Volviendo al Futuro: Evaluando agentes de IA en la predicción de eventos futuros
Sources: https://huggingface.co/blog/futurebench, Hugging Face Blog
TL;DR
- FutureBench evalúa a los agentes de IA para predecir eventos futuros, no solo para recordar hechos del pasado, con el fin de medir razonamiento y toma de decisiones en el mundo real. FutureBench sostiene que la previsión de futuros ofrece una forma de inteligencia más transferible que los benchmarks estáticos.
- El benchmark utiliza dos flujos de datos complementarios: un flujo de trabajo de scraping de noticias basado en SmolAgents que genera preguntas con horizonte temporal definido y preguntas de Polymarket, una plataforma de mercados de predicción.
- La evaluación se organiza en tres niveles para aislar dónde provienen las mejoras: (1) diferencias de frameworks, (2) rendimiento de herramientas y (3) capacidades del modelo. Esto ayuda a decidir dónde invertir en herramientas, acceso a datos o diseño de modelos.
- Resultados iniciales muestran que los modelos con capacidad de agente superan a los modelos de lenguaje básicos sin acceso a Internet, con diferencias notables en cómo los modelos recaban información (búsqueda frente a scraping web) que afectan el costo y los resultados.
- El leaderboard en vivo y el toolkit ligero permiten una evaluación continua, con patrones claros en cómo los modelos abordan las tareas de predicción.
Contexto y antecedentes
Los benchmarks IA tradicionales suelen medir preguntas sobre el pasado, probando conocimientos almacenados, hechos estáticos o problemas ya resueltos. Los autores de FutureBench argumentan que el verdadero progreso hacia una IA útil, y potencialmente hacia una AGI, dependerá de la capacidad de sintetizar información actual y predecir resultados futuros. Las preguntas de previsión abarcan ciencia, economía, geopolítica y adopción tecnológica, requiriendo razonamiento sofisticado, síntesis y ponderación de probabilidades, más que simple coincidencia de patrones. La previsión es verificable con el tiempo, proporcionando una medida objetiva de rendimiento FutureBench. El enfoque de FutureBench se alinea con flujos de trabajo prácticos de previsión donde la calidad de la recopilación de información influye directamente en la toma de decisiones. Utilizando noticias en vivo y mercados de predicción, las preguntas se anclan en resultados reales, promoviendo el razonamiento bajo incertidumbre como un reto central. El objetivo es que la predicción no sea adivinación infundada, sino una síntesis de datos relevantes para inferir desenlaces probables. El ecosistema también enfatiza la importancia de un pipeline impulsado por agentes: recopilación de datos, formulación de preguntas y razonamiento estructurado. La evaluación utiliza un conjunto de herramientas ligero para mantener la tarea desafiante y enfatizar estrategias de obtención de información. El objetivo es revelar cómo diferentes modelos se desempeñan en tareas de predicción del mundo real y facilitar un marco reproducible para experimentar con nuevas arquitecturas de agentes y fuentes de datos.
