Modelando Imágenes Extremadamente Grandes con xT
Sources: http://bair.berkeley.edu/blog/2024/03/21/xt, bair.berkeley.edu
TL;DR
- xT es un marco para modelar imágenes extremadamente grandes de extremo a extremo en GPUs modernas, usando tokenización anidada y dos codificadores coordinados: codificadores de región para detalle local y codificadores de contexto para integración global.
- Aborda desafíos de memoria y escala evitando muestreo hacia abajo o recorte, procesando imágenes por partes con contexto jerárquico.
- La arquitectura admite codificadores de región a partir de backbones de vanguardia (p. ej., Swin, Hiera, ConvNeXt) y codificadores de contexto que manejan dependencias a largo alcance (p. ej., Transformer-XL y variantes como Hyper y Mamba).
- En experiments, xT maneja imágenes de hasta 29,000 × 25,000 píxeles en GPUs A100 de 40 GB, mientras que baselines comparables agotan la memoria a aproximadamente 2,800 × 2,800 píxeles. Esto permite mayor precisión en tareas downstream con menos parámetros y menor memoria por región.
- El enfoque se demuestra en tareas diversas (iNaturalist 2018, xView3-SAR, MS-COCO) y busca abrir aplicaciones en monitoreo climático, salud y más. Para detalles completos, la página del proyecto ofrece código y pesos, y la entrada del blog describe las ideas clave detrás de xT. fuente
Contexto y antecedentes
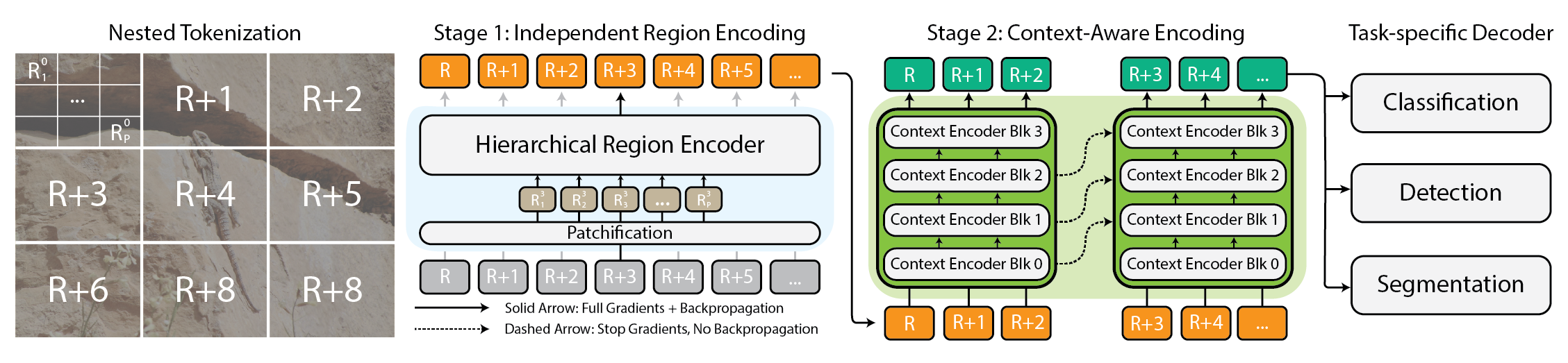
Las imágenes de gran tamaño ya no son raras. Las cámaras que llevamos y las que orbitan nuestro planeta capturan datos tan grandes y detallados que los modelos y el hardware actuales llegan a sus límites, principalmente por el crecimiento de memoria que es aproximadamente cuadrático respecto al tamaño de la imagen. Una estrategia común, pero subóptima, es reducir la resolución o recortar partes de la imagen, lo que conlleva la pérdida de información y contexto crítico. El desafío central es equilibrar la necesidad de ver tanto el bosque como los árboles. Si la imagen se procesa entera, la memoria se dispara; si se procesa solo una región, se pierden relaciones a larga distancia importantes. xT propone tokenización anidada: dividir la imagen en regiones, cada una puede subdividirse, para luego aplicar encoders a cada región y, finalmente, combinar todo con un encoder de contexto para obtener una visión global coherente. fuente La idea de tokenización anidada crea una jerarquía de tokens en varias escalas, permitiendo modelar tanto detalles locales como la estructura global. Implementar una jerarquía facilita manejar imágenes de gran tamaño sin sacrificar la fidelidad, al tiempo que se conserva una visión global. fuente
Lo nuevo
xT presenta una arquitectura basada en tres conceptos: tokenización anidada, codificadores de región y codificadores de contexto. Primero, la tokenización anidada divide la imagen en regiones que pueden subdividirse, y luego se parchean para ser procesadas por el region encoder. Cada region encoder funciona como un experto local, generando representaciones detalladas. Dado que cada región se procesa de forma aislada, no hay intercambio de información a nivel de imagen durante el procesamiento regional. El region encoder puede ser cualquier backbone de visión de vanguardia (Swin, Hiera, ConvNeXt). Luego, el codificador de contexto toma las representaciones de las regiones y las une para asegurar que las ideas de una región se consideren en el contexto de las demás. Generalmente, el codificador de contexto es un modelo de secuencia larga. Se experimenta con Transformer-XL (y una variante llamada Hyper) y Mamba, aunque también podrían usarse Longformer y otros avances. El truco de xT es la forma en que estos componentes se combinan para mantener la fidelidad de los detalles locales al tiempo que se integra el contexto global, haciendo viable el procesamiento end-to-end de imágenes masivas en GPUs modernas. fuente Se evalúa xT en tareas desafiantes que abarcan desde baselines consolidados hasta tareas de grandes imágenes: iNaturalist 