Cómo Amazon Finance construyó un asistente de IA usando Amazon Bedrock y Amazon Kendra para apoyar a los analistas en el descubrimiento de datos y conocimientos comerciales
Sources: https://aws.amazon.com/blogs/machine-learning/how-amazon-finance-built-an-ai-assistant-using-amazon-bedrock-and-amazon-kendra-to-support-analysts-for-data-discovery-and-business-insights, https://aws.amazon.com/blogs/machine-learning/how-amazon-finance-built-an-ai-assistant-using-amazon-bedrock-and-amazon-kendra-to-support-analysts-for-data-discovery-and-business-insights/, AWS ML Blog
TL;DR
- Amazon Finance creó un asistente de IA que combina Claude 3 Sonnet vía Amazon Bedrock con la búsqueda inteligente de Amazon Kendra para ayudar a los analistas a descubrir datos y generar insights.
- La solución usa Retrieval Augmented Generation (RAG): almacenes vectoriales para búsqueda semántica y generación aumentada basada en el conocimiento recuperado para reducir alucinaciones.
- Amazon Kendra Enterprise Edition Index se eligió sobre OpenSearch Service y Amazon Q Business por sus capacidades integradas, procesamiento de documentos en más de 40 formatos, conectores empresariales y manejo avanzado de consultas.
- La interfaz se construyó con Streamlit; las evaluaciones muestran una reducción del 30% en el tiempo de búsqueda y una mejora del 80% en la precisión de los resultados, con aumentos en precisión y recall.
- La arquitectura estandariza el acceso a datos en Amazon Finance, preserva el conocimiento institucional y mejora la agilidad de toma de decisiones. Las afirmaciones anteriores resumen una implementación descrita por el equipo de Amazon Finance y citada en el AWS ML Blog [https://aws.amazon.com/blogs/machine-learning/how-amazon-finance-built-an-ai-assistant-using-amazon-bedrock-and-amazon-kendra-to-support-analysts-for-data-discovery-and-business-insights/].
Contexto y antecedentes
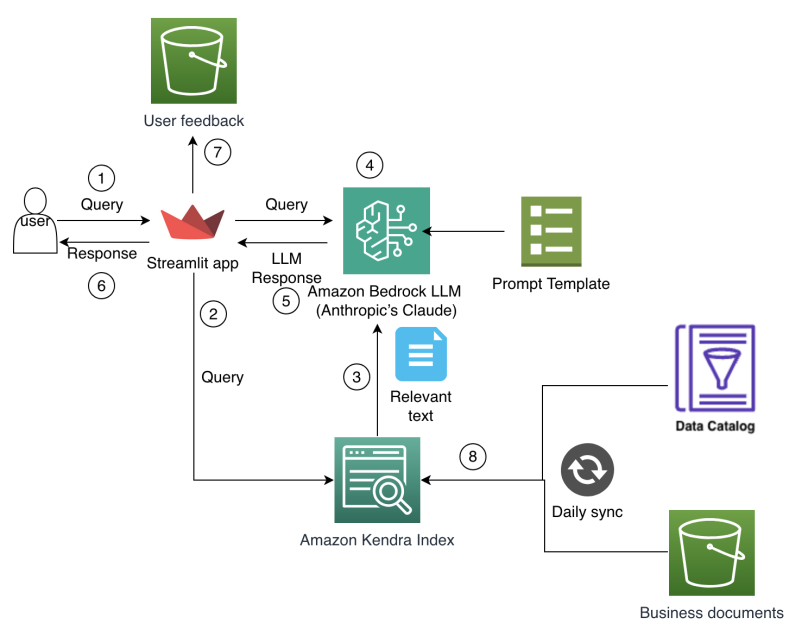
Los analistas de finanzas en Amazon Finance se enfrentan a una complejidad creciente en la planificación y el análisis, trabajando con grandes conjuntos de datos que abarcan múltiples sistemas, lagos de datos y unidades de negocio. Navegar por catálogos de datos de forma manual y reconciliar información de fuentes dispares consume mucho tiempo, dejando menos espacio para el análisis y la generación de insights. Los datos históricos y las decisiones pasadas residen en documentos y sistemas legados, dificultando el uso de aprendizajes previos durante los ciclos de planificación. A medida que el contexto empresarial evoluciona rápidamente, los analistas requieren acceso rápido a métricas relevantes, supuestos de planificación e insights financieros para decisiones basadas en datos. Las herramientas tradicionales basadas en búsquedas por palabras clave y consultas rígidas luchan por capturar relaciones contextuales en datos financieros y a menudo no preservan el conocimiento institucional, lo que provoca análisis redundantes y supuestos de planificación inconsistentes entre equipos. En resumen, los analistas necesitaban una forma más intuitiva de acceder, entender y aprovechar el conocimiento financiero y los activos de datos de la organización. El equipo de Amazon Finance desarrolló una solución de IA de extremo a extremo que combina IA generativa con búsqueda empresarial para permitir a los analistas interactuar con fuentes de datos y documentación mediante consultas en lenguaje natural, reduciendo la necesidad de búsquedas manuales entre varios sistemas y asegurando respuestas ancoradas en una base de conocimiento corporativa que refleja el contexto institucional y los requisitos de seguridad. Este enfoque no solo acelera la descubrimiento de datos, sino que también ayuda a preservar el razonamiento de decisiones y a estandarizar la planificación a lo largo de la organización. El enfoque se basa en el patrón Retrieval Augmented Generation (RAG), que combina la recuperación de conocimiento externo con generación de lenguaje. El sistema almacena y consulta representaciones de texto en dimensiones altas mediante vectores para soportar búsquedas semánticas, condiciona el modelo de lenguaje al contexto recuperado y genera respuestas que se apoyan en las fuentes. El objetivo es mantener precisión y trazabilidad en conversaciones de IA para finanzas. La implementación utiliza Large Language Models (LLMs) en Amazon Bedrock y búsqueda semántica con Amazon Kendra para ofrecer una experiencia de asistente corporativo cohesiva, segura y escalable. El modelo seleccionado fue Claude 3 Sonnet de Anthropic, accesible a través de Bedrock, elegido por sus capacidades de generación y razonamiento. La integración con Kendra permite entender la intención del usuario y recuperar respuestas pertinentes basadas en documentos de la empresa. Las características de seguridad empresarial de Kendra protegen los datos y ayudan a cumplir requerimientos regulatorios en finanzas. La interfaz de usuario se apoya en Streamlit para facilitar el desarrollo rápido, la iteración y el despliegue. El objetivo central es el patrón Retrieval Augmented Generation (RAG), que separa la recuperación de información del proceso de generación para mantener la fiabilidad y precisión. La integración de Claude 3 Sonnet en Bedrock y Kendra crea un flujo de trabajo RAG cohesivo que ancla las respuestas en el conocimiento de la empresa. El post de AWS describe estas decisiones de diseño y los resultados observados. [source]
Novedades y arquitectura
La implementación integra varias tecnologías modernas en un flujo de trabajo integrado. Componentes clave:
