Acelera el procesamiento inteligente de documentos con IA generativa en AWS
TL;DR
- AWS presenta GenAI IDP Accelerator, una solución de código abierto y sin servidor que combina IA generativa con Bedrock Data Automation y modelos de Bedrock para automatizar el procesamiento inteligente de documentos.
- El acelerador convierte documentos no estructurados en datos estructurados, permitiendo un procesamiento escalable en múltiples industrias y reduciendo la entrada manual y los errores.
- La implementación se facilita mediante un template de AWS CloudFormation y un flujo de trabajo modular basado en patrones, con resultados en días, no en meses.
- Casos reales, como Competiscan y Ricoh, ilustran el procesamiento de alto volumen y la transformación de documentos de salud en entornos exigentes.
- El proyecto enfatiza un pipeline configurable, prompts, plantillas de extracción y reglas de validación, todo construido sobre servicios de AWS con enfoque en seguridad y eficiencia de costos.
Contexto y antecedentes
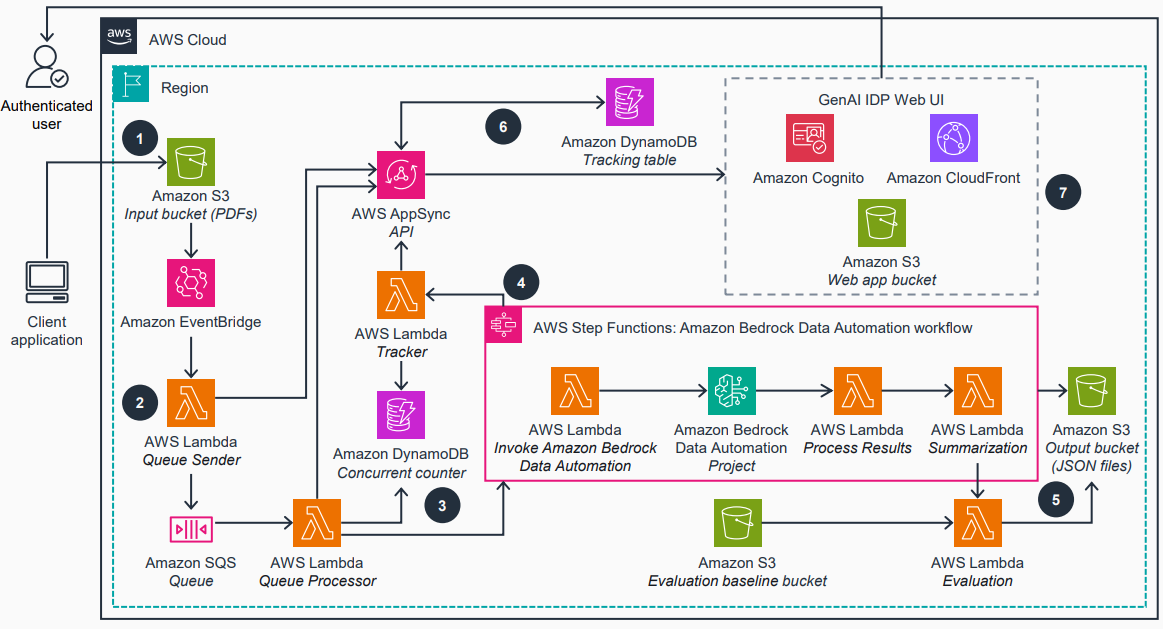
Cada día, las organizaciones procesan millones de documentos—facturas, contratos, reclamaciones de seguros y expedientes médicos—y una gran parte de los datos está no estructurada, lo que oculta valor potencial para transformar resultados. La entrada manual de datos sigue siendo común, y el proceso de extraer información de PDFs, imágenes escaneadas y formularios es lento y propenso a errores, dificultando escalar las operaciones ante volúmenes crecientes. La IA generativa y los modelos de lenguaje grande han cambiado las capacidades del IDP (procesamiento inteligente de documentos). Las aproximaciones basadas en plantillas y reglas rigurosas tienden a fallar con variaciones de documentos y layouts complejos. Los modelos modernos pueden entender el contexto, manejar diferentes tipos de documentos sin plantillas y lograr extracciones de alta precisión. Este cambio facilita procesar distintos tipos de documentos con mayor rapidez y menor costo de implementación. En este contexto, AWS presenta GenAI IDP Accelerator como una solución de código abierto lista para producción. El GenAI IDP Accelerator es una solución modular, sin servidor y basada en servicios de AWS. Aprovecha Bedrock Data Automation para capacidades de procesamiento de documentos listas para usar y modelos Bedrock de última generación para casos que requieren lógica personalizada. El objetivo es ofrecer un punto de partida robusto para que las empresas adapten rápidamente flujos de automatización de documentos a sus necesidades, manteniendo seguridad y escalabilidad. Source Para desarrolladores y arquitectos, este proyecto ofrece un camino práctico para pasar de una demostración a una solución IDP lista para producción, con foco en escalabilidad y precisión en una variedad de documentos. Source
Lo nuevo
GenAI IDP Accelerator se presenta como una solución de código abierto lista para implantar, que combina IA generativa con Bedrock Data Automation y modelos Bedrock. Puntos clave:
- Una base sin servidor con patrones de procesamiento basados en Bedrock Data Automation, que proporcionan capacidades de procesamiento de documentos listas para usar, alta precisión y una tarificación por página sencilla. Source
- Integración con los modelos Bedrock de última generación para documentos complejos que requieren lógica personalizada.
- Un pipeline modular que enriquece los documentos en cada etapa—OCR, clasificación, extracción, evaluación, resumen y evaluación—permitiendo desplegar y personalizar cada paso de forma independiente.
- Diseño guiado por configuración que facilita ajustar prompts, templates de extracción y reglas de validación sin tocar la infraestructura subyacente.
- Despliegue mediante el template de AWS CloudFormation; el tiempo de implementación es de aproximadamente 15–20 minutos, y luego se obtiene acceso a la interfaz web mediante credenciales enviadas por correo. Source
- Demostración práctica (Pattern-1) del flujo predeterminado de Bedrock Data Automation y la posibilidad de añadir más patrones para cubrir necesidades reales.
- Resultados reales de clientes mencionados en el artículo, como Competiscan y Ricoh, que muestran la utilidad de alto volumen y documentos de salud complejos. Source El proyecto está diseñado para integrarse con el ecosistema de AWS y ofrece un camino escalable para que las empresas automaticen flujos de documentos manteniendo seguridad y control de costos.
