TinyAgent: Llamada de funciones en el borde para modelos pequeños
Sources: http://bair.berkeley.edu/blog/2024/05/29/tiny-agent, bair.berkeley.edu
TL;DR
- TinyAgent demuestra que los modelos de lenguaje pequeños (SLMs) pueden realizar llamadas de función precisas y orquestar herramientas para ejecución en el borde, sin depender de la inferencia en la nube.
- El enfoque utiliza un conjunto de datos de alta calidad, curado específicamente, y ajuste fino para enseñar al modelo a planificar y ejecutar llamadas de función en lugar de memorizar conocimientos generales.
- Un nuevo método Tool RAG (recuperación-augmented generation) mejora aún la eficiencia y el rendimiento, permitiendo respuestas en tiempo real en el borde.
- TinyAgent-1B funciona con Whisper-v3 en un MacBook M3 Pro, y el proyecto es de código abierto en el repositorio de GitHub de los autores.
- El conjunto de datos comprende 80.000 ejemplos de entrenamiento, más 1.000 de validación y 1.000 de pruebas, con un costo estimado de alrededor de 500 USD.
Contexto y antecedentes
Los grandes modelos de lenguaje han mostrado que las órdenes en lenguaje natural pueden activar herramientas para realizar tareas. Esto ha impulsado sistemas de agentes que encadenan APIs y scripts. Sin embargo, los modelos más grandes, a menudo alojados en la nube, presentan retos de privacidad, conectividad y latencia. Enviar datos a la nube puede plantear preocupaciones de privacidad y depender de cloud/Wi‑Fi puede ser problemático para implementaciones reales. La ejecución en borde ofrece IA privada y receptiva, pero los modelos grandes actuales son demasiado pesados para ejecutarse localmente. Parte del problema es que gran parte del tamaño del modelo se debe a la memorización de conocimiento general, lo cual no siempre es necesario para tareas especializadas. ¿Puede un modelo pequeño aprender a llamar funciones y orquestar tareas sin depender de una memoria amplia del mundo? Esta investigación propone que sí, al centrarse en la llamada de funciones como capacidad principal. TinyAgent El trabajo también se enfoca en sistemas semánticos donde el objetivo es entender la consulta del usuario y orquestar scripts y APIs predefinidos para lograr la tarea, en lugar de generar respuestas textuales tipo ChatGPT. TinyAgent
Novedades y detalles de implementación
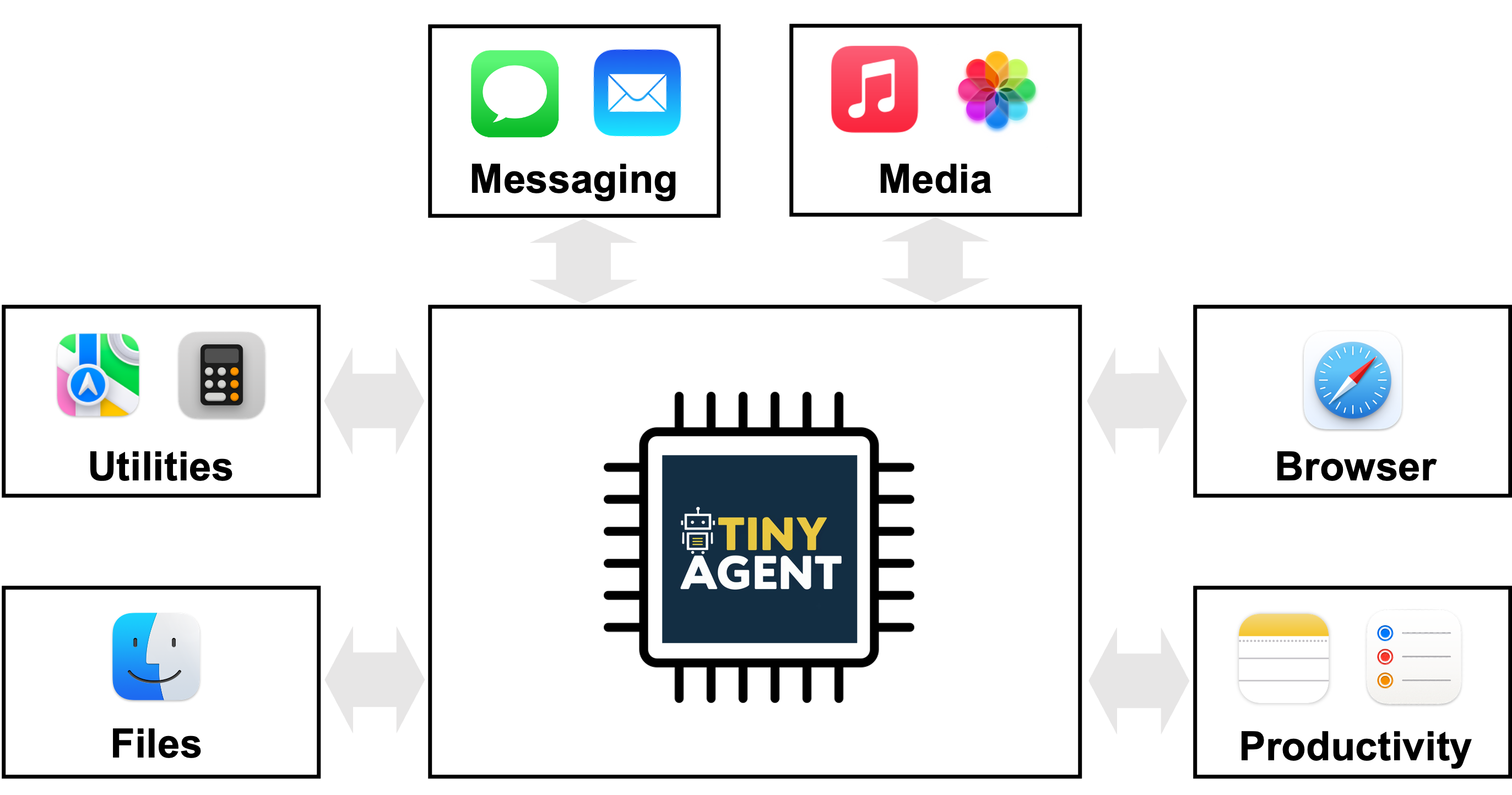
- TinyAgent-1B es un asistente capaz de interactuar con 16 funciones diferentes en macOS, que pueden manipular aplicaciones mediante scripts de Apple predefinidos y APIs. El modelo debe aprender a generar un plan de llamadas y a proporcionar los argumentos correctos, respetando las dependencias entre tareas. TinyAgent
- El estudio demuestra que modelos pequeños listos para usar (p. ej., TinyLLaMA-1.1B) tienen dificultades para generar planes correctos. La solución consiste en curar un conjunto de datos de alta calidad para llamadas de función y planificación y luego ajustar finamente el modelo, con el potencial de superar a modelos más grandes en esta tarea. TinyAgent
