Amazon Bedrock AgentCore Memory: Construyendo agentes contextuales
Sources: https://aws.amazon.com/blogs/machine-learning/amazon-bedrock-agentcore-memory-building-context-aware-agents, aws.amazon.com
TL;DR
- Amazon Bedrock AgentCore Memory es un servicio totalmente gestionado para la memoria de agentes IA, que ofrece contexto de corto plazo y conocimiento de largo plazo.
- Elimina la complejidad de infraestructuras de memoria y ofrece almacenamiento, extracción y recuperación integrados con valores predeterminados seguros y claves configurables.
- El sistema utiliza recursos de memoria, memoria a corto plazo de eventos y memoria a largo plazo de insights extraídos, todo organizado por namespaces y estrategias de memoria.
- Funcionalidades avanzadas incluyen branching (ramificación) y checkpoints para gestionar múltiples rutas de conversación y puntos de referencia dentro de un recurso de memoria.
- Se integra con componentes Bedrock AgentCore como AgentCore Runtime y AgentCore Observability para flujos de trabajo completos. La solución busca transformar conversaciones aisladas en relaciones usuario-agente continuas y evolutivas, recordando preferencias, historial y contexto a lo largo de sesiones. Este enfoque reduce repeticiones en conversaciones y favorece experiencias personalizadas manteniendo el control de lo que el agente recuerda. Amazon Bedrock AgentCore Memory promete una capa de memoria totalmente gestionada que los equipos pueden adoptar sin construir sus propias pilas de memoria.
Contexto y antecedentes
Los grandes modelos de lenguaje (LLMs) destacan por generar respuestas con apariencia humana, pero son fundamentalmente stateless; no retienen información entre interacciones. Esto obliga a los desarrolladores a crear sistemas de memoria para seguir el historial de conversaciones, preferencias de usuarios y mantener el contexto entre sesiones. En AWS Summit New York City 2025, AWS presentó Amazon Bedrock AgentCore Memory como un servicio dedicado a la gestión de la memoria de agentes. El objetivo es facilitar la construcción de agentes contextuales reduciendo la complejidad de la infraestructura de memoria y manteniendo el control sobre lo que se recuerda. AgentCore Memory permite a los agentes recordar el contexto inmediato dentro de una sesión (memoria de corto plazo) y almacenar percepciones y preferencias persistentes entre sesiones (memoria de largo plazo), permitiendo interacciones más inteligentes y personalizadas. Esta solución transforma conversaciones únicas en relaciones continuas, evitando repeticiones como “¿cuál es tu número de cuenta?” y recordando preferencias críticas. La integración con otros componentes de Bedrock AgentCore facilita mejorar agentes existentes con memoria persistente sin gestionar infraestructuras de almacenamiento separadas o lógicas de recuperación personalizadas. Fuente
Qué hay de nuevo
AgentCore Memory presenta un sistema de memoria estructurado basado en conceptos clave:
- Recurso de memoria: contenedor lógico que agrupa eventos brutos y memorias a largo plazo procesadas. Define la retención de datos, seguridad y la transformación de interacciones en insights. La expiración de eventos para la memoria de corto plazo puede configurarse hasta 365 días. Los datos están cifrados en reposo y en tránsito, con claves gestionadas por AWS por defecto, y opción de usar claves KMS gestionadas por el cliente para mayor control.