Novedades
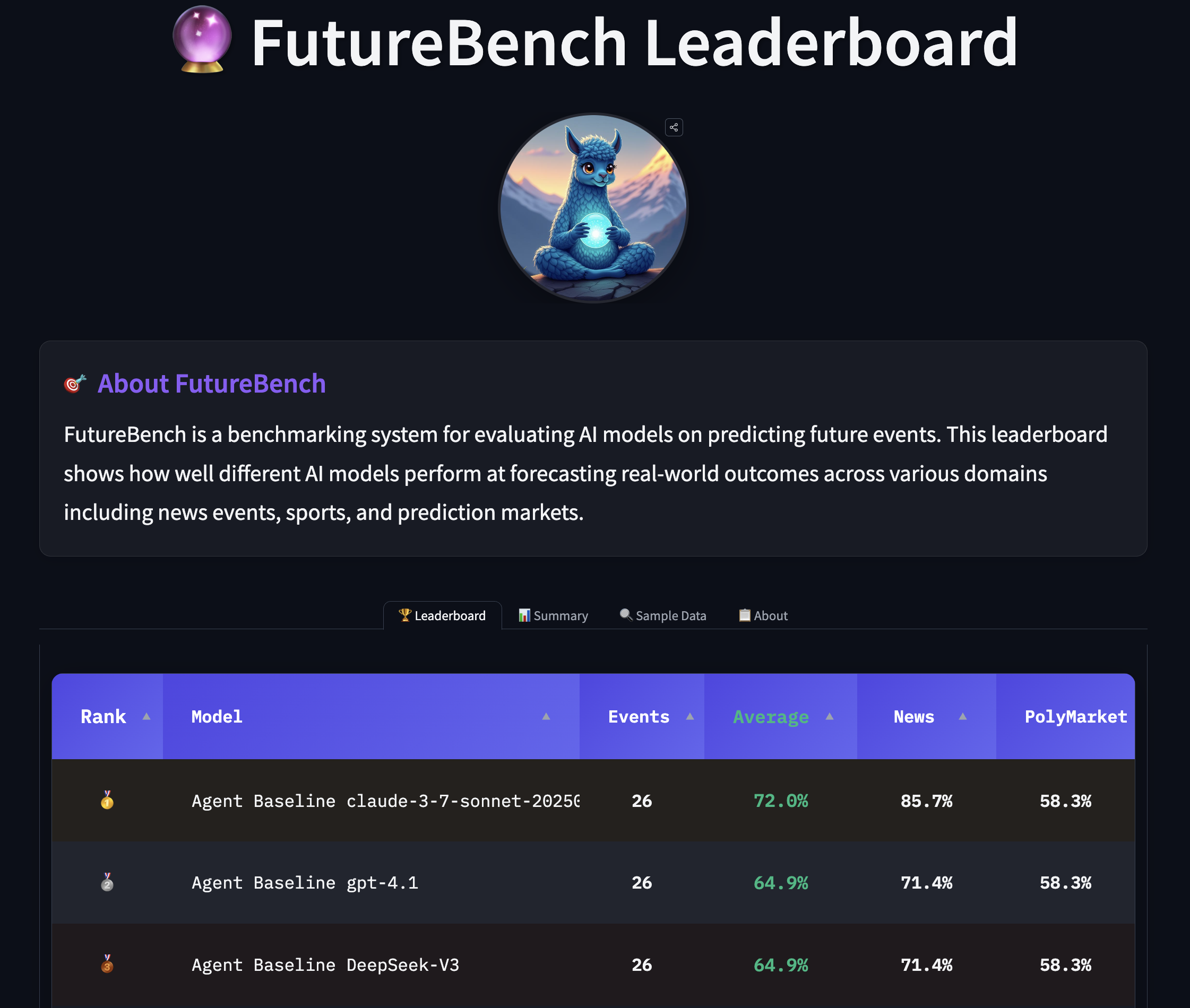
FutureBench presenta dos fuentes principales de preguntas con enfoque en el futuro. Primero, un agente SmolAgents rastrea grandes sitios de noticias para generar cinco preguntas por sesión de scraping, cada una con un horizonte de una semana. En segundo lugar, Polymarket aporta un flujo de preguntas de mercados de predicción, alrededor de ocho por semana. Se aplica filtrado para eliminar preguntas generales sobre clima y ciertos temas de mercados, manteniendo el conjunto manejable y relevante; algunas preguntas pueden tener períodos de realización que se extienden más allá de una semana. El marco de evaluación se estructura en tres niveles. Nivel 1 aísla efectos del marco comparando dos frameworks de agentes manteniendo constantes el LLM y las herramientas. Nivel 2 evalúa rendimiento de herramientas manteniendo marco y LLM constantes, comparando motores de búsqueda. Nivel 3 examina capacidades del modelo usando las mismas herramientas y marco, pero con LLMs diferentes. Este enfoque permite atribuir mejoras de rendimiento a componentes específicos. El sistema también evalúa el cumplimiento de instrucciones, exigiendo formatos precisos que puedan ser parseados y ejecutados. En la práctica, FutureBench usa SmolAgents como baseline para todas las preguntas y calcula el rendimiento tanto en los modelos base como en configuraciones basadas en agentes. La tarea de predicción se realiza con un toolkit enfocado para forzar una recopilación estratégica de información, manteniendo el acceso a capacidades necesarias. Observaciones iniciales señalan que los modelos basados en agentes superan a LMs sin Internet, con diferencias notables en estrategias de obtención de información, algunas basadas en búsquedas y otras en scraping más profundo, lo que puede aumentar el recuento de tokens de entrada. Un ejemplo muestra cómo un modelo evalúa datos CPI y dinámicas de tarifas para estimar una previsión calibrada, frente a otro que se apoya en el consenso del mercado y datos CPI de mayo. Estos hallazgos provienen de experimentos en vivo descritos en el post FutureBench FutureBench. FutureBench también ofrece un leaderboard en vivo en Hugging Face Spaces, fomentando la comparación entre agentes, conjuntos de datos y modelos. El diseño es modular para permitir a los investigadores añadir nuevos agentes, herramientas o fuentes de datos y comparar resultados con una base común. Este enfoque facilita la apertura de la evaluación y la extensión por parte de la comunidad.
