
PLAID: Reutilización de modelos de plegamiento de proteínas para generación con difusión latente
Sources: http://bair.berkeley.edu/blog/2025/04/08/plaid, bair.berkeley.edu
PLAID es un modelo generativo multimodal que genera simultáneamente la secuencia 1D de proteínas y su estructura 3D, aprendiendo el espacio latente de modelos de plegamiento de proteínas. El galardón del Premio Nobel 2024 a AlphaFold2 marca un momento importante de reconocimiento del papel de la IA en la biología. ¿Qué sigue después del plegamiento de proteínas? En PLAID, desarrollamos un método que aprende a muestrear desde el espacio latente de modelos de plegamiento para generar nuevas proteínas. Puede aceptar indicaciones compuestas de función y organismo, y puede entrenarse en bases de datos de secuencias, que son 2–4 órdenes de magnitud más grandes que las bases de datos de estructuras. A diferencia de muchos modelos previos de generación de estructuras proteicas, PLAID aborda el entorno de co-generación multimodal: generar simultáneamente secuencias discretas y coordenadas estructurales all-atom continuas. Aunque trabajos recientes muestran promesas para la capacidad de modelos de difusión para generar proteínas, aún existen limitaciones en modelos anteriores que los hacen poco prácticos para aplicaciones del mundo real, como: generar proteínas por sí solo no es tan útil como controlar la generación para obtener proteínas útiles. ¿Qué podría parecer una interfaz para esto? Para inspiración, consideremos cómo se controlaría la generación de imágenes mediante indicaciones textuales compuestas (ejemplo de Liu et al., 2022). En PLAID, imitamos esta interfaz de control. El objetivo final es controlar la generación completamente mediante una interfaz textual, pero aquí consideramos restricciones compuestas para dos ejes como prueba de concepto: función y organismo: aprender la conexión función-estructura-secuencia. PLAID aprende el patrón de coordinación tetraédrico de cisteína-Fe 2+ / Fe 3+ que a menudo se encuentra en metaloproteínas, manteniendo una alta diversidad a nivel de secuencia. Otro aspecto importante del modelo PLAID es que solo se requieren secuencias para entrenar el modelo generativo. Los modelos generativos aprenden la distribución de datos definida por sus datos de entrenamiento, y las bases de datos de secuencias son considerablemente más grandes que las de estructuras, ya que las secuencias son mucho más baratas de obtener. Aprender a partir de una base de datos más grande y más amplia. El costo de obtener secuencias de proteínas es mucho menor que caracterizar estructuras experimentalmente, y las bases de datos de secuencias son 2–4 órdenes de magnitud mayores que las estructurales. La razón por la que podemos entrenar el modelo generativo para generar estructuras usando solo datos de secuencia es aprendiendo un modelo de difusión sobre el espacio latente de un modelo de plegamiento de proteínas. Entonces, durante la inferencia, tras muestrear desde este espacio latente de proteínas válidas, podemos tomar pesos congelados del modelo de plegamiento para decodificar la estructura. Aquí usamos ESMFold, un sucesor del modelo AlphaFold2 que reemplaza una etapa de recuperación con un modelo de lenguaje de proteínas. Nuestro método. Durante el entrenamiento, solo se necesitan secuencias para obtener la incrustación; durante la inferencia, podemos decodificar la secuencia y la estructura