¿Los embeddings de texto codifican perfectamente el texto? vec2text demuestra una inversión casi perfecta
Sources: https://thegradient.pub/text-embedding-inversion, thegradient.pub
TL;DR
- Los embeddings de texto pueden invertirse para recuperar el texto con alta fidelidad en muchos escenarios, lo que plantea consideraciones de seguridad para el almacenamiento de embeddings.
- Un enfoque de optimización aprendida, vec2text, puede transformar embeddings de vuelta en texto con precisión creciente mediante refinamiento iterativo.
- En experimentos con 32 tokens, una pasada de corrección eleva BLEU de ~30 a ~50; con unas 50 etapas, alrededor del 92% de las secuencias de 32 tokens se recuperan exactamente, y BLEU alcanza ~97.
- Los resultados muestran que los vectores de embedding contienen información sobre el texto de entrada, desafiando la idea de que los embeddings son un formato de almacenamiento privado perfecto.
- Estos hallazgos incentivan a revisar las prácticas de seguridad y privacidad alrededor de los datos de embedding en las bases de datos vectoriales.
Contexto y antecedentes
La Recuperación Aumentada por Generación (RAG) se ha convertido en un patrón común para construir sistemas de IA que responden preguntas consultando un conjunto de documentos. En este marco, los embeddings —representaciones vectoriales producidas por modelos de embedding— determinan la relevancia de los documentos y guían la recuperación en bases de vectores. La premisa es que textos semánticamente similares se mapean a vectores similares, permitiendo búsquedas eficientes en grandes colecciones de documentos The Gradient. En la práctica, lo que se almacena en una base vectorial son vectores de embedding, no el texto en sí. La base se llena de filas de números que parecen datos al azar, representando texto, pero nunca muestran el texto. Aunque el texto original está protegido por políticas de privacidad, si un atacante accede a los embeddings, ¿podría recuperar el texto subyacente? Esta es la cuestión central tratada en el artículo Text Embeddings Reveal As Much as Text (EMNLP 2023). ¿Puede el texto de entrada recuperarse a partir de embeddings de salida? Las respuestas y las implicaciones dependen de cómo los embeddings capturan y comprimen la información de entrada The Gradient. De forma general, los embeddings de texto son salidas de redes neuronales que transforman el texto de entrada a través de vectores de tokens y operaciones no lineales. Un principio conocido en teoría de la información, la desigualdad de procesamiento de datos, establece que las funciones no crean información: solo pueden conservar o reducir lo recibido. En la práctica, las capas no lineales utilizadas en los encoders modernos (por ejemplo, ReLU) tienden a la pérdida de información a lo largo de la red The Gradient. En dominios relacionados, especialmente la visión por computadora, representaciones profundas pueden invertirse para reconstruir las entradas originales con fidelidad variable. Investigaciones muestran que imágenes pueden recuperarse a partir de salidas de redes CNN, y que la inversión puede lograr fidelidad significativa. Estos hallazgos han inspirado la exploración de si la inversión también es posible para embeddings de texto The Gradient. Un problema ilustrativo ayuda a entender: si restringimos las entradas a 32 tokens y las mapeamos a vectores de 768 dimensiones, el embedding ocupa unos 24 576 bits (32 tokens × 768 dimensiones) a una precisión de 32 bits — aproximadamente 3 kilobytes. ¿Podríamos reconstruir exactamente el texto a partir de este embedding? El estudio define una métrica de “concordancia exacta” y una métrica suave basada en BLEU para medir la similitud entre el texto generado y el real. Las primeras aproximaciones de inversión muestran que es bastante difícil revertir una salida de modelo en una pasada, lo que motiva enfoques más sofisticados The Gradient.
¿Qué hay de nuevo?
