Procesamiento Inteligente de Documentos Escalable con Amazon Bedrock Data Automation
Sources: https://aws.amazon.com/blogs/machine-learning/scalable-intelligent-document-processing-using-amazon-bedrock-data-automation, aws.amazon.com
TL;DR
- Bedrock Data Automation habilita un pipeline IDP totalmente serverless y escalable usando AWS Step Functions y Amazon A2I, con blueprints (estándar y personalizados) aplicados dentro de un único proyecto para manejar tipos de documentos diversos.
- La solución procesa PDFs y formatos de imagen comunes (PDF, JPG, PNG, TIFF, DOC, DOCX) y selecciona automáticamente el blueprint adecuado en función del análisis de contenido.
- Combina normalización de datos, extracciones explícitas e implícitas, puntuación de confianza y datos de bounding box para mejorar la calidad de extracción y la interoperabilidad con sistemas downstream.
- Una revisión humana vía Amazon A2I usa una interfaz de bounding box para verificar las extracciones; al completar, los resultados se almacenan en Amazon S3 y el flujo se reanuda.
- El enfoque promete escalabilidad con costo-efectivo, desarrollo más rápido y mayor calidad de datos para flujos IDP en sectores como gobierno, salud, servicios financieros y otros.
Contexto e historia
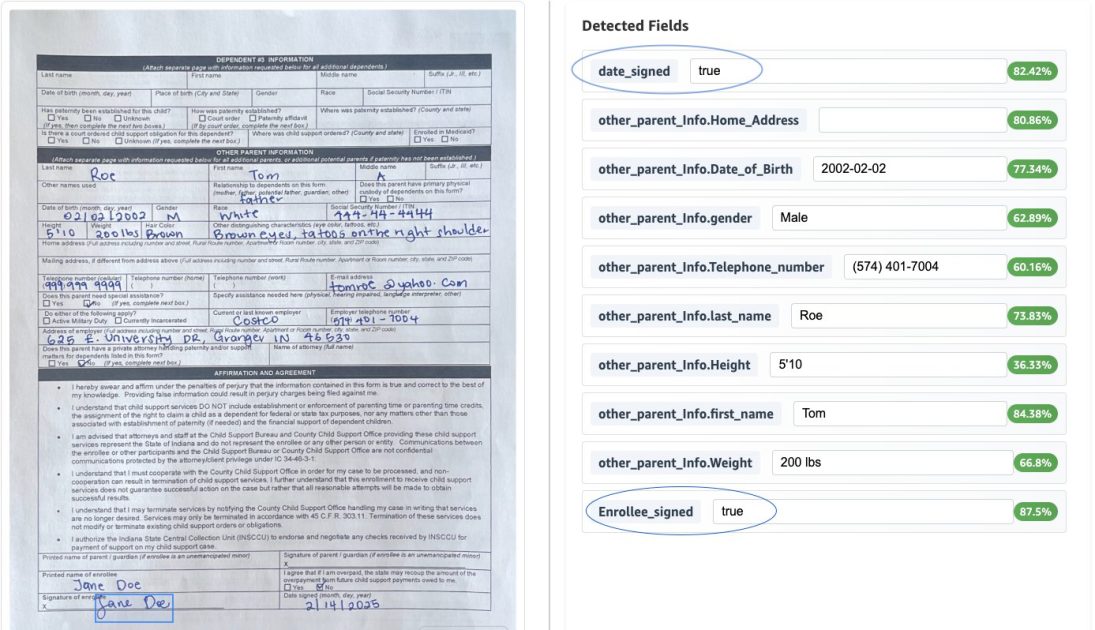
El procesamiento inteligente de documentos (IDP) automatiza la extracción, el análisis y la interpretación de información crítica de documentos mediante ML y NLP avanzados. Cuando se combina con IA generativa, el IDP permite una comprensión más sofisticada, extracción de datos estructurados y clasificación automática. La IA generativa aplicada al IDP ayuda a las organizaciones a manejar la variedad de documentos que los modelos tradicionales pueden no ver, mejorando la eficiencia, precisión y soporte a la decisión. Este enfoque es especialmente relevante en sectores como servicios de apoyo a la infancia, seguros, salud, servicios financieros y sector público. El procesamiento manual tradicional crea cuellos de botella y aumenta el riesgo de errores, mientras que IDP con IA mejora significativamente la eficiencia de los flujos de documentos e la recuperación de información. En una entrada anterior del AWS Machine Learning Blog, mostramos cómo construir un pipeline IDP escalable usando modelos de Anthropic en Bedrock. Aunque ese enfoque ofrecía un rendimiento sólido, Bedrock Data Automation aporta un nivel superior de eficiencia y flexibilidad a las soluciones IDP. Esta entrada explora cómo Bedrock Data Automation mejora las capacidades de procesamiento de documentos y facilita el recorrido de automatización, con un ejemplo centrado en un formulario de inscripción de apoyo infantil. El blog enfatiza una arquitectura totalmente serverless que integra Bedrock Data Automation con AWS Step Functions y Amazon A2I para lograr escalabilidad rentable para cargas de trabajo de diferentes tamaños. También destaca cómo múltiples tipos de documentos pueden procesarse dentro de un solo proyecto aplicando automáticamente el blueprint adecuado según el contenu. El enfoque utiliza la normalización de datos para asegurar salidas uniformes y soporta tanto extracciones explícitas como implícitas. Por ejemplo, las fechas de nacimiento se estandarizan a AAAA-MM-DD y los Números de Seguro Social se formatean como XXX-XX-XXXX. El formulario de inscripción de apoyo infantil ilustra un tipo de dato personalizado para direcciones que descompone direcciones de una sola línea en campos estructurados (Calle, Ciudad, Estado, Código Postal). Las validaciones mantienen la exactitud y conformidad de los datos, como la presencia de la firma del titular y que la fecha firmada no esté en el futuro. La implementación incluye una revisión humana con la UI de A2I y un token de callback para reanudar el flujo. Bedrock Data Automation introduce capacidades significativas para IDP, incluida la puntuación de confianza, datos de bounding box, clasificación automática y desarrollo rápido mediante blueprints. Al combinar estas capacidades con normalización, transformación y validación de datos, las organizaciones pueden reducir el tiempo de desarrollo, mejorar la calidad de los datos y construir soluciones IDP más robustas y escalables que se integran con procesos de revisión humana. Para actualizaciones y nuevos casos de uso, siga el AWS Machine Learning Blog. Abdul Navaz es Arquitecto de Soluciones Senior en el equipo de Salud y Servicios Humanos de AWS, con sede en Dallas, Texas. Venkata Kampana es arquitecto de soluciones senior en el mismo equipo, con sede en Sacramento, California. Sanjeev Pulapaka es líder de IA y arquitecto principal de soluciones para el sector público, con experiencia en IA generativa y liderazgo en la materia.