¿Por qué importa (impacto para desarrolladores/empresas)?
Los benchmarks centrados en la previsión ofrecen varias ventajas prácticas para equipos de IA aplicados a la toma de decisiones:
- Evaluación más relevante del razonamiento en incertidumbre: al priorizar predicciones futuras, el benchmark se alinea mejor con casos de uso que requieren soporte a decisiones estratégicas, gestión de riesgos y políticas.
- Resultados verificables y transparentes: las predicciones se vinculan a resultados reales con ventanas de realización definidas, permitiendo verificación objetiva a lo largo del tiempo.
- Diagnóstico claro: el marco de tres niveles proporciona indicaciones prácticas sobre dónde invertir: arquitectura de agentes, herramientas de acceso a datos o capacidades de razonamiento del modelo.
- Datos y formatos prácticos: el uso de noticias en vivo y mercados de predicción replica flujos de trabajo profesionales, facilitando la adopción en entornos empresariales.
- Consideraciones de costo y eficiencia: el análisis de estrategias de obtención de información ayuda a equilibrar calidad de datos y costos computacionales, especialmente para despliegues a escala. Para organizaciones que construyen IA para soporte a decisiones, FutureBench ofrece un marco sólido para medir y diagnosticar capacidades de previsión, con un enfoque en claridad, verificabilidad y relevancia práctica. El marco complementa benchmarks de precisión tradicionales al abordar escenarios en los que las predicciones guían la estrategia, la gestión de riesgos o el diseño de políticas. Un leaderboard en vivo facilita la comparación continua entre enfoques y herramientas, contribuyendo a un ecosistema de evaluación abierto FutureBench.
Detalles técnicos o Implementación
FutureBench se apoya en dos pipelines de predicción y un marco de evaluación estructurado:
- Fuentes de datos: scraping de noticias en tiempo real con SmolAgents para generar cinco preguntas por sesión; preguntas de Polymarket alrededor de ocho por semana. Se aplican filtros para eliminar preguntas genéricas y temas de mercado poco útiles, reconociendo que las ventanas de realización pueden extenderse.
- Herramientas y baseline: una caja de herramientas enfocada para forzar una recolección estratégica de información, con SmolAgents como baseline para todas las preguntas. Se reporta rendimiento para modelos base y configuraciones con agentes.
- Niveles de evaluación y controles: nivel 1 aísla efectos de marco comparando dos frameworks de agentes manteniendo constantes herramientas y LLM; nivel 2 evalúa rendimiento de herramientas manteniendo constante el marco y el LLM; nivel 3 compara capacidades del modelo con las mismas herramientas y marco. Este diseño facilita atribuir mejoras a componentes específicos.
- Comportamiento de modelos: las tendencias muestran que los enfoques basados en agentes superan a LMs sin acceso a Internet. Las diferencias en recopilación de información se hacen evidentes: algunos modelos dependen más de búsquedas; otros exploran la web y hacen scraping más profundo, lo que puede aumentar los tokens de entrada y los costos. Un ejemplo ilustra a un modelo que equilibra CPI, tarifas y política para estimar una predicción calibrada frente a otro que se apoya en el consenso del mercado. Algunas pruebas incluyen ataques de scraping directo a sitios oficiales, con resultados mixtos. Estos hallazgos provienen de exploraciones en vivo descritas en el post FutureBench FutureBench.
