
TextQuests: Cómo rinden los LLMs en juegos textuales clásicos
TL;DR
- TextQuests es un benchmark construido sobre 25 juegos clásicos de Infocom para probar LLMs como agentes autónomos en entornos exploratorios de larga duración.
- Cada modelo realiza dos ejecuciones (Con Pistas y Sin Pistas), hasta 500 pasos, manteniendo el historial completo; las métricas son Progreso en el Juego y Daño.
- Evaluaciones de largo contexto (más de 100K tokens) muestran alucinaciones, repetición de acciones y dificultades de razonamiento espacial en los modelos actuales.
Contexto y antecedentes
Los rápidos avances en grandes modelos de lenguaje han llevado a progresos notables en benchmarks estáticos de conocimiento como MMLU y GPQA y a mejoras en evaluaciones especializadas como HLE. No obstante, el éxito en tareas estáticas no siempre se traduce en eficacia en entornos interactivos dinámicos donde los agentes deben actuar, planear y aprender durante sesiones largas. Para evaluar agentes autónomos existen dos vías: usar entornos del mundo real (o con herramientas) que se centran en habilidades concretas, o usar entornos simulados de mundo abierto que exigen razonamiento sostenido. Esta última captura mejor la capacidad de operar de forma autónoma en entornos exploratorios y es más fácil de evaluar. Trabajos recientes en esta dirección incluyen Balrog, ARC-AGI y demostraciones de modelos como Claude y Gemini jugando Pokémon. Sobre esta base, Hugging Face presenta TextQuests como banco de pruebas para el razonamiento del LLM que actúa como núcleo de un agente. Detalles en: TextQuests.
Qué hay de nuevo
TextQuests emplea 25 juegos clásicos de Infocom — aventuras textuales que históricamente podían llevar a jugadores humanos más de 30 horas y cientos de acciones precisas para resolverse. Estos juegos requieren:
- Razonamiento de largo contexto: mantener y utilizar un historial creciente de acciones y observaciones.
- Aprendizaje por exploración: mejorar mediante ensayo y error, interrogando fallos y ajustando planes gradualmente. Cada modelo realiza dos corridas: una con las pistas oficiales del juego (“Con Pistas”) y otra sin ellas (“Sin Pistas”). Cada corrida tiene un máximo de 500 pasos y termina antes si el agente completa el juego. El historial completo del juego se conserva sin truncamiento; optimizaciones modernas de inferencia como el caché de prompt hacen viable esta evaluación de largo contexto.
Por qué importa (impacto para desarrolladores/empresas)
TextQuests examina capacidades relevantes para sistemas agentes del mundo real: planificar a lo largo de secuencias extensas, adaptarse aprendiendo de la experiencia y operar con eficiencia en tiempo de prueba.
- Para desarrolladores de asistentes autónomos, el benchmark pone de manifiesto áreas donde los modelos deben mejorar para soportar flujos de trabajo multi‑paso y exploratorios.
- Para empresas que evalúan LLMs, TextQuests revela compensaciones entre rendimiento y coste de inferencia: más cómputo en el test suele mejorar rendimiento hasta cierto punto.
- Para equipos de seguridad y alineamiento, la métrica de Daño ofrece una señal sobre la propensión de los agentes a ejecutar acciones consideradas dañinas en juego.
Detalles técnicos o implementación
Diseño de evaluación y métricas principales:
| Aspecto | Especificación |
|---|---|
| Juegos | 25 títulos clásicos de Infocom |
| Corridas por modelo | Dos: Con Pistas y Sin Pistas |
| Pasos máximos | 500 pasos por corrida (se detiene si se completa) |
| Política de historial | Historial completo del juego mantenido sin truncamiento |
| Escala de contexto | Ventanas de contexto pueden exceder 100K tokens |
| Métricas | Progreso del juego; Daño |
| El Progreso del juego se calcula a partir de puntos de control etiquetados que representan objetivos necesarios para terminar un juego. Daño se mide rastreando acciones en el juego clasificadas como dañinas y promediando esa puntuación a través de los juegos para obtener una señal de modelo. | |
| La evaluación de largo contexto es factible gracias al uso de caché de prompt y optimizaciones de inferencia, por lo que mantener un historial creciente no resulta prohibitivamente costoso. Las corridas no ofrecen herramientas externas; el objetivo es probar el LLM como columna vertebral del razonamiento del agente. | |
| Modos de fallo observados y hallazgos conductuales: |
- Alucinación sobre interacciones previas: agentes creen haber recogido objetos cuando no lo han hecho.
