Optimizando los endpoints de modelos de Salesforce con los componentes de inferencia IA de SageMaker
Sources: https://aws.amazon.com/blogs/machine-learning/optimizing-salesforces-model-endpoints-with-amazon-sagemaker-ai-inference-components, aws.amazon.com
TL;DR
- Los componentes de inferencia de SageMaker AI permiten desplegar múltiples modelos fundamentales en un único endpoint, con asignaciones de aceleradores y memoria por modelo.
- El empaquetado inteligente y el escalado automático reducen el desperdicio de GPU y pueden generar ahorros significativos de costos; Salesforce reporta hasta una reducción de ocho veces en costos de despliegue e infraestructura.
- Un enfoque de hosting híbrido combina endpoints SMEs tradicionales con componentes de inferencia para equilibrar estabilidad, rendimiento y costo.
- La solución admite los modelos CodeGen en conjunto (Inline, BlockGen, FlowGPT) y otras cargas de trabajo propietarias como ApexGuru, demostrando inferencia escalable y eficiente a gran escala.
- Salesforce planea migrar a GPUs AWS más modernas (P5en con NVIDIA H200) para maximizar la utilización sin perder rendimiento.
Contexto y antecedentes
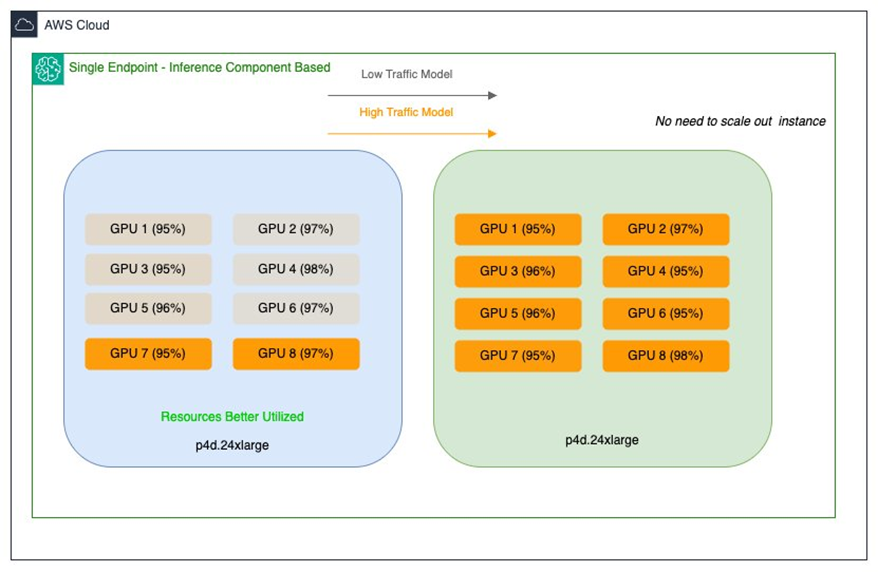
El equipo Salesforce AI Platform Model Serving es responsable de incorporar modelos y proporcionar una infraestructura robusta para alojar una variedad de modelos de ML, incluidos grandes modelos de lenguaje (LLMs). Su objetivo es simplificar el despliegue, mejorar el rendimiento de inferencia y optimizar costos para proporcionar capacidades de IA con costos predecibles. Salesforce cuenta con modelos propietarios, como CodeGen, desplegados en múltiples endpoints de modelo único (SMEs) que abarcan tamaños desde unos pocos GB hasta aproximadamente 30 GB. Dos desafíos de optimización dieron forma a su enfoque: los modelos grandes (20–30 GB) con tráfico bajo ocupaban GPUs de alto rendimiento en instancias multi-GPU, lo que provocaba subutilización. Los modelos medianos (~15 GB) con alta demanda requerían baja latencia y alto rendimiento, lo que podía incrementar costos si seProvisionaban para picos en configuraciones similares. La operación actual utiliza instancias EC2 P4d y se planifica usar las recientes P5en con GPUs NVIDIA H200. El objetivo era una estrategia de optimización de recursos que maximizara la utilización de GPUs en todos los endpoints de SageMaker sin sacrificar rendimiento ni sobreaprovisionar hardware. Este esfuerzo refleja un reto común en la industria: equilibrar rendimiento para workloads avanzados de IA con eficiencia de infraestructura y uso de recursos. Salesforce buscaba una base flexible y escalable para respaldar iniciativas de IA en evolución, manteniendo un rendimiento estable para los clientes.
Novedades
Para abordar los desafíos, Salesforce utilizó los componentes de inferencia de SageMaker AI, que permiten desplegar varios modelos fundamentales en un solo endpoint SageMaker AI. Cada modelo puede configurarse con su propio número de aceleradores y asignación de memoria, además de artefactos del modelo, imagen de contenedor y el número de copias a desplegar. SageMaker AI se encarga del placement y del empaquetado para optimizar la disponibilidad y el costo. Beneficios clave:
- Control de recursos por modelo: se definen aceleradores y memoria por cada copia de modelo, permitiendo una gestión más granular entre múltiples modelos.
- Escalado dinámico: los componentes de inferencia pueden escalar aumentando o reduciendo el número de copias de modelo en función del tráfico, mientras que SageMaker AI maneja el empaquetado para optimizar costo y rendimiento.
- Integración con autoescalado: al habilitar el autoescalado gestionado, SageMaker AI ajusta las instancias de cómputo según la necesidad de los componentes para servir el tráfico.
- Consolidación orientada al costo: alojar múltiples modelos en un solo endpoint reduce el overhead operativo y permite usar de forma más eficiente los recursos de GPU durante picos de tráfico. Salesforce introdujo endpoints de componentes de inferencia junto a los SMEs existentes para ampliar las opciones de hosting sin comprometer la estabilidad, rendimiento o usabilidad. Los SMEs ofrecen hosting dedicado para cada modelo con rendimiento predecible para cargas constantes, mientras que los componentes de inferencia optimizan el uso de recursos para cargas variables mediante el compartir de GPU y el escalado dinámico. En la práctica, Salesforce configuró un endpoint con el tipo de instancia y la cuenta inicial para cubrir los requisitos base de inferencia, adjuntando paquetes de modelos de forma dinámica. Modelos como BlockGen y TextEval se configuraron como componentes de inferencia con asignaciones precisas de recursos (número de aceleradores, memoria, artefactos, imagen de contenedor y número de copias). Esta aproximación permitió alojar múltiples variantes de modelos en el mismo endpoint, manteniendo control granular sobre recursos y políticas de escalado. En esta arquitectura, SageMaker AI gestiona el placement, el escalado y el empaquetado de modelos y aceleradores para maximizar la utilización y minimizar costos. Cuando el tráfico aumenta o disminuye, el sistema puede ajustar automáticamente los recursos de GPU, permitiendo que cada modelo escale de forma independiente dentro del endpoint, respetando los límites configurados. Esta flexibilidad es crucial para soportar un portafolio de modelos con patrones de tráfico y requisitos de rendimiento heterogéneos.
