicción de edad de abalones ilustra el seguimiento de extremo a extremo y la trazabilidad

Construir Flujos de Trabajo Agenticos con GPT OSS de OpenAI en SageMaker AI y Bedrock AgentCore
Visión general de extremo a extremo para implementar modelos GPT OSS de OpenAI en SageMaker AI y Bedrock AgentCore, impulsando un analizador de acciones multiagente con LangGraph, con cuantización MXFP4 de 4 bits y orquestación serverless.