El 'Super Weight': Cómo un solo parámetro puede determinar el comportamiento de un gran modelo de lenguaje
Sources: https://machinelearning.apple.com/research/the-super-weight
TL;DR
- Un subconjunto extremadamente pequeño de parámetros de LLM, denominado «super weights», puede influir desproporcionadamente en el comportamiento del modelo.
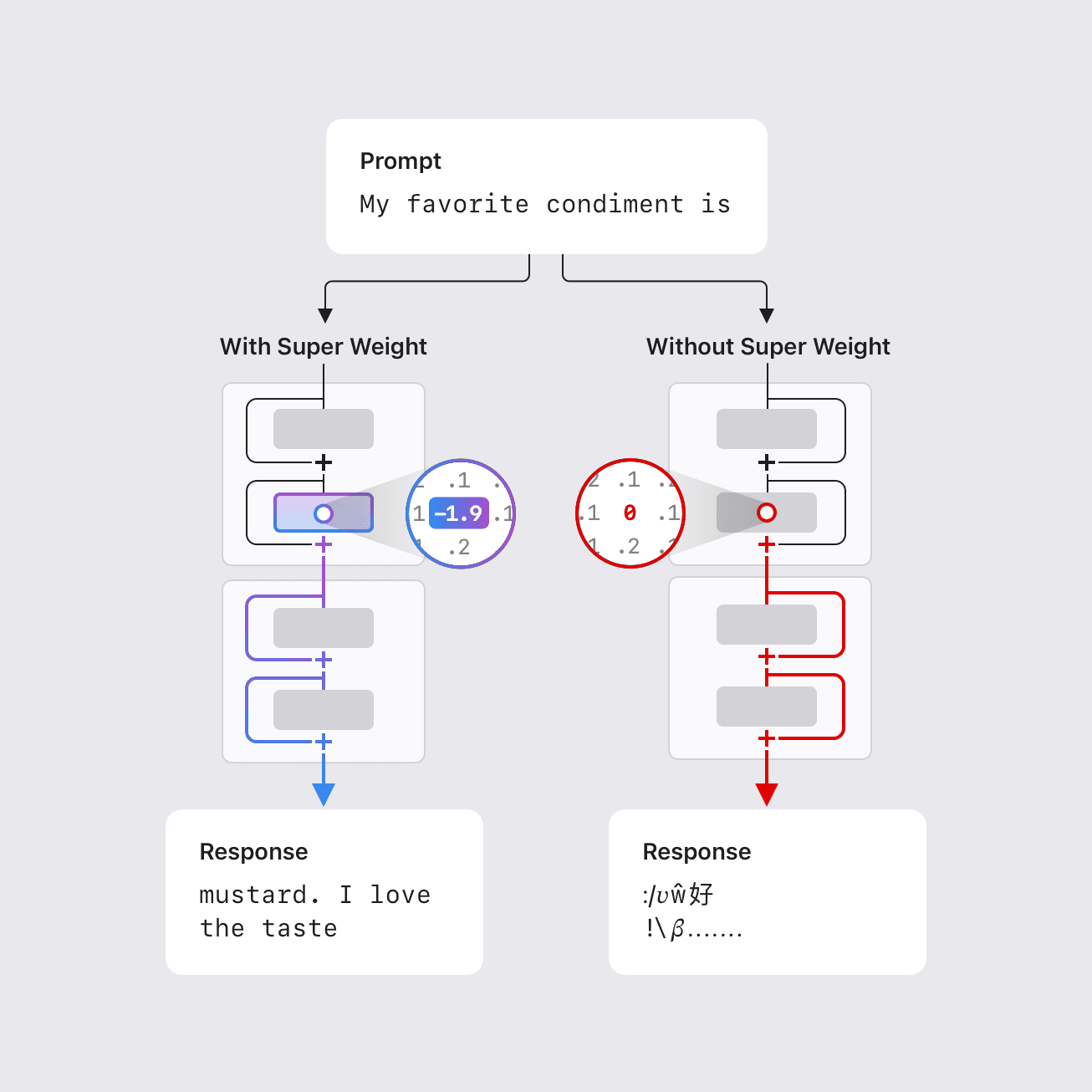
- En algunos casos, eliminar un único super weight puede destruir la capacidad del modelo para generar texto coherente, provocando un aumento de la perplexidad de tres órdenes de magnitud y reduciendo la precisión zero-shot a niveles de conjetura aleatoria.
- Los super weights inducen las llamadas «super activations» que persisten a través de las capas y sesgan las salidas del modelo de forma global; quitar el peso suprime este efecto.
- Un método de una pasada permite localizar estos pesos detectando outliers de activación raros y de gran magnitud (super activations) que se alinean con el canal del super weight, típicamente después del bloque de atención en la proyección descendente de la red feed-forward.
- Se ha compilado un índice de coordenadas de super weights para varios LLMs abiertos para facilitar investigaciones futuras; por ejemplo, se proporcionan coordenadas para Llama-7B.\n
Contexto y antecedentes
Los modelos de lenguaje grande suelen contar con miles de millones, e incluso cientos de miles de millones de parámetros, lo que complica su despliegue en hardware con recursos limitados, como dispositivos móviles. Reducir tamaño y complejidad computacional es esencial para operar localmente y de forma privada sin conexión a Internet. Investigaciones previas mostraron que una pequeña fracción de outliers de peso puede ser vital para mantener la calidad; esta fracción puede ser tan baja como 0,01% de los pesos. El trabajo de Apple identifica un conjunto notablemente pequeño de parámetros, llamados «super weights», cuyo cambio puede destruir la capacidad de un LLM para generar texto coherente. Por ejemplo, en el modelo Llama-7B, quitar su único super weight impide al modelo producir una salida significativa. Por otro lado, quitar miles de otros outliers, aunque tengan magnitudes mayores, solo ocasiona degradaciones moderadas de calidad. Este trabajo propone una metodología para localizar estos super weights con una única pasada hacia adelante, aprovechando la observación de que los super weights inducen activaciones grandes y raras (super activations) que persisten a través de las capas con magnitud y posición constantes; su canal se alinea con el del super weight. El peso super se encuentra de forma consistente en la proyección descendente de la red feed-forward después del bloque de atención, con frecuencia en una capa temprana. Se ha compilado un índice de coordenadas de super weights para varios modelos abiertos comunes para facilitar la investigación por parte de la comunidad.\n
¿Qué hay de nuevo?
Los investigadores de Apple identifican un fenómeno aún más sorprendente: una cantidad extremadamente pequeña de parámetros puede determinar el comportamiento de un LLM. Los hallazgos clave incluyen:
- La existencia de “super weights” cuya modificación puede destruir gravemente la calidad de la generación; en algunos casos, un solo parámetro es suficiente para desactivar el funcionamiento.
- La noción de “super activations”: activaciones grandes y raras que aparecen después del super weight y persisten a través de las capas con magnitud y posición constantes, y cuyo canal se alinea con el del peso.
- Un método práctico de localización que requiere solo una pasada hacia adelante para identificar estos pesos mediante picos en las distribuciones de activación en componentes específicos, principalmente la proyección descendente del feed-forward tras el bloque de atención.