2018 para clasificación de especies de gran detalle, xView3-SAR para segmentación dependiente del contexto y MS-COCO para detección. En todos los casos, las configuraciones basadas en xT logran mayor precisión con menos parámetros y menor memoria por región que los baselines. fuente Una capacidad destacada es la de modelar imágenes tan grandes como 29 000 × 25 000 píxeles en GPUs 40 GB A100, mientras que baselines comparables llegan a agotar la memoria a 2 800 × 2 800 píxeles. Esta diferencia resalta el potencial del enfoque de tokenización anidada y la separación entre procesamiento regional e integración del contexto para datos de alta resolución. El objetivo es abrir la puerta a modelos que entiendan la historia completa de una imagen sin comprometer la claridad o el alcance. fuente
Por qué importa (impacto para desarrolladores/empresas)
El impacto práctico de xT se ve en dominios donde el tamaño y el detalle de las imágenes son críticos. En monitoreo ambiental, es posible observar cambios a gran escala mientras se examinan áreas específicas para entender efectos locales. En salud, los clínicos podrían detectar patrones sutiles en imágenes médicas de alta resolución sin perder la visión global. Para desarrolladores, xT ofrece un marco para entrenar e inferir con imágenes muy grandes en hardware moderno, manteniendo la memoria bajo control. fuente Desde la perspectiva de la ingeniería, la combinación de codificadores de región con modelos de contexto de secuencia larga puede simplificar flujos de trabajo y facilitar la experimentación con diferentes backbones regionales y modelos de contexto, así como ajustar cómo se generan y conectan los tokens. En resumen, con xT se puede manejar imágenes muy grandes sin comprometer memoria ni rendimiento, abriendo paso a conjuntos de datos más grandes y aplicaciones más complejas. fuente
Detalles técnicos o Implementación
En el corazón de xT está la tokenización anidada, que divide la imagen en regiones y sub-regiones, y luego parchea estas regiones antes de enviarlas al region encoder. Cada region encoder funciona como un experto local, produciendo representaciones detalladas para cada región. Dado que cada región se procesa aisladamente, no hay intercambio inmediato de información entre regiones a nivel global durante el procesamiento regional. El encoder de contexto toma las representaciones regionales y las integra para formar una comprensión coherente de la imagen, incorporando señales de largo alcance. En las pruebas, Transformer-XL y variantes como Hyper, y Mamba se utilizan como modelos de contexto. El sistema está diseñado para ejecutarse de forma end-to-end en GPUs modernas, lo que facilita el entrenamiento y la inferencia sobre imágenes de gran tamaño sin reducir la resolución. Para los encodeurs de región, xT admite Swin, Hiera y ConvNeXt; para el contexto, se exploran modelos de secuencia larga como Transformer-XL, Hyper y Mamba. El objetivo es conservar los detalles locales mientras se integra el contexto global, permitiendo modelar imágenes de gran escala con una memoria razonable. fuente
Conclusiones clave
- La tokenización anidada permite descomponer imágenes extremadamente grandes en regiones y sub-regiones de forma escalable.
- Los encodeurs de región actúan como expertos locales, mientras que los encodeurs de contexto integran información entre regiones para mantener la coherencia global.
- Diversas opciones de backbones pueden servir como encodeurs de región (Swin, Hiera, ConvNeXt) y modelos de contexto de secuencia larga (Transformer-XL, Hyper, Mamba) ofrecen integración de contexto robusta.
- Los resultados muestran mayor precisión con menos parámetros y menor memoria por región frente a baselines, haciendo viable el uso en imágenes de alta resolución.
- La capacidad de modelar imágenes hasta 29 000 × 25 000 en GPUs 40 GB A100 demuestra el potencial para aplicaciones avanzadas en datos de alta resolución. fuente
Preguntas Frecuentes
Referencias
More news