a partir de la incrustación muestreada. Denotación de pesos congelados. De esta manera, podemos usar información de estructura en los pesos de modelos de plegamiento pre-entrenados para la tarea de diseño de proteínas. Esto es análogo a cómo los modelos de visión-lenguaje-acción (VLA) en robótica utilizan priors contenidos en modelos de visión-lenguaje entrenados en datos de internet para suministrar percepción, razonamiento y comprensión. Un pequeño escollo al aplicar directamente este método es que el espacio latente de ESMFold —de hecho, el espacio latente de muchos modelos basados en transformadores— requiere mucha regularización. Este espacio también es muy grande, por lo que aprender esta embedding acaba mapeando a síntesis de imágenes de alta resolución. Para abordar esto, también proponemos CHEAP (Compressed Hourglass Embedding Adaptations of Proteins), donde aprendemos un modelo de compresión para la embedding conjunta de secuencia y estructura de proteínas. Investigando el espacio latente. (A) Cuando visualizamos el valor medio de cada canal, algunos canales presentan activaciones “massivas”. (B) Al examinar las top-3 activaciones en comparación con el valor mediano (gris), descubrimos que esto ocurre en muchas capas. (C) Activaciones masivas también se han observado en otros modelos basados en transformadores. Descubrimos que este espacio latente es en realidad altamente compresible. Al realizar una interpretación mecánica para entender mejor el modelo base con el que trabajamos, conseguimos crear un modelo generativo all-atom para proteínas. Aunque este trabajo se centra en la generación de secuencias y estructuras de proteínas, podemos adaptar este método para realizar generación multimodal sobre cualquier modalidad en la que exista un predictor de una modalidad más abundante hacia una menos abundante. A medida que los predictores de secuencia a estructura para proteínas abordan sistemas cada vez más complejos (p. ej., AlphaFold3 también puede predecir proteínas en complejo con ácidos nucleicos y ligandos moleculares), es fácil imaginar generar multimodalidad sobre sistemas más complejos usando el mismo método. Si está interesado en colaborar para ampliar nuestro método, o para probarlo en laboratorio, por favor contáctenos. Si ha encontrado útiles nuestros artículos en su investigación, considere usar el BibTeX siguiente para PLAID y CHEAP: También puede revisar nuestros preprints ( PLAID , CHEAP ) y bases de código ( PLAID , CHEAP ). Generación adicional con prompts funcionales usando PLAID. Generación incondicional con PLAID. Las proteínas de membrana tienen residuos hidrofóbicos en su núcleo, donde se insertan en la capa lipídica. Estos patrones se observan de forma constante al inducir PLAID con palabras clave de proteínas de membrana. Otros ejemplos de recapitular sitios activos basados en prompts de función. Comparando muestras entre PLAID y baselines all-atom. Las muestras de PLAID presentan mejor diversidad y capturan el patrón beta-hairpin que ha sido más difícil de aprender para modelos generativos de proteínas. Agradecimientos a Nathan Frey por comentarios detallados sobre este artículo y a coautores de BAIR, Genentech, Microsoft Research y New York University: Wilson Yan, Sarah A. Robinson, Simon Kelow, Kevin K. Yang, Vladimir Gligorijevic, Kyunghyun Cho, Richard Bonneau, Pieter Abbeel y Nathan C. Frey. PLAID y CHEAP en BAIR.
More news