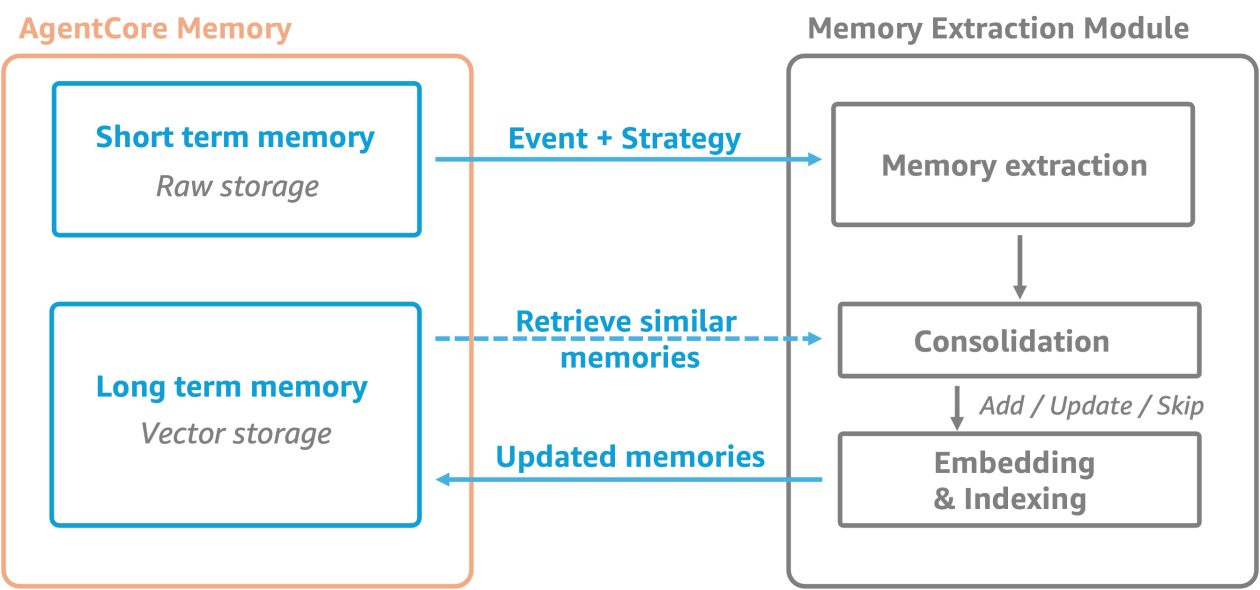
- Memoria de corto plazo: almacena datos brutos de interacción como eventos inmutables, organizados por actor y sesión. Existen dos tipos de eventos: Conversational (USER/ASSISTANT/TOOL u otros tipos de mensajes) y blob (contenido binario utilizado para checkpoints o estado del agente). Solo los eventos Conversational se usan para la extracción de memoria de largo plazo.
- Memoria de largo plazo: contiene insights, preferencias y conocimientos extraídos de los eventos brutos. La extracción ocurre de forma asincrónica después de la creación de los eventos, según las estrategias de memoria definidas para el recurso.
- Namespaces: proporcionan una organización jerárquica dentro de la memoria de largo plazo, permitiendo agrupar y categorizar memorias. Útiles en entornos multi-tenant (multiagente y multiusuario o ambos).
- Estrategias de memoria: definen cómo se transforman los eventos brutos en memorias útiles y dónde se almacenan. Por defecto, las estrategias integradas ignoran datos PII. Bedrock AgentCore Memory ofrece tres estrategias integradas y admite estrategias personalizadas para adaptar la extracción y consolidación a su dominio.
- Arquitectura e integración: está diseñado para integrarse con otros componentes de Bedrock AgentCore, como AgentCore Runtime y AgentCore Observability. El diseño API-first con defaults verificados facilita implementar capacidades básicas de memoria rápidamente, manteniendo la extensibilidad para escenarios avanzados.
- Rama y puntos de control (uso avanzado): la ramificación permite crear rutas de conversación alternativas desde un punto en el historial. Un nuevo branch se crea dentro del mismo recurso de memoria utilizando el mismo actor_id y session_id, con un nombre de rama y rootEventId de origen. Esto permite gestionar múltiples trayectorias de conversación dentro del mismo recurso de memoria. Dispositivos de puntos de control permiten guardar estados para volver atrás más tarde.
- Blob y formatos de datos: los blobs pueden contener datos en formatos variados y no tienen que ser necesariamente conversacionales; estos eventos pueden ser útiles para enriquecer el estado del agente, pero no se extraen para la memoria de largo plazo. La arquitectura de AgentCore Memory está diseñada para trabajar de forma fluida con otros recursos Bedrock AgentCore y ofrecer una experiencia de memoria completa que permite recordar, aprender y adaptarse a lo largo del tiempo.