NVIDIA HGX B200 reduce la intensidad de las emisiones de carbono incorporado
El HGX B200 de NVIDIA reduce la intensidad de carbono incorporado en un 24% frente al HGX H100, al tiempo que ofrece mayor rendimiento de IA y eficiencia energética. Este artículo resume los datos PCF y las novedades de hardware.

Cómo reducir cuellos de botella KV Cache con NVIDIA Dynamo
NVIDIA Dynamo offloads KV Cache desde la memoria de la GPU hacia almacenamiento económico, habilitando contextos más largos, mayor concurrencia y costos de inferencia más bajos para grandes modelos y cargas de IA generativa.

Microsoft transforma el sitio de Foxconn en el data center Fairwater AI, descrito como el más poderoso del mundo
Microsoft anuncia planes para un data center Fairwater AI de 1,2 millones de pies cuadrados en Wisconsin, con cientos de miles de GPU Nvidia GB200. El proyecto de 3.3 mil millones de dólares promete un entrenamiento de IA sin precedentes.

Manual de los Grandmasters de Kaggle: 7 Técnicas de Modelado para Datos Tabulares
Un análisis detallado de siete técnicas probadas por los Grandmasters de Kaggle para resolver rápidamente conjuntos de datos tabulares mediante aceleración por GPU, desde baselines variados hasta ensamblaje y pseudo-etiquetado.

NVIDIA RAPIDS 25.08 Agrega Nuevo profiler para cuML, Mejoras en el motor GPU de Polars y Soporte Ampliado de Algoritmos
RAPIDS 25.08 introduce perfiles de nivel de función y de línea para cuml.accel, el ejecutor de streaming por defecto del motor Polars GPU, soporte ampliado de tipos y cadenas, Spectral Embedding en cuML y aceleraciones de cero código para varios estimadores.

Construir Flujos de Trabajo Agenticos con GPT OSS de OpenAI en SageMaker AI y Bedrock AgentCore
Visión general de extremo a extremo para implementar modelos GPT OSS de OpenAI en SageMaker AI y Bedrock AgentCore, impulsando un analizador de acciones multiagente con LangGraph, con cuantización MXFP4 de 4 bits y orquestación serverless.