- Las ubicaciones son consistentes entre modelos: el peso super se encuentra en la proyección descendente tras la atención, típicamente en una capa inicial. Se ofrece un ejemplo explícito para Llama-7B en HuggingFace: acceder al super weight usando layers[2].mlp.down_proj.weight[3968, 7003]. El estudio también proporciona un índice de coordenadas para varios modelos.\n
Por qué importa (impacto para desarrolladores/ empresas)
Comprender e identificar super weights tiene implicaciones prácticas para la compresión:
- La preservación de las super activations con alta precisión puede permitir una cuantización simple sin perder mucha calidad, y conservar el peso super durante la cuantización puede mejorar las razones de compresión.
- Esta estrategia dirigida ofrece una ruta más amigable para hardware para ejecutar LLMs potentes en dispositivos con recursos limitados, manteniendo una calidad mayor respecto a técnicas de poda general.
- El hallazgo también plantea preguntas sobre el diseño y entrenamiento de modelos, sugiriendo que ciertos outliers pueden influir en salidas semánticas y que su preservación durante la compresión es crítica. Se facilita un directorio de super weights para fomentar investigaciones continuas.\n
Detalles técnicos o Implementación
Los puntos clave resumidos:
- Los super weights constituyen un subconjunto extremadamente pequeño de parámetros con influencia desproporcionada sobre el comportamiento del modelo.
- Las super activations son activaciones grandes, raras, que aparecen después del super weight y persisten a través de las capas, alineadas al canal del peso y manteniendo su magnitud en las conexiones residuales.
- El método propuesto requiere solo una pasada hacia adelante y se apoya en picos en las distribuciones de activación en componentes específicos, principalmente la proyección descendente del feed-forward tras el bloque de atención, para localizar el super weight y su activación correspondiente.
- Patrón de ubicación consistente entre modelos: el peso super se ubica en la proyección descendente tras la atención, usualmente en una capa inicial.\n | Modelo (ejemplo) | Coordenada del peso super (muestra) |--- |--- |Llama-7B (HuggingFace) | layers[2].mlp.down_proj.weight[3968, 7003] |
Conclusiones clave
- Un conjunto extremadamente pequeño de parámetros puede gobernar el comportamiento de un LLM, y su eliminación puede afectar drásticamente el rendimiento.
- Los conceptos de “super weights” y “super activations” ofrecen una visión útil sobre la dinámica interna de los LLM y las implicaciones para la compresión.
- Un enfoque práctico de una sola pasada permite localizar estos pesos a través de picos de activación, facilitando la preservación dirigida durante cuantización y poda.
- El estudio proporciona un índice oficial de coordenadas para modelos conocidos, fomentando validación y experimentación por parte de la comunidad.\n
FAQ
-
¿Qué son los super weights?
Son un subconjunto extremadamente pequeño de parámetros cuyo cambio puede influir de forma desproporcionada en la generación de texto del LLM.
-
¿Cómo se localizan los super weights?
Con una sola pasada, detectando outliers de activación raros y de gran magnitud (super activations) que se alinean con el canal del super weight, típicamente tras la proyección descendente del bloque de atención.
-
¿Por qué esto importa para la compresión?
Preservar las super activations con alta precisión facilita la cuantización simple sin perder calidad significativa; preservar el super weight durante la cuantización puede mejorar las tasas de compresión.
-
¿Dónde suelen estar estos weights?
En la proyección descendente de la red feed-forward tras el bloque de atención, a menudo en una capa temprana; se proporciona un ejemplo para Llama-7B.
Referencias
More news