Por qué es importante (impacto para desarrolladores/empresas)
Para desarrolladores, AgentCore Memory reduce la carga de construir y mantener capas de memoria para agentes IA. Al ofrecer una memoria totalmente gestionada con capacidades de almacenamiento, extracción y recuperación integradas, los equipos pueden centrarse en características de mayor valor en lugar de integrar componentes de memoria dispersos. Las empresas se benefician de interacciones más naturales y personalizadas, ya que los agentes retienen contexto entre sesiones, recuerdan preferencias y mantos de historial, lo que mejora la eficiencia operativa y la satisfacción del usuario. La capacidad de configurar la retención, controlar la seguridad y elegir entre claves KMS gestionadas por AWS o por el cliente aporta gobernanza y cumplimiento para implementaciones empresariales. Las funciones de ramificación y puntos de control añaden sofisticación a los flujos de trabajo de los agentes, permitiendo múltiples rutas de conversación y un seguimiento robusto del progreso en tareas complejas.
Detalles técnicos o Implementación (componentes clave)
AgentCore Memory se compone de varios componentes que trabajan en conjunto para ofrecer memoria persistente sin sacrificar la privacidad o el rendimiento. Los elementos clave son:
Recurso de memoria
La base de una implementación de memoria es el recurso de memoria. Este recurso agrupa eventos brutos y memorias a largo plazo procesadas. Al crear el recurso, se definen la retención de datos en la memoria de corto plazo (expiración de eventos de hasta 365 días), la seguridad y la transformación de interacciones en insights. Los datos dentro del recurso están cifrados en reposo y en tránsito, con claves gestionadas por AWS por defecto; existe la opción de usar claves KMS gestionadas por el cliente para mayor control.
Memoria a corto plazo y eventos
La memoria a corto plazo almacena datos brutos de interacción como eventos inmutables, organizados por actor y sesión. Hay dos tipos de eventos:
- Conversational: mensajes como USER, ASSISTANT, TOOL u otros tipos de mensajes que impulsan el diálogo.
- Blob: contenido binario utilizado para checkpoints o estado del agente. Solo los eventos Conversational alimentan la memoria a largo plazo. La creación de un evento suele requerir tres identificadores, formando una estructura jerárquica que facilita la recuperación de contexto relevante sin cargar datos no relacionados.
Memoria a largo plazo y extracción
La memoria a largo plazo contiene los insights, preferencias y conocimientos extraídos de los eventos brutos. A diferencia de la memoria a corto plazo, la memoria a largo plazo persiste entre sesiones. La extracción se realiza de forma asíncrona tras la creación de los eventos, según las estrategias de memoria definidas para el recurso, para producir memorias organizadas y recuperables.
Namespaces
Los Namespaces proporcionan una organización jerárquica de las memorias a largo plazo, permitiendo agrupar y categorizar memorias. Son útiles en entornos multi-tenant y multi-agente, permitiendo estructurar las memorias de acuerdo con dominios o flujos de trabajo empresariales.
Estrategias de memoria
Las estrategias definen cómo se transforman los eventos brutos en memorias útiles y dónde se almacenan las memorias extraídas. Cada estrategia se configura con un namespace específico para consolidar las memorias extraídas, creando una estructura clara para diferentes tipos de memorias. Por defecto, las estrategias integradas ignoran datos PII. Bedrock AgentCore Memory ofrece tres estrategias integradas y admite estrategias personalizadas que permiten adaptar el proceso de extracción y consolidación a su dominio.
Rama y puntos de control (avanzado)
La ramificación permite crear caminos alternativos de conversación a partir de un punto en el historial de eventos. Un nuevo branch se crea dentro del mismo recurso de memoria usando el mismo actor_id y session_id, con un nombre de rama y rootEventId de origen. Esto permite gestionar múltiples rutas de conversación dentro del mismo recurso de memoria. Los puntos de control permiten guardar estados específicos de la conversación y volver a ellos más tarde.
Blob y formatos de datos
Los eventos blob pueden contener datos en formatos variados y no necesariamente son conversacionales; estos datos pueden enriquecer el estado del agente. Sin embargo, estos eventos se ignoran para la extracción de memoria a largo plazo.