Por qué importa (impacto para desarrolladores/empresas)
El GenAI IDP Accelerator aborda dos realidades claves del procesamiento de documentos: el volumen de datos y la variabilidad de formatos. Al combinar IA generativa con un pipeline sin servidor en AWS, la solución permite:
- Procesar cientos a millones de documentos con menor esfuerzo manual, desbloqueando insights a partir de datos no estructurados con mayor rapidez.
- Acortar el tiempo de paso a producción. A diferencia de prototipos que pueden fallar a escala, el acelerador enfatiza la robustez, el manejo de errores, la escalabilidad y la seguridad empresarial.
- Mantener flexibilidad y control de costos. Un pipeline modular basado en patrones permite ajustar prompts, plantillas de extracción y reglas de validación para distintos tipos de documentos, manteniendo una economía por página.
- Aprovechar la seguridad, confiabilidad y ecosistema de AWS. Construido con servicios de AWS, ofrece escalabilidad y seguridad de nivel empresarial con opciones para extender con CDK o Terraform en el futuro. Source Para desarrolladores y arquitectos, el acelerador ofrece una guía práctica para pasar de una demostración a una solución de procesamiento de documentos lista para producción, capaz de manejar diversos tipos de documentos con alta precisión y escalabilidad. Source
Detalles técnicos o Implementación
El GenAI IDP Accelerator se describe como una solución modular, sin servidor, construida sobre servicios de AWS. Elementos técnicos clave:
- Un pipeline modular que enriquece los documentos en cada etapa—OCR, clasificación, extracción, evaluación, resumen y evaluación final—permitiendo desplegar y personalizar cada paso de forma independiente, manteniendo el flujo integrado. Este diseño facilita adaptar la solución a distintos tipos de documentos.
- Uso de Bedrock Data Automation para capacidades de procesamiento de documentos listas para usar, alta precisión y tarificación por página sencilla. Para escenarios más complejos, los modelos Bedrock (FMs) ofrecen la lógica personalizada necesaria. Source
- Distribución a través de GitHub, con la posibilidad de actualizar la pila a la versión más reciente y construir desde el código si se requieren modificaciones. El proyecto adopta un enfoque basado en configuración para prompts, templates y reglas de validación sin tocar la infraestructura. Source
- Pattern-1 representa el flujo de trabajo por defecto de Bedrock Data Automation, y se anticipa la llegada de más patrones para cubrir necesidades reales. La arquitectura se ilustra con el patrón por defecto y las conexiones entre componentes en la pila de AWS. Source Detalles de despliegue y operación:
- Prerrequisitos: una cuenta AWS con permisos de administrador y acceso a modelos Bedrock (incluidos los modelos de Anthropic cuando corresponda) en Bedrock. Consulta las guías de acceso a los modelos. Source
- Despliegue mediante AWS CloudFormation: el template crea los recursos necesarios; tras la implantación, recibirás credenciales para la interfaz web. El tiempo de implementación es de ~15–20 minutos.
- Flujo de producción: en producción, los documentos se cargan en un bucket S3 de entrada para activar el procesamiento automáticamente. Hay guías para probar sin la UI y para actualizar la pila a la versión más reciente. Source
- Extensibilidad: es posible compilar desde el código para soportar más regiones o cambios de código. Hay planes para soporte de AWS CDK y Terraform en el futuro. Siga el repositorio de GitHub para actualizaciones y participe para contribuir. Source Casos de uso reales mencionados: Competiscan y Ricoh, que demuestran la aplicabilidad en entornos de alto volumen y documentos médicos complejos. Source
Conclusiones clave
- GenAI IDP Accelerator ofrece un camino probado y orientado a producción para automatizar la transformación de documentos no estructurados con IA generativa en AWS.
- Es modular, sin servidor y configurable, permitiendo ajustes rápidos de prompts y reglas de validación sin modificar la infraestructura.
- Bedrock Data Automation gestiona el procesamiento de documentos listo para usar, mientras que Bedrock FMs aporta lógica personalizada para casos complejos.
- La implantación se simplifica con CloudFormation, con ventana de aprovisionamiento de 15–20 minutos y economía por página escalable.
- Los casos de uso reales muestran el potencial para reemplazar la entrada manual por extracciones estructuradas con alta precisión a escala. Source
FAQ
Referencias
More news