¿Qué hay de nuevo en Bedrock Data Automation (vista rápida)
Bedrock Data Automation introduce capacidades que mejoran la escalabilidad y precisión del IDP:
- Puntuación de confianza
- Datos de bounding box
- Clasificación automática
- Desarrollo rápido mediante blueprints
- Normalización, transformación y validación de datos
- Soporte a múltiples tipos de documentos dentro de un solo proyecto Este artículo utiliza el formulario de inscripción de apoyo infantil como ejemplo para ilustrar cómo estas capacidades se conectan en un flujo práctico. El diagrama adjunto muestra una arquitectura totalmente serverless que procesa documentos a través de Step Functions, blueprints de Bedrock Data Automation y A2I para revisión humana.
A quién va dirigido
Este artículo está dirigido a ingenieros de datos, ingenieros de ML y arquitectos de soluciones que construyen o amplían pipelines IDP para sectores público, salud, finanzas y otros donde el procesamiento de documentos a escala y con alta precisión es crítico. También es relevante para equipos que buscan acelerar el desarrollo mediante arquitecturas basadas en blueprints y sin servidor.
Cómo funciona (visión técnica)
- Arquitectura y componentes
- Diseño totalmente sin servidor con Bedrock Data Automation, AWS Step Functions y Amazon A2I.
- Un único proyecto alberga múltiples blueprints (estándar y personalizados) para soportar tipos de documentos variados.
- El flujo puede procesar archivos con un solo documento o varios documentos (PDFs multi-página o imágenes multi-página).
- Pipeline de procesamiento de documentos
- Step Functions Map recorre cada documento.
- Una salida conforme se escribe en S3 para procesamiento posterior.
- Documentos con baja confianza se envían a A2I para revisión humana, con realce de las zonas para validación.
- Tras la revisión, un token de callback reanuda el flujo y la salida revisada se almacena en S3.
- Tipos de documentos y blueprints
- Soporta tipos como documentos de inmunización, certificados de impuestos, formularios de inscripción y licencias de conducir.
- El análisis de contenido aplica automáticamente el blueprint adecuado dentro de un solo proyecto.
- Normalización, transformaciones y validaciones
- Las fechas de nacimiento se estandarizan al formato AAAA-MM-DD; los SSN se formatean como XXX-XX-XXXX.
- Las direcciones se transforman en campos estructurados (Calle, Ciudad, Estado, Código Postal).
- Validaciones: presencia de la firma y que la fecha de firma no sea futura.
- Experiencia del desarrollador
- Los blueprints permiten desarrollo e iteración rápidos, reduciendo la necesidad de código personalizado.
- La arquitectura facilita escalar según cargas de trabajo con un modelo serverless rentable.
Puntos clave (takeaways)
- Bedrock Data Automation aporta puntuación de confianza, datos de bounding box, clasificación automática y desarrollo rápido a IDP.
- Normalización, transformaciones y validaciones centralizan la calidad y la interoperabilidad.
- Un solo proyecto puede gestionar varios tipos de documentos con selección automática de blueprints, permitiendo pipelines IDP escalables.
- La integración con revisión humana mediante A2I garantiza control de calidad y gobernanza para extracciones desafiantes.
FAQ
-
- **Q : Qué es Bedrock Data Automation en el contexto de IDP?**
Es una capacidad de Bedrock que introduce puntuación de confianza, datos de bounding box, clasificación automática y desarrollo rápido mediante blueprints para mejorar el procesamiento inteligente de documentos. - **Q : Cómo maneja el flujo varios tipos de documentos dentro de un solo proyecto?** **A :** El análisis de contenido aplica automáticamente el blueprint apropiado (estándar o personalizado) para cada tipo de documento, permitiendo el procesamiento de documentos diversos en un único proyecto. - **Q : Qué formatos y tipos de documentos son compatibles?** **A :** El flujo maneja PDFs y formatos de imagen (PDF, JPG, PNG, TIFF) y también DOC y DOCX, cubriendo documentos como inmunización, certificados de impuestos, formularios de inscripción y licencias de conducir. - **Q : Qué validaciones están incluidas?** **A :** Validaciones de presencia de la firma y de que la fecha de firma no esté en el futuro. - **Q : Cómo se integra la revisión humana?** **A :** Documentos con baja confianza son enviados a A2I para revisión humana con realce de zonas; tras la revisión, el flujo se reanuda y los resultados se almacenan en S3.
Referencias
More news