Tabla rápida
| Concepto | Función | Alcance/Retención | Notas |---|---|---|---| | Recurso de memoria | Base para la memoria | Corto plazo: hasta 365 días | Define retención, seguridad y transformación de datos |Memoria a corto plazo | Eventos brutos | Retenido por expiración | Conversational y Blob; solo Conversational alimenta memoria a largo plazo |Memoria a largo plazo | Insights y memorias extraídas | Persiste entre sesiones | Extracción asincrónica; organizada por namespaces y estrategias |Namespaces | Organización jerárquica | Estructura por dominio | Útil para multi-tenant |Estrategias de memoria | Extracción/consolidación | Por namespace | 3 integradas; admite personalizadas |Rama | Caminos de conversación | Dentro del mismo recurso | Usa rootEventId y nombre de rama |Puntos de control | Progreso guardado | Recuperables vía API | Útiles para flujos complejos |
Puntos clave
- Memory Core ofrece una capa de memoria totalmente gestionada con memoria a corto y a largo plazo, reduciendo la necesidad de infraestructuras de memoria personalizadas.
- El cifrado en tránsito y en reposo está activado por defecto con claves gestionadas por AWS, con opción de claves KMS del cliente.
- La memoria se organiza mediante recursos, namespaces y estrategias, con extracción de memoria a largo plazo asincrónica.
- Funcionalidades avanzadas como branching y checkpoints permiten gestionar diálogos complejos y rastrear el progreso.
- La integración con runtimes y herramientas de observabilidad de Bedrock AgentCore facilita flujos de trabajo completos de agentes.
Preguntas frecuentes (FAQ)
- Q: ¿Qué problema soluciona Amazon Bedrock AgentCore Memory? A: Proporciona una capa de memoria totalmente gestionada que mantiene el contexto inmediato y el conocimiento a largo plazo para agentes IA, evitando tener que construir infraestructuras de memoria propias.
- Q: ¿Cuáles son los componentes principales de la memoria? A: Recurso de memoria, memoria a corto plazo, memoria a largo plazo, namespaces y estrategias de memoria.
- Q: ¿Cómo se garantiza la seguridad de los datos? A: Los datos se cifran en reposo y en tránsito; por defecto se utilizan claves gestionadas por AWS, con opción de claves KMS del cliente.
- Q: ¿Para qué sirven branching y checkpoints? A: Branching permite explorar rutas de conversación múltiples; los checkpoints guardan puntos de progreso para referencia futura.
- Q: ¿Puedo personalizar la extracción de memorias? A: Sí. Se ofrecen tres estrategias de memoria integradas y soporte para estrategias personalizadas para adaptar la extracción y consolidación a su dominio.
Referencias
More news

Llevar agentes de IA de concepto a producción con Amazon Bedrock AgentCore
Análisis detallado de cómo Amazon Bedrock AgentCore facilita la transición de aplicaciones de IA basadas en agentes desde un concepto de prueba hasta sistemas de producción empresariales, conservando memoria, seguridad, observabilidad y gestión escalable de herramientas.

Monitorear la inferencia por lotes de Bedrock de AWS con métricas de CloudWatch
Descubra cómo monitorear y optimizar trabajos de inferencia por lotes de Bedrock con métricas, alarmas y paneles de CloudWatch para mejorar rendimiento, costos y operación.

Solicitando precisión con Stability AI Image Services en Amazon Bedrock
Bedrock incorpora Stability AI Image Services con nueve herramientas para crear y editar imágenes con mayor precisión. Descubre técnicas de prompting para uso empresarial.

Escala la producción visual con Stability AI Image Services en Amazon Bedrock
Stability AI Image Services ya está disponible en Amazon Bedrock, ofreciendo capacidades de edición de imágenes listas para usar a través de la API de Bedrock y ampliando los modelos Stable Diffusion 3.5 y Stable Image Core/Ultra ya presentes.

Usar AWS Deep Learning Containers con Amazon SageMaker AI MLflow gestionado
Vea cómo los AWS Deep Learning Containers (DLCs) se integran con SageMaker AI gestionado por MLflow para equilibrar el control de la infraestructura y una gobernanza de ML sólida. Un flujo de TensorFlow para predicción de edad de abalones ilustra el seguimiento de extremo a extremo y la trazabilidad

Construir Flujos de Trabajo Agenticos con GPT OSS de OpenAI en SageMaker AI y Bedrock AgentCore
Visión general de extremo a extremo para implementar modelos GPT OSS de OpenAI en SageMaker AI y Bedrock AgentCore, impulsando un analizador de acciones multiagente con LangGraph, con cuantización MXFP4 de 4 bits y orquestación serverless.