Por qué importa (impacto para desarrolladores/empresas)
El enfoque de Salesforce demuestra cómo las empresas pueden mejorar la economía del serving de IA sin sacrificar el rendimiento. Al refinar la asignación de GPU a nivel de modelo y permitir el uso compartido dinámico de GPUs entre modelos, las organizaciones pueden:
- Lograr reducciones de costos significativas mediante un empaquetado más inteligente y escalado automático.
- Mantener alto rendimiento y baja latencia para cargas de alto tráfico, utilizando GPUs de alto rendimiento de forma más eficiente para modelos más pequeños.
- Reducir la carga operativa consolidando varios modelos en menos endpoints y dejando que la plataforma gestione la asignación de recursos y el escalado.
- Asegurar estabilidad para workloads críticos a través de SMEs, mientras que los componentes de inferencia optimizan cargas variables. Los resultados muestran que la asignación inteligente de recursos y el escalado dinámico permiten usar GPUs de alto rendimiento de manera más rentable, abriendo la puerta a workloads de IA más exigentes sin el coste tradicional. La arquitectura demuestra cómo la economía de la infraestructura puede transformarse y cómo el rendimiento puede coexistir con la eficiencia de costos en portafolios de modelos diversos.
Detalles técnicos o Implementación
El concepto central es simple: desplegar un endpoint de SageMaker AI con un tipo de instancia base y una cuenta inicial, adjuntar paquetes de modelos y configurar cada modelo como un componente de inferencia con especificaciones de recursos por copia (aceleradores, memoria, artefactos, imagen del contenedor y copias).
- Componentes de inferencia: crean una abstracción de modelos que permite asignar recursos de CPU/GPU y políticas de escalado por modelo. Esto posibilita que un endpoint hospede varios modelos con control granular de recursos.
- Configuración del endpoint: define el tipo de instancia y el recuento inicial del endpoint, para luego adjuntar paquetes de modelos que crean contenedores por copia cuando sea necesario.
- Escalado por modelo: aplica políticas de escalado separadas para cada componente para adaptarse a diferentes patrones de uso y optimizar costos.
- Autoescalado y empaquetado: SageMaker AI gestiona el placement para empacar modelos y aceleradores, minimizando costos y manteniendo el rendimiento.
- Enfoque híbrido de hosting: Salesforce mantiene SMEs para cargas estables y utiliza componentes de inferencia para optimizar recursos en cargas variables, todo en el mismo endpoint de SageMaker AI. Un ejemplo práctico es el uso de CodeGen, un conjunto de modelos propietarios para entender y generar código, con variantes como Inline, BlockGen y FlowGPT. Estos modelos se configuraron como componentes de inferencia para compartir recursos de GPU en el mismo endpoint, entregando rendimiento consistente a costos operativos reducidos. Resultados técnicos incluyen:
- Mejor uso de recursos y menor coste operativo gracias al control granular por modelo.
- Capacidad para alojar múltiples modelos en un único endpoint con escalado independiente.
- Reducción de costos de despliegue e infraestructura, con reportes de hasta ocho veces menos costos.
Conclusiones clave
- Los componentes de inferencia permiten múltiples modelos por endpoint con asignación de recursos por modelo, mejorando la utilización y reduciendo costos.
- El escalado automático y el empaquetado inteligente maximizan el uso de GPUs para un portafolio de modelos con patrones de tráfico heterogéneos.
- Un enfoque híbrido SME+componentes de inferencia ofrece previsibilidad y eficiencia de costos.
- La arquitectura respalda modelos propietarios como CodeGen, con configuraciones de recursos específicas para cada variante.
- Salesforce demuestra cómo convertir la infraestructura de IA en operaciones escalables y rentables.
FAQ
-
¿Qué son los componentes de inferencia de SageMaker AI?
Son una construcción de despliegue que permite ejecutar dos o más modelos fundacionales en un único endpoint de SageMaker AI con asignaciones de aceleradores y memoria por modelo, además de copias y políticas de escalado.
-
¿Cómo permiten los componentes de inferencia múltiples modelos en un solo endpoint?
Cada modelo se configura como un componente de inferencia con recursos dedicados; SageMaker AI gestiona el placement y el empaquetado para optimizar la disponibilidad y el costo.
-
¿Cómo funciona el autoescalado con componentes de inferencia?
Si se habilita, el autoescalado gestionado ajusta el número de instancias según las necesidades de los componentes para servir el tráfico, empaquetando modelos para minimizar costos sin perder rendimiento.
Referencias
More news