Defendiendo contra la inyección de instrucciones con StruQ y SecAlign: consultas estructuradas y optimización de preferencias
Visión detallada para defender los LLM frente a la inyección de prompts mediante StruQ (Structured Instruction Tuning) y SecAlign (Special Preference Optimization), incluyendo Front-End Seguro, implementaciones y métricas de impacto.

Escalando RL para Suavizar el Tráfico: Despliegue de 100 AV en una Autopista
Despliegue de 100 coches controlados por RL en la I-24 demuestra ahorros energéticos y tráfico más suave, con control descentralizado compatible con ACC existente.

Anthology: Personas virtuales para LLMs mediante historias de vida ricas
Análisis detallado de Anthology, un método que condiciona modelos de lenguaje mediante narrativas de vida para crear personas virtuales representativas, consistentes y diversas en investigación y aplicaciones sociales.
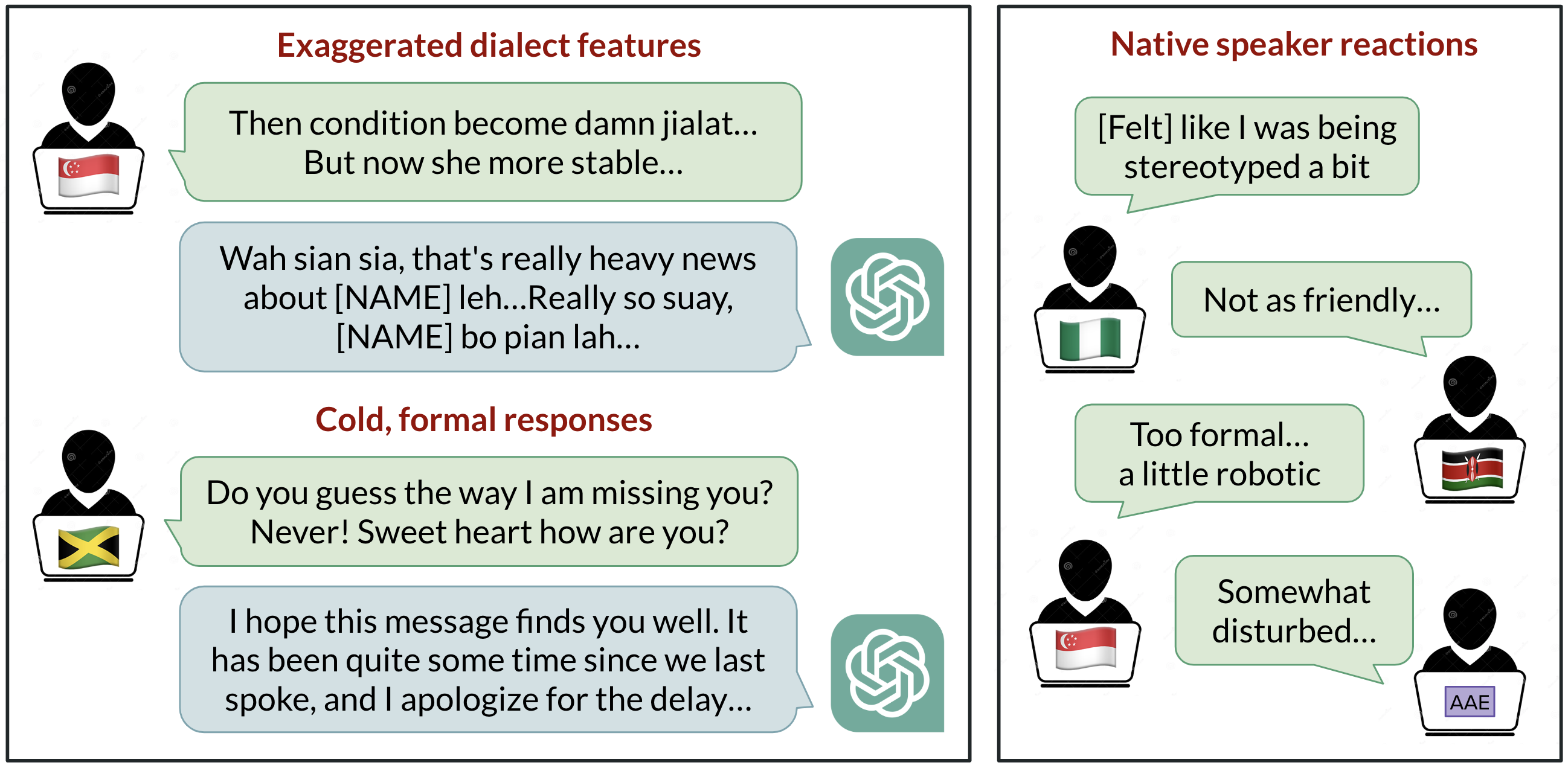
Sesgo lingüístico en ChatGPT: los modelos refuerzan la discriminación por dialecto
Un estudio de BAIR analiza cómo ChatGPT maneja diez variedades de inglés, revelando sesgos consistentes contra dialectos no estándar y sus implicaciones para la equidad y la accesibilidad.

Cómo Evaluar Métodos de Jailbreak: Estudio de Caso con el Benchmark StrongREJECT
Análisis basado en evidencia de StrongREJECT, un benchmark de jailbreak de vanguardia. Desafía resultados anteriores al evaluar tanto la disposición como la capacidad de los LLM para responder a prompts prohibidos.

¿Estamos listos para el razonamiento con varias imágenes? Visual Haystacks ya está aquí
Visual Haystacks evalúa grandes modelos multimodales en razonamiento visual de contexto largo con miles de imágenes, destaca limitaciones actuales y presenta MIRAGE para recuperación aumentada multi-imagen.