Infosys Topaz utiliza Amazon Bedrock para transformar las operaciones del help desk técnico
TL;DR
- Infosys Topaz aprovecha Amazon Bedrock para impulsar un help desk técnico basado en IA generativa para un gran proveedor de energía. AWS blog
- El sistema ingiere transcripciones pasadas y nuevas, construye una base de conocimientos y utiliza generación con recuperación (RAG) para ofrecer resoluciones, reduciendo el tiempo de búsqueda manual.
- La seguridad de datos y los controles de acceso se basan en servicios de AWS como IAM, KMS, Secrets Manager, TLS, CloudTrail y OpenSearch Serverless con control de acceso basado en roles.
- La arquitectura usa AWS Step Functions, Lambda, S3, DynamoDB y un frontend Streamlit para entregar una experiencia de producción con trazabilidad de tiempo y métricas de QoS.
Contexto y antecedentes
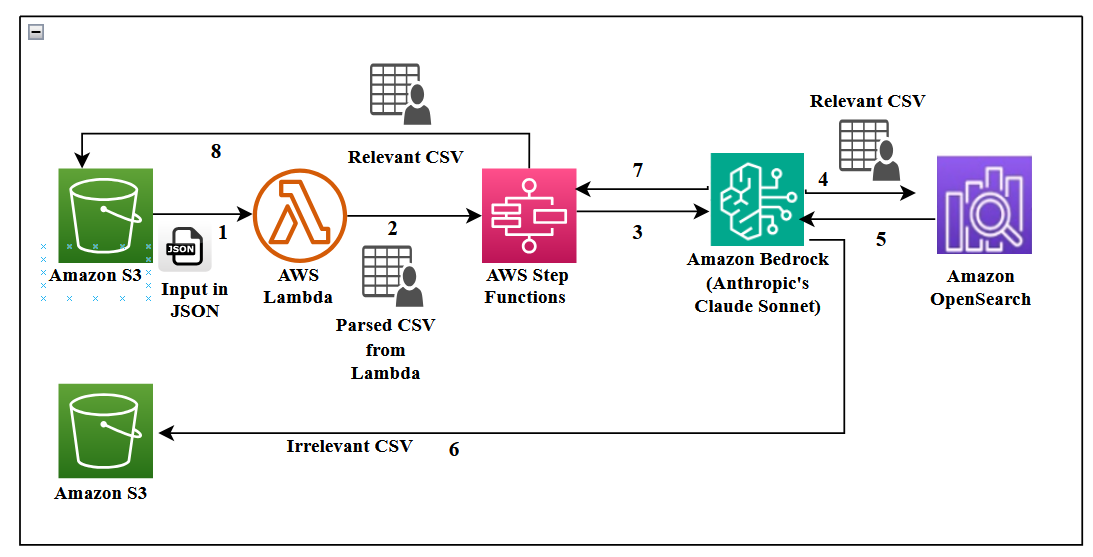
Un gran proveedor de energía depende de un help desk técnico donde los agentes atienden llamadas de clientes y ayudan a técnicos de campo que instalan, intercambian, mantienen y reparan medidores. El volumen es considerable, con aproximadamente 5,000 llamadas por semana (alrededor de 20,000 al mes). Contratar más agentes y entrenarlos con el conocimiento necesario es costoso y difícil de escalar. Para abordar esto, Infosys Topaz se integra con capacidades de AWS Bedrock para crear un help desk impulsado por IA que ingiere transcripciones, construye una base de conocimientos consultable y ofrece resoluciones casi en tiempo real. El objetivo es reducir el tiempo de manejo de llamadas, automatizar tareas repetitivas y mejorar la calidad general del soporte. La arquitectura destaca una integración estrecha con los servicios de AWS para el flujo y la gestión de datos dentro de un único sistema en la nube, incluyendo Step Functions, DynamoDB y OpenSearch Service. AWS blog Las conversaciones se registran para calidad y análisis. Las transcripciones se almacenan en S3 en formato JSON y luego se analizan para crear una base de conocimientos que la IA pueda consultar. Se enfatiza la importancia del control de acceso basado en roles y del manejo seguro de datos, especialmente PII. La arquitectura ilustra un flujo de extremo a extremo desde transcripciones brutas hasta una interfaz interactiva utilizada por los agentes. Este enfoque también abarca métricas como sentimiento, tono y satisfacción.
Novedades
La implementación combina Infosys Topaz con Amazon Bedrock, incluyendo Claude Sonnet de Anthropic como modelo de lenguaje para resumir y evaluar el contexto. Titan Text Embeddings en Bedrock alimentan una búsqueda vectorial eficiente para la generación con recuperación (RAG) a través de un almacén vectorial OpenSearch Serverless. Las decisiones de diseño clave incluyen el chunking de transcripciones en bloques de 1,000 tokens con una superposición de 150–200 tokens para mejorar la calidad de la recuperación. Un evento de AWS Lambda dispara un flujo de Step Functions cuando se cargan nuevas transcripciones en S3. Las transcripciones en bruto se convierten en CSV para filtrado (campos: ID de contacto único, participante y contenido). El pipeline alimenta los embeddings en OpenSearch Serverless para la recuperación. OpenSearch Serverless ofrece almacenamiento vectorial escalable y búsquedas rápidas, con la capacidad de agregar, actualizar y eliminar embeddings prácticamente en tiempo real. Un entorno de producción con RAG depende de un almacenamiento vectorial robusto y de modelos de embeddings adecuados para recuperar información contextualmente relevante. Desde el punto de vista de seguridad, Secrets Manager protege las credenciales, KMS garantiza el cifrado en reposo y TLS 1.2 protege las comunicaciones; CloudTrail garantiza auditoría. El acceso se gestiona mediante políticas IAM y una implementación RBAC con colecciones separadas de OpenSearch Serverless para controlar los permisos por colección. Tres personas definen los niveles de acceso: administrador (acceso total), analista técnico (acceso medio) y agente técnico (acceso mínimo). La interfaz Streamlit se ha construido para proporcionar una UI con una sección de FAQ y un panel de métricas de búsqueda. La autenticación mediante authenticate.login asigna el ID de usuario y st.cache_data() guarda resultados en caché entre sesiones para mejorar el rendimiento.
Por qué importa (impacto para desarrolladores/empresas)
Esta implementación demuestra cómo operacionalizar una IA generativa que complementa a los agentes humanos, en lugar de reemplazarlos. Al construir una base de conocimientos a partir de transcripciones reales y usar una búsqueda vectorial robusta (RAG), las organizaciones pueden reducir el tiempo de manejo de llamadas, estandarizar resoluciones y escalar el soporte sin aumentar el personal. La arquitectura muestra cómo Bedrock se integra con los servicios centrales de AWS para ofrecer un flujo de datos completo, gobernanza de datos segura y auditoría. Para las empresas, este patrón ofrece pasos prácticos para implementar asistentes de IA empresariales en atención al cliente, CRM y help desks manteniendo estándares de cumplimiento y seguridad.
Detalles técnicos o Implementación
El flujo comienza con transcripciones de llamadas grabadas por agentes y técnicos de campo. Las transcripciones se almacenan en S3 en formato JSON y luego se analizan para generar un CSV estructurado con campos como ID de contacto, rol del interlocutor y contenido de la conversación. Step Functions orquesta el flujo de ingesta que transforma transcripciones brutas en una base de conocimientos lista para usar. La capa de embeddings y recuperación utiliza Titan Text Embeddings para vectorizar el texto y OpenSearch Serverless para almacenamiento y búsqueda vectorial, permitiendo RAG mediante Claude Sonnet en Bedrock para resumir las conversaciones e identificar la información relevante. La estrategia de chunking emplea bloques de 1,000 tokens con una superposición de 150–200 tokens, combinada con recuperación por ventana de oraciones para mejorar la calidad de la recuperación sin procesar documentos extensos de una vez. La interfaz Streamlit sirve como frontend, con una autenticación simple (authenticate.login) para asignar el ID de usuario. La interfaz presenta una sección de FAQ y un panel de métricas de búsqueda (sentimiento, tono y satisfacción). Los resultados se almacenan en caché mediante st.cache_data() para acelerar respuestas entre sesiones. Desde la perspectiva de seguridad, Secrets Manager protege las credenciales, KMS garantiza el cifrado en reposo y TLS 1.2 protege los datos en tránsito, mientras que CloudTrail avala la auditoría. El acceso se gestiona con políticas IAM y una estructura RBAC que utiliza colecciones OpenSearch Serverless distintas. Tres personas definen niveles de acceso: administrador, analista técnico de escritorio y agente técnico. Este enfoque permite que los contenidos sensibles sean accesibles solo para usuarios autorizados, a la vez que facilita flujos de soporte eficientes.
Conclusiones clave
- La IA aplicada al help desk es factible cuando se apoya en una ingestión y recuperación bien diseñadas.
- Claude Sonnet en Bedrock y Titan Embeddings permiten una recuperación contextual efectiva sobre transcripciones operativas.
- La seguridad, el cifrado y la gobernanza auditable son esenciales para manejar datos de clientes y PII en aplicaciones empresariales de IA.
- Una arquitectura que integra Step Functions, Lambda, S3 y OpenSearch Serverless ofrece escalabilidad para producción.
- El RBAC con tres personas garantiza la protección de datos sensibles al tiempo que facilita flujos de soporte eficientes.
FAQ
Referencias
More news