NVIDIA HGX B200 reduce la intensidad de las emisiones de carbono incorporado
El HGX B200 de NVIDIA reduce la intensidad de carbono incorporado en un 24% frente al HGX H100, al tiempo que ofrece mayor rendimiento de IA y eficiencia energética. Este artículo resume los datos PCF y las novedades de hardware.

Llevar agentes de IA de concepto a producción con Amazon Bedrock AgentCore
Análisis detallado de cómo Amazon Bedrock AgentCore facilita la transición de aplicaciones de IA basadas en agentes desde un concepto de prueba hasta sistemas de producción empresariales, conservando memoria, seguridad, observabilidad y gestión escalable de herramientas.

Cómo reducir cuellos de botella KV Cache con NVIDIA Dynamo
NVIDIA Dynamo offloads KV Cache desde la memoria de la GPU hacia almacenamiento económico, habilitando contextos más largos, mayor concurrencia y costos de inferencia más bajos para grandes modelos y cargas de IA generativa.

Microsoft transforma el sitio de Foxconn en el data center Fairwater AI, descrito como el más poderoso del mundo
Microsoft anuncia planes para un data center Fairwater AI de 1,2 millones de pies cuadrados en Wisconsin, con cientos de miles de GPU Nvidia GB200. El proyecto de 3.3 mil millones de dólares promete un entrenamiento de IA sin precedentes.

Manual de los Grandmasters de Kaggle: 7 Técnicas de Modelado para Datos Tabulares
Un análisis detallado de siete técnicas probadas por los Grandmasters de Kaggle para resolver rápidamente conjuntos de datos tabulares mediante aceleración por GPU, desde baselines variados hasta ensamblaje y pseudo-etiquetado.

Monitorear la inferencia por lotes de Bedrock de AWS con métricas de CloudWatch
Descubra cómo monitorear y optimizar trabajos de inferencia por lotes de Bedrock con métricas, alarmas y paneles de CloudWatch para mejorar rendimiento, costos y operación.