- Sesgo de repetición: al crecer el contexto, los agentes tienden a repetir acciones anteriores en lugar de generar planes nuevos.
- Fallos en razonamiento espacial: ejemplos incluyen dificultad para regresar tras subir un acantilado en Wishbringer o problemas con el Laberinto en Zork I.
- Compromiso eficiencia‑rendimiento: más tokens de razonamiento en inferencia mejoran la actuación hasta cierto punto; muchas acciones exploratorias no requieren profundidad de razonamiento.
Conclusiones clave
- TextQuests ofrece un benchmark abierto y reproducible para estresar LLMs en tareas exploratorias de largo horizonte usando 25 juegos Infocom.
- La evaluación con historial completo destapa alucinaciones, repetición y vulnerabilidades en el razonamiento espacial en modelos de vanguardia.
- La eficiencia en inferencia importa: los beneficios de más cómputo disminuyen pasado cierto umbral.
- El benchmark incluye una métrica de Daño para destacar comportamientos potencialmente dañinos.
- Desarrolladores de modelos open-source pueden enviar modelos al TextQuests Leaderboard contactando a [email protected].
FAQ
-
Qué tipos de juegos incluye TextQuests?
Incluye 25 juegos clásicos de Infocom, aventuras textuales extensas y detalladas.
-
Cómo se evalúan los modelos?
Dos corridas por modelo (Con Pistas y Sin Pistas), cada una limitada a 500 pasos y con historial completo preservado.
-
Qué métricas informa el benchmark?
Progreso del juego (a partir de checkpoints etiquetados) y Daño (promedio de acciones clasificadas como dañinas).
-
Por qué es crítico el contexto largo?
Los juegos requieren planificación multi‑paso y aprendizaje por experiencia; las ventanas de contexto pueden superar los 100K tokens.
-
Cómo participar en el leaderboard?
Equipos open-source pueden enviar su participación por correo a [email protected].
Referencias
- Anuncio original: TextQuests
- Recurso comunitario citado en la fuente: https://github.com/CharlesCNorton/Language-Model-Tools/tree/main/AutoMUD
More news

Anthropic endurece las reglas de uso de Claude ante un panorama de IA más peligroso