- La generación de datos utiliza un LLM poderoso (GPT-4-Turbo) para crear consultas de usuario realistas condicionadas a un conjunto de funciones, junto con el plan de llamadas y los argumentos. Se realizan comprobaciones de coherencia para garantizar que el plan sea factible y que los nombres de las funciones y los tipos de entrada sean correctos. El conjunto resultante es de 80,000 entrenamientos, 1,000 validaciones y 1,000 pruebas, con un costo de alrededor de US$500. TinyAgent
- Tool RAG es un método para mejorar la eficiencia y el rendimiento de las implementaciones en borde, permitiendo respuestas en tiempo real. TinyAgent
- Una demostración muestra TinyAgent-1B y Whisper-v3 funcionando localmente en un MacBook M3 Pro. El marco es de código abierto y está disponible en https://github.com/SqueezeAILab/TinyAgent. TinyAgent
Detalles técnicos o implementación
- Arquitectura: la idea central es que el LLM emita un plan de llamadas de funciones, enumerando qué funciones invocar, sus argumentos y las dependencias entre ellas. El plan se analiza y se ejecuta en el orden correcto según las dependencias. Las funciones y APIs son predefinidas en el dispositivo anfitrión; el modelo no necesita generar definiciones de función. TinyAgent
- Modelo y estrategia de datos: los modelos pequeños listos para usar muestran capacidades limitadas para generar planes de llamadas. Se aborda esto mediante una recopilación de datos centrada en la tarea y un ajuste fino para aprender a generar planes precisos. TinyAgent
- Generación y validación de datos: los datos se generan pidiendo a un LLM (GPT-4-Turbo) que cree consultas de usuario realistas condicionadas a un conjunto de funciones, junto con el plan de llamadas y argumentos. Se aplican chequeos de coherencia. El conjunto citado incluye 80,000 entrenamientos, 1,000 validaciones y 1,000 pruebas, con un costo de ~US$500. TinyAgent
- Tool RAG: método de recuperación-para-generación para mejorar la eficiencia en bordes. TinyAgent
- Demostración: TinyAgent-1B y Whisper-v3 funcionando localmente en un MacBook M3 Pro. El proyecto es de código abierto y disponible en https://github.com/SqueezeAILab/TinyAgent. TinyAgent
Tabla de dataset (divisiones)
| División | Tamaño |
|---|---|
| Entrenamiento | 80,000 |
| Validación | 1,000 |
| Pruebas | 1,000 |
- La métrica Graph Isomorphism Success Rate evalúa si el grafo de dependencias generado es isomorfo al grafo de referencia. TinyAgent
Puntos clave
- Los modelos de lenguaje pequeños pueden ser guiados para realizar llamadas de función complejas con datos específicos de tarea y ajuste fino.
- Planificación y orquestación basadas en tareas permiten que SLMs compitan con modelos más grandes en la tarea de llamada de función en entornos en borde.
- Un pipeline de datos sólido, verificaciones de coherencia y una evaluación basada en grafos son cruciales para agentes confiables en borde.
- Métodos como Tool RAG pueden mejorar la eficiencia y permitir respuestas en tiempo real en el dispositivo.
- El proyecto TinyAgent es de código abierto y pensado para despliegues prácticos en hardware de consumo. TinyAgent
FAQ
Referencias
More news