Tabla: Elementos clave de la configuración de FutureBench
| Componente | Descripción | Relevancia |---|---|---| | Fuentes de datos | Noticias en vivo y preguntas Polymarket | Anclan las tareas de predicción en eventos reales |Cadencia de preguntas | ~5 por sesión de scraping; ~8 por semana de Polymarket | Mantiene un flujo constante de material de evaluación |Horizontes | Principalmente ventanas de una semana; algunos plazos pueden extenderse | Prueba la capacidad de prever dentro de marcos útiles |Niveles de evaluación | Marco, herramientas, capacidades del modelo | Diagnóstico sobre dónde mejorar |Línea base | SmolAgents como base; LLMs | Demuestra el valor de enfoques basados en agentes |
Puntos clave
- Los benchmarks centrados en previsión desplazan el foco de la memorización hacia el razonamiento, la síntesis y la gestión de la incertidumbre.
- El marco en tres niveles permite identificar si las mejoras provienen del marco de agentes, de las herramientas o de las capacidades del modelo.
- Los enfoques basados en agentes tienden a superar a LMs simples en estas tareas, con modelos más fuertes que muestran mayor estabilidad de predicción.
- Las estrategias de obtención de información influyen en los resultados y costos; distintos modelos equilibran búsqueda y scraping de maneras diversas.
- FutureBench ofrece un leaderboard en vivo y un toolkit extensible, invitando a investigadores a incorporar nuevos agentes, herramientas o fuentes de datos y comparar resultados con una base común.
FAQ
-
¿Qué es FutureBench?
Un benchmark para evaluar agentes de IA en la predicción de eventos futuros utilizando fuentes reales.
-
¿Qué fuentes alimentan FutureBench?
Noticias en vivo vía scraping con SmolAgents y preguntas de Polymarket.
-
¿Cuántas preguntas se generan por sesión y por semana?
proximadamente 5 por sesión de scraping y ~8 preguntas de Polymarket por semana.
-
¿Cómo se estructuran las evaluaciones?
En tres niveles: marco, herramientas y capacidades del modelo.
-
¿Dónde ver los resultados en vivo?
El leaderboard está disponible en Hugging Face Spaces dentro del ecosistema FutureBench [FutureBench](https://huggingface.co/blog/futurebench).
Referencias
More news

Scaleway se une a los Proveedores de Inferencia de Hugging Face para Inferencia Serverless y de Baja Latencia
Scaleway es ahora un Proveedor de Inferencia soportado en Hugging Face Hub, lo que permite inferencia serverless directamente en las páginas de modelos con los SDK de JS y Python. Accede a modelos open-weight populares y disfruta de flujos de IA escalables y de baja latencia.

Reduciendo la latencia en frío para la inferencia de LLM con NVIDIA Run:ai Model Streamer
Análisis detallado de cómo NVIDIA Run:ai Model Streamer disminuye los tiempos de arranque en frío al transmitir pesos a la memoria GPU, con benchmarks en GP3, IO2 y S3.

Cómo msg mejoró la transformación de la fuerza laboral de RR. HH. con Amazon Bedrock y msg.ProfileMap
Este artículo explica cómo msg automatizó la armonización de datos para msg.ProfileMap usando Amazon Bedrock para impulsar flujos de enriquecimiento impulsados por LLM, aumentando la precisión de la coincidencia de conceptos de RR. HH., reduciendo la carga de trabajo manual y alineándose con la UE A

Cómo la quantización consciente (QAT) recupera precisión en inferencia de baja precisión
Analiza QAT y QAD como métodos para recuperar precisión en modelos de baja precisión, utilizando el TensorRT Model Optimizer y formatos FP8/NVFP4/MXFP4.

Acelerar la Inferencia de Estructura de Proteínas en Más de 100x con NVIDIA RTX PRO 6000 Blackwell Server Edition
El RTX PRO 6000 Blackwell Server Edition de NVIDIA acelera de forma notable la inferencia de estructuras de proteínas, permitiendo flujos de trabajo end-to-end en GPU con OpenFold y TensorRT, hasta 138x más rápido que AlphaFold2.

Por qué los modelos de lenguaje 'alucinan' y cómo OpenAI está cambiando las evaluaciones para la fiabilidad
OpenAI explica que las alucinaciones en modelos de lenguaje provienen de incentivos de evaluación que premian la conjetura sobre la incertidumbre. El artículo detalla cómo puntajes y benchmarks sensibles a la incertidumbre pueden reducir errores confiados.