Llevar agentes de IA de concepto a producción con Amazon Bedrock AgentCore
Análisis detallado de cómo Amazon Bedrock AgentCore facilita la transición de aplicaciones de IA basadas en agentes desde un concepto de prueba hasta sistemas de producción empresariales, conservando memoria, seguridad, observabilidad y gestión escalable de herramientas.

Monitorear la inferencia por lotes de Bedrock de AWS con métricas de CloudWatch
Descubra cómo monitorear y optimizar trabajos de inferencia por lotes de Bedrock con métricas, alarmas y paneles de CloudWatch para mejorar rendimiento, costos y operación.

Solicitando precisión con Stability AI Image Services en Amazon Bedrock
Bedrock incorpora Stability AI Image Services con nueve herramientas para crear y editar imágenes con mayor precisión. Descubre técnicas de prompting para uso empresarial.

Escala la producción visual con Stability AI Image Services en Amazon Bedrock
Stability AI Image Services ya está disponible en Amazon Bedrock, ofreciendo capacidades de edición de imágenes listas para usar a través de la API de Bedrock y ampliando los modelos Stable Diffusion 3.5 y Stable Image Core/Ultra ya presentes.

Usar AWS Deep Learning Containers con Amazon SageMaker AI MLflow gestionado
Vea cómo los AWS Deep Learning Containers (DLCs) se integran con SageMaker AI gestionado por MLflow para equilibrar el control de la infraestructura y una gobernanza de ML sólida. Un flujo de TensorFlow para predicción de edad de abalones ilustra el seguimiento de extremo a extremo y la trazabilidad

Construir Flujos de Trabajo Agenticos con GPT OSS de OpenAI en SageMaker AI y Bedrock AgentCore
Visión general de extremo a extremo para implementar modelos GPT OSS de OpenAI en SageMaker AI y Bedrock AgentCore, impulsando un analizador de acciones multiagente con LangGraph, con cuantización MXFP4 de 4 bits y orquestación serverless.