Llevar agentes de IA de concepto a producción con Amazon Bedrock AgentCore
Análisis detallado de cómo Amazon Bedrock AgentCore facilita la transición de aplicaciones de IA basadas en agentes desde un concepto de prueba hasta sistemas de producción empresariales, conservando memoria, seguridad, observabilidad y gestión escalable de herramientas.

Monitorear la inferencia por lotes de Bedrock de AWS con métricas de CloudWatch
Descubra cómo monitorear y optimizar trabajos de inferencia por lotes de Bedrock con métricas, alarmas y paneles de CloudWatch para mejorar rendimiento, costos y operación.

Solicitando precisión con Stability AI Image Services en Amazon Bedrock
Bedrock incorpora Stability AI Image Services con nueve herramientas para crear y editar imágenes con mayor precisión. Descubre técnicas de prompting para uso empresarial.

Escala la producción visual con Stability AI Image Services en Amazon Bedrock
Stability AI Image Services ya está disponible en Amazon Bedrock, ofreciendo capacidades de edición de imágenes listas para usar a través de la API de Bedrock y ampliando los modelos Stable Diffusion 3.5 y Stable Image Core/Ultra ya presentes.

Usar AWS Deep Learning Containers con Amazon SageMaker AI MLflow gestionado
Vea cómo los AWS Deep Learning Containers (DLCs) se integran con SageMaker AI gestionado por MLflow para equilibrar el control de la infraestructura y una gobernanza de ML sólida. Un flujo de TensorFlow para predicción de edad de abalones ilustra el seguimiento de extremo a extremo y la trazabilidad

Construir Flujos de Trabajo Agenticos con GPT OSS de OpenAI en SageMaker AI y Bedrock AgentCore
Visión general de extremo a extremo para implementar modelos GPT OSS de OpenAI en SageMaker AI y Bedrock AgentCore, impulsando un analizador de acciones multiagente con LangGraph, con cuantización MXFP4 de 4 bits y orquestación serverless.