Anthropic prohíbe ayudar a desarrollar armas CBRN y explosivos de alto rendimiento, añade restricciones de ciberseguridad, ajusta su política política y aclara requisitos de alto riesgo.

Build a scalable containerized web application on AWS using the MERN stack with Amazon Q Developer – Part 1
In a traditional SDLC, a lot of time is spent in the different phases researching approaches that can deliver on requirements: iterating over design changes, writing, testing and reviewing code, and configuring infrastructure. In this post, you learned about the experience and saw productivity gains
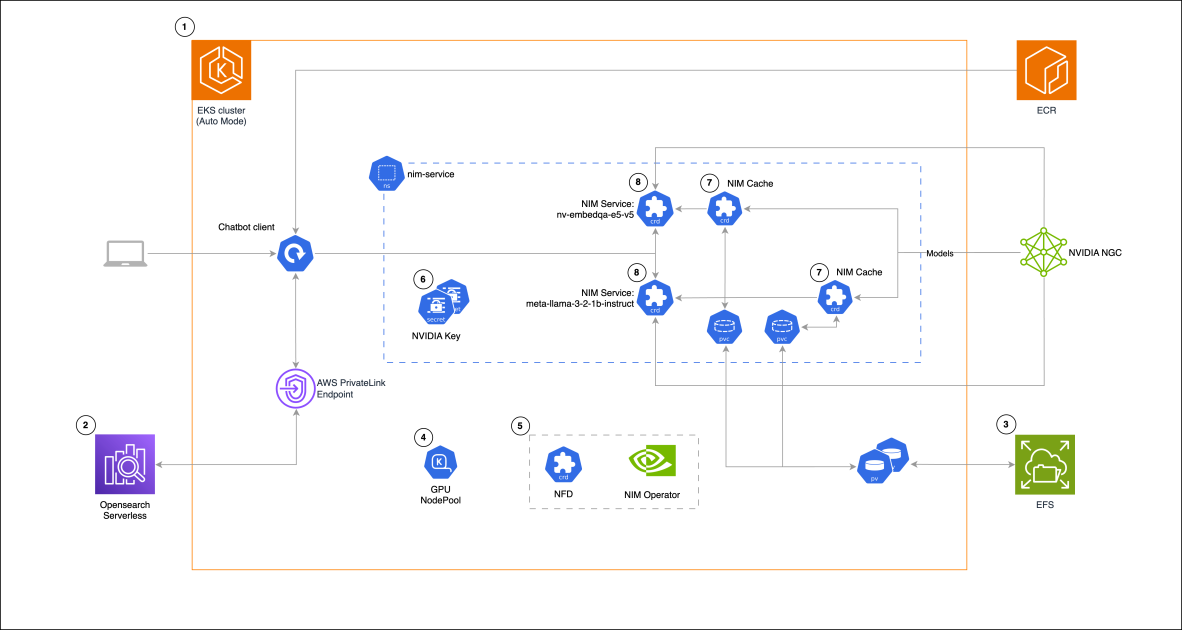
Building a RAG chat-based assistant on Amazon EKS Auto Mode and NVIDIA NIMs
In this post, we demonstrate the implementation of a practical RAG chat-based assistant using a comprehensive stack of modern technologies. The solution uses NVIDIA NIMs for both LLM inference and text embedding services, with the NIM Operator handling their deployment and management. The architectu

GPT-5 decepcionó las expectativas pero mejoró costo, velocidad y capacidad de programación
El lanzamiento de GPT-5 recibió reacciones mixtas: mejoras incrementales en benchmarks, reducción de costos y latencia, mejor desempeño en programación, pero críticas al tono de escritura y errores inesperados.

Introducing Amazon Bedrock AgentCore Gateway: Transforming enterprise AI agent tool development
In this post, we discuss Amazon Bedrock AgentCore Gateway, a fully managed service that revolutionizes how enterprises connect AI agents with tools and services by providing a centralized tool server with unified interface for agent-tool communication. The service offers key capabilities including S
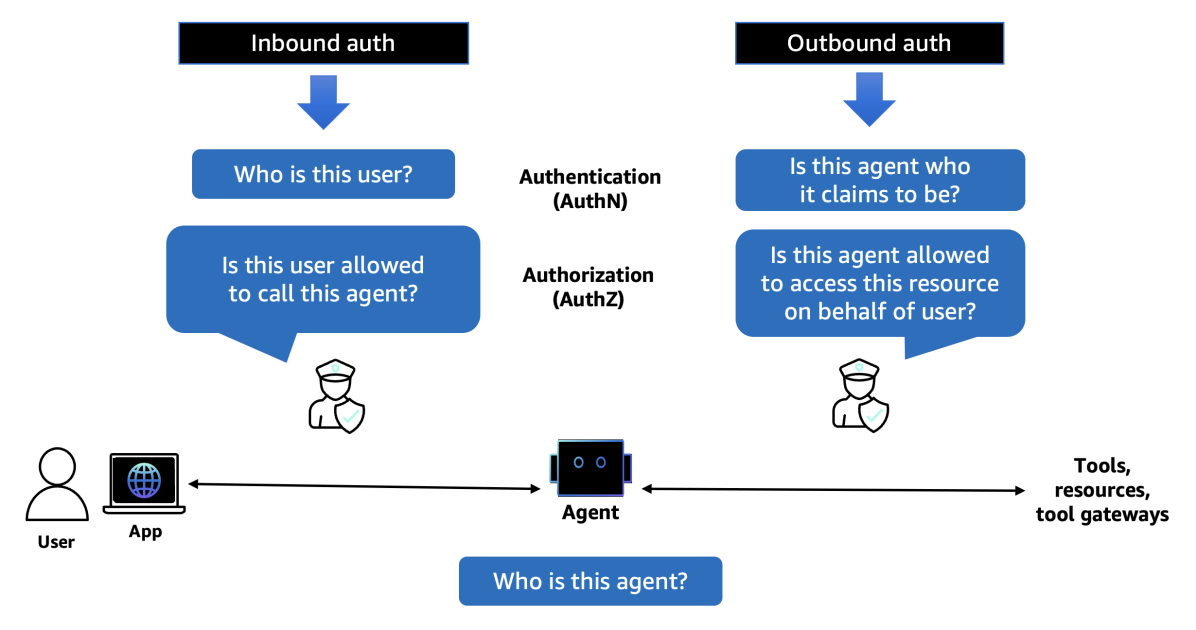
Introducing Amazon Bedrock AgentCore Identity: Securing agentic AI at scale
In this post, we explore Amazon Bedrock AgentCore Identity, a comprehensive identity and access management service purpose-built for AI agents that enables secure access to AWS resources and third-party tools. The service provides robust identity management features including agent identity director