Llevar agentes de IA de concepto a producción con Amazon Bedrock AgentCore
Análisis detallado de cómo Amazon Bedrock AgentCore facilita la transición de aplicaciones de IA basadas en agentes desde un concepto de prueba hasta sistemas de producción empresariales, conservando memoria, seguridad, observabilidad y gestión escalable de herramientas.

Monitorear la inferencia por lotes de Bedrock de AWS con métricas de CloudWatch
Descubra cómo monitorear y optimizar trabajos de inferencia por lotes de Bedrock con métricas, alarmas y paneles de CloudWatch para mejorar rendimiento, costos y operación.

Solicitando precisión con Stability AI Image Services en Amazon Bedrock
Bedrock incorpora Stability AI Image Services con nueve herramientas para crear y editar imágenes con mayor precisión. Descubre técnicas de prompting para uso empresarial.

Escala la producción visual con Stability AI Image Services en Amazon Bedrock
Stability AI Image Services ya está disponible en Amazon Bedrock, ofreciendo capacidades de edición de imágenes listas para usar a través de la API de Bedrock y ampliando los modelos Stable Diffusion 3.5 y Stable Image Core/Ultra ya presentes.

Usar AWS Deep Learning Containers con Amazon SageMaker AI MLflow gestionado
Vea cómo los AWS Deep Learning Containers (DLCs) se integran con SageMaker AI gestionado por MLflow para equilibrar el control de la infraestructura y una gobernanza de ML sólida. Un flujo de TensorFlow para predicción de edad de abalones ilustra el seguimiento de extremo a extremo y la trazabilidad

Construir Flujos de Trabajo Agenticos con GPT OSS de OpenAI en SageMaker AI y Bedrock AgentCore
Visión general de extremo a extremo para implementar modelos GPT OSS de OpenAI en SageMaker AI y Bedrock AgentCore, impulsando un analizador de acciones multiagente con LangGraph, con cuantización MXFP4 de 4 bits y orquestación serverless.