Agilizar el acceso a cambios de contenido ISO-rating con Verisk Rating Insights y Amazon Bedrock
Verisk Rating Insights, impulsado por Amazon Bedrock, LLM y RAG, ofrece una interfaz conversacional para acceder a cambios ERC ISO, reduciendo descargas manuales y acelerando información precisa.

Automatizar pipelines RAG avanzados con Amazon SageMaker AI
Optimiza la experimentación a la producción para Retrieval Augmented Generation (RAG) con SageMaker AI, MLflow y Pipelines, para flujos reproducibles, escalables y con gobernanza.

Desbloquea insights del modelo con soporte de probabilidades de registro para la importación de modelos personalizados de Amazon Bedrock
Explica datos de confianza por token para modelos importados en Bedrock mediante probabilidades de log, cómo habilitarlos y usos prácticos.

Despliega Inferencia de IA escalable con NVIDIA NIM Operator 3.0.0
NVIDIA NIM Operator 3.0.0 amplía la inferencia de IA escalable en Kubernetes, habilitando despliegues multi-LLM y multi-nodo, integración con KServe y soporte DRA en modo tecnología, con colaboración de Red Hat y NeMo Guardrails.

Desplegar bases de conocimiento de Amazon Bedrock con Terraform para aplicaciones de IA generativa basadas en RAG
Automatiza el despliegue de bases de conocimiento Bedrock y las conexiones a fuentes de datos para flujos RAG mediante un template Terraform IaC, brindando configuraciones rápidas y reproducibles en producción.
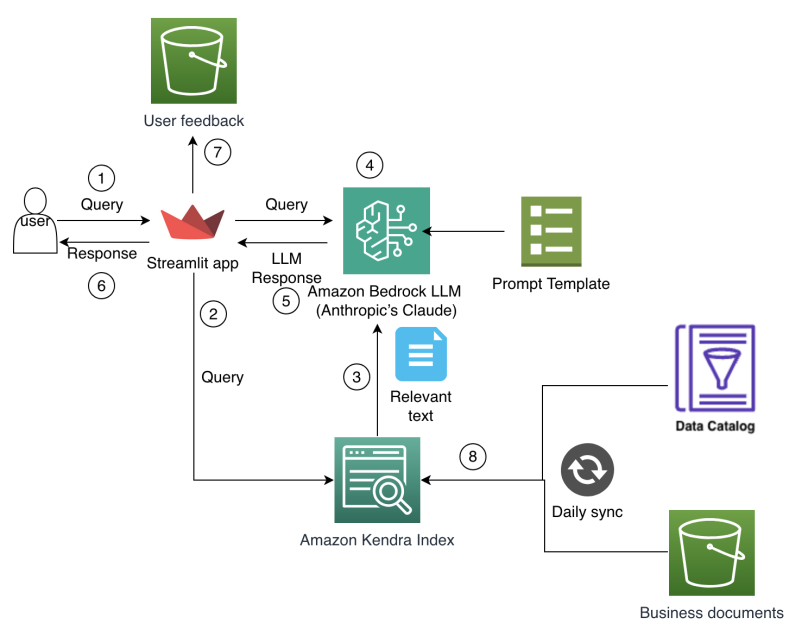
Cómo Amazon Finance construyó un asistente de IA usando Amazon Bedrock y Amazon Kendra para apoyar a los analistas en el descubrimiento de datos y conocimientos comerciales
Amazon Finance describe un asistente de IA que combina Bedrock y Kendra para acelerar el descubrimiento de datos, preservar el conocimiento institucional y entregar insights financieros precisos a escala.