- RAG como base, combinando búsqueda semántica y generación anclada al conocimiento recuperado.
- Capa de recuperación basada en vectores para búsquedas semánticas enriquecidas.
- Un LLM a través de Amazon Bedrock, Claude 3 Sonnet, para generación de lenguaje y razonamiento.
- Amazon Kendra Enterprise Edition Index para NLP corporativo, procesamiento automático de documentos en >40 formatos, conectores empresariales y manejo inteligente de consultas (sinónimos y sugerencias de refinamiento).
- Interfaz Streamlit para desarrollo rápido y experiencia de usuario atractiva, con plantillas de prompts para formatear consultas e integrar conocimiento recuperado.
- Un marco de evaluación para medir rendimiento y experiencia. Las métricas de evaluación muestran una reducción del tiempo de búsqueda y una mejora en la precisión de los resultados de búsqueda, evidenciando el impacto operativo del enfoque RAG en un contexto financiero. El post de AWS detalla estas observaciones y las motivaciones detrás de las elecciones tecnológicas. [source]
Detalles técnicos o Implementación
Componentes y motivación:
- Recuperación inteligente con almacenamiento vectorial para una búsqueda semántica más rica y relevante.
- Generación aumentada (RAG) para producir respuestas contextuales usando Claude 3 Sonnet condicionada al contexto recuperado.
- LLMs en Amazon Bedrock con Claude 3 Sonnet, elegido por sus capacidades de razonamiento y generación.
- Amazon Kendra Enterprise Edition Index utilizado para NLP avanzado, procesamiento automático de documentos en más de 40 formatos, conectores empresariales y manejo inteligente de consultas (sinónimos, refinamiento).
- UI y herramientas: Streamlit para desarrollo rápido y despliegue sencillo.
- Plantillas de prompts para estructurar consultas, incorporar conocimiento recuperado y aplicar restricciones de generación.
- Marco de evaluación: métricas de precisión, recall y tiempo de respuesta para medir mejoras en descubrimiento de datos y búsqueda de conocimiento. Los resultados muestran mejoras significativas, con expectativas de mayor rendimiento conforme se enriquecen los metadatos. [source] | Servicio | Razón de uso | Características clave relevantes para este caso |---|---|---| | Amazon Kendra Enterprise Edition Index | NLP listo para usar, menor necesidad de configuración | Comprensión del lenguaje natural; procesamiento automático de documentos (>40 formatos); conectores empresariales; manejo inteligente de consultas con sinónimos y refinamiento |OpenSearch Service | Requiere configuración extensa | Implementación manual de búsqueda semántica y vectorial |Amazon Q Business | Menos robusto/flexible | Recuperación, pero no tan madura como Kendra | El conjunto muestra por qué Kendra fue la elección para la recuperación, junto con Bedrock y el flujo RAG. Para más detalles, consulte las Referencias. [source]
Por qué importa (impacto para desarrolladores/empresas)
Este enfoque demuestra cómo las empresas pueden escalar soluciones de IA para descubrimiento de datos y soporte a decisiones, manteniendo gobernanza y seguridad. Anclando respuestas en una base de conocimiento corporativa y usando búsqueda semántica para presentar documentos relevantes, los analistas obtienen acceso más rápido a métricas, supuestos y contexto histórico. El enfoque RAG ayuda a conservar el conocimiento institucional y evita pérdidas de contexto cuando los equipos cambian. Para desarrolladores y engenieros, la arquitectura ofrece un camino práctico para combinar recuperación vectorial con un LLM robusto y una capa de búsqueda empresarial lista para producción. Las capacidades de Kendra Enterprise Edition aportan NLP, procesamiento de documentos y conectores adaptados a las necesidades de cumplimiento de finanzas. El impacto práctico incluye mayor agilidad en la planificación, decisiones más consistentes y mejor interoperabilidad entre operaciones globales. El post de AWS ilustra este caso y sus beneficios. [source]
Lecciones clave (takeaways)
- Los flujos de IA basados en recuperación (RAG) pueden transformar laDiscovery de datos y los insights en finanzas.
- La búsqueda semántica basada en vectores complementa el razonamiento del LLM para reducir alucinaciones y aumentar la precisión.
- Elegir una solución de búsqueda empresarial con NLP incorporado y procesamiento de documentos facilita la adopción y la conformidad.
- Una interfaz Streamlit facilita desarrollo rápido e interacción con analistas.
- Un marco de evaluación estructurado guía mejoras continuas, especialmente mediante enriquecimiento de metadatos.
FAQ
-
¿Cómo fundamenta el asistente sus respuestas?
Recupera información relevante con búsqueda semántica en un repositorio vectorial, condiciona Claude 3 Sonnet al contexto y genera respuestas ancladas en las fuentes recuperadas.
-
¿Por qué elegir Claude 3 Sonnet via Bedrock para este caso?
Claude 3 Sonnet ofrece capacidades sólidas de generación de lenguaje y razonamiento para sostener una interacción en lenguaje natural bien alineada con el contexto empresarial.
-
¿Qué métricas se observaron en la evaluación?
Reducción del 30% en el tiempo de búsqueda y mejora del 80% en la exactitud de los resultados, con mejoras en precisión y recall para descubrimiento de datos y búsqueda de conocimiento.
-
¿Qué ventajas tiene Kendra Enterprise Edition frente a OpenSearch o Q Business?
NLP listo para usar, procesamiento automático de documentos, conectores empresariales, reconocimiento de sinónimos y refinamiento de consultas, reduciendo la configuración manual y mejorando la recuperación.
Referencias
More news