Cómo reducir cuellos de botella KV Cache con NVIDIA Dynamo
NVIDIA Dynamo offloads KV Cache desde la memoria de la GPU hacia almacenamiento económico, habilitando contextos más largos, mayor concurrencia y costos de inferencia más bajos para grandes modelos y cargas de IA generativa.

Reduciendo la latencia en frío para la inferencia de LLM con NVIDIA Run:ai Model Streamer
Análisis detallado de cómo NVIDIA Run:ai Model Streamer disminuye los tiempos de arranque en frío al transmitir pesos a la memoria GPU, con benchmarks en GP3, IO2 y S3.

Agilizar el acceso a cambios de contenido ISO-rating con Verisk Rating Insights y Amazon Bedrock
Verisk Rating Insights, impulsado por Amazon Bedrock, LLM y RAG, ofrece una interfaz conversacional para acceder a cambios ERC ISO, reduciendo descargas manuales y acelerando información precisa.

Cómo msg mejoró la transformación de la fuerza laboral de RR. HH. con Amazon Bedrock y msg.ProfileMap
Este artículo explica cómo msg automatizó la armonización de datos para msg.ProfileMap usando Amazon Bedrock para impulsar flujos de enriquecimiento impulsados por LLM, aumentando la precisión de la coincidencia de conceptos de RR. HH., reduciendo la carga de trabajo manual y alineándose con la UE A

Automatizar pipelines RAG avanzados con Amazon SageMaker AI
Optimiza la experimentación a la producción para Retrieval Augmented Generation (RAG) con SageMaker AI, MLflow y Pipelines, para flujos reproducibles, escalables y con gobernanza.

Despliega Inferencia de IA escalable con NVIDIA NIM Operator 3.0.0
NVIDIA NIM Operator 3.0.0 amplía la inferencia de IA escalable en Kubernetes, habilitando despliegues multi-LLM y multi-nodo, integración con KServe y soporte DRA en modo tecnología, con colaboración de Red Hat y NeMo Guardrails.