Llevar agentes de IA de concepto a producción con Amazon Bedrock AgentCore
Análisis detallado de cómo Amazon Bedrock AgentCore facilita la transición de aplicaciones de IA basadas en agentes desde un concepto de prueba hasta sistemas de producción empresariales, conservando memoria, seguridad, observabilidad y gestión escalable de herramientas.

Monitorear la inferencia por lotes de Bedrock de AWS con métricas de CloudWatch
Descubra cómo monitorear y optimizar trabajos de inferencia por lotes de Bedrock con métricas, alarmas y paneles de CloudWatch para mejorar rendimiento, costos y operación.

Solicitando precisión con Stability AI Image Services en Amazon Bedrock
Bedrock incorpora Stability AI Image Services con nueve herramientas para crear y editar imágenes con mayor precisión. Descubre técnicas de prompting para uso empresarial.

Escala la producción visual con Stability AI Image Services en Amazon Bedrock
Stability AI Image Services ya está disponible en Amazon Bedrock, ofreciendo capacidades de edición de imágenes listas para usar a través de la API de Bedrock y ampliando los modelos Stable Diffusion 3.5 y Stable Image Core/Ultra ya presentes.

Usar AWS Deep Learning Containers con Amazon SageMaker AI MLflow gestionado
Vea cómo los AWS Deep Learning Containers (DLCs) se integran con SageMaker AI gestionado por MLflow para equilibrar el control de la infraestructura y una gobernanza de ML sólida. Un flujo de TensorFlow para predicción de edad de abalones ilustra el seguimiento de extremo a extremo y la trazabilidad

Construir Flujos de Trabajo Agenticos con GPT OSS de OpenAI en SageMaker AI y Bedrock AgentCore
Visión general de extremo a extremo para implementar modelos GPT OSS de OpenAI en SageMaker AI y Bedrock AgentCore, impulsando un analizador de acciones multiagente con LangGraph, con cuantización MXFP4 de 4 bits y orquestación serverless.