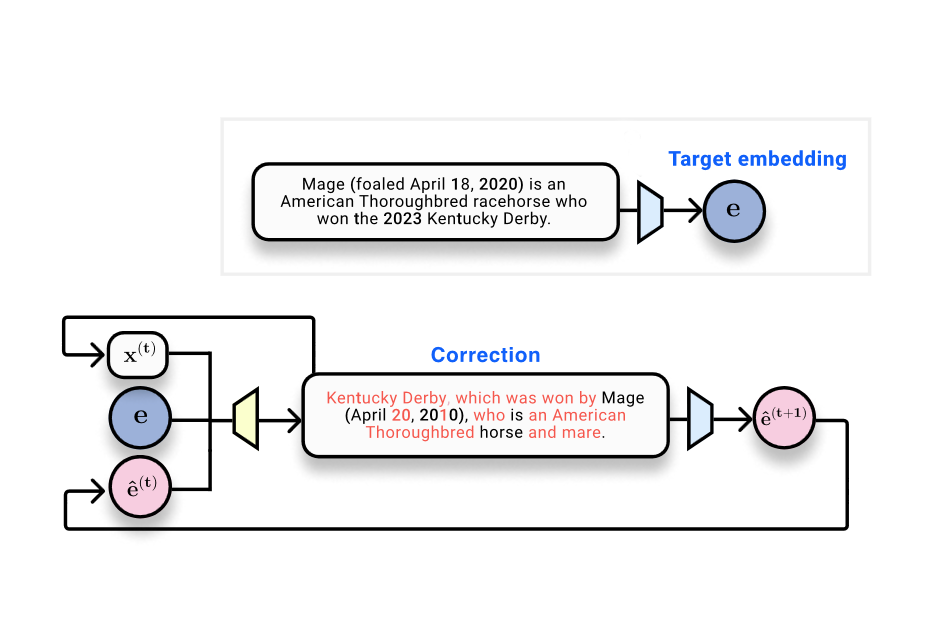
El aporte central es vec2text, un método que plantea la inversión de embeddings como un problema de optimización aprendida, en el que un embedding objetivo, una hipótesis de texto y la posición de la hipótesis en el espacio de embedding guían la predicción del texto verdadero. El sistema se describe como una especie de optimización aprendida que realiza pasos en el espacio de embedding mediante secuencias discretas de texto. Un hallazgo clave es que una sola pasada de corrección eleva el BLEU de ~30 a ~50. La metodología también se beneficia de la posibilidad de consultas recursivas: al repetir el proceso, re-embedir las hipótesis y alimentarlas de vuelta, se logra un refinamiento adicional. Con aproximadamente 50 pasos y algunos trucos, la recuperación exacta de 92% de secuencias de 32 tokens es alcanzable, con un BLEU cercano a 97, lo que indica una reconstrucción casi perfecta de la oración original en la mayoría de los casos The Gradient. El estudio también señala que las modernas representaciones de embedding retienen una cantidad fija de información y que existen límites prácticos para la cantidad de detalle que puede almacenarse en un único embedding. Aunque el experimento se centró en 32 tokens, los autores reconocen que algunos modelos de embedding pueden soportar textos más largos, dejando abierta la frontera exacta de capacidad de almacenamiento de información en estados de embedding. En resumen, los resultados muestran una vulnerabilidad práctica importante para consideraciones de seguridad y privacidad en el manejo de embeddings The Gradient. Además, estos resultados se alinean con trabajos en visión sobre la posibilidad de reconstruir entradas a partir de representaciones de alto nivel, reforzando la idea de que los embeddings no son intrínsecamente privados cuando se exponen a procesos de recuperación y generación con acceso a los embeddings de usuarios The Gradient.
¿Por qué es importante (impacto para desarrolladores/empresas)
Para desarrolladores y empresas que usan bases de vectores en pipelines RAG, estos resultados señalan un riesgo: los embeddings pueden contener información sensible y ser invertidos para revelar el texto original. Si los vectores de embedding se exponen o se comparten con terceros, podría haber filtración de datos. La aproximación vec2text quantifica una capacidad de inversión que debe considerarse al diseñar políticas de seguridad y privacidad para datos de embedding en entornos corporativos The Gradient. Esto no niega el valor de los embeddings: facilitan recuperación escalable y eficiente, pero requieren controles de seguridad adecuados y prácticas de manejo de datos para minimizar la exposición de información sensible cuando se usan en servicios gestionados por terceros The Gradient.
Detalles técnicos o Implementación
El estudio propone un pipeline en dos etapas. Primero, se entrena un transformer base que toma un embedding y genera el texto correspondiente. Este enfoque inicial produce un BLEU de aproximadamente 30 y una tasa de concordancia exacta cercana a cero, lo que ilustra la dificultad de una inversión directa en una sola pasada. En segundo lugar, se introduce un corrector aprendido que opera en el espacio de embedding para refinar iterativamente la hipótesis y acercarla al ground-truth. En esencia, es una forma de optimización aprendida que avanza a través de actualizaciones discretas en el espacio de texto guiadas por el embedding objetivo The Gradient. Un hallazgo práctico es la alta similitud de coseno entre el embedding del texto real y el embedding de la hipótesis generada después de re-embedir la hipótesis. Este hallazgo justifica el bucle de refinamiento iterativo: si la hipótesis actual ya se aproxima al embedding objetivo, las iteraciones posteriores pueden ajustar el texto para coincidir mejor con el ground-truth. vec2text permite consultar al modelo de forma recursiva, generando hipótesis, re-embeddiéndolas y alimentándolas de nuevo para continuar refinando The Gradient. Con vec2text, una única pasada de corrección elevó el BLEU de ~30 a ~50. La repetición del proceso de corrección con aproximadamente 50 pasos, y aplicando algunas técnicas, permitió recuperar 92% de secuencias de 32 tokens exactamente y lograr un BLEU de aproximadamente 97, lo que indica una reconstrucción casi perfecta en el conjunto de pruebas (para 32 tokens y embeddings de 768 dimensiones) The Gradient. El estudio subraya también que el embedding contiene una cantidad fija de información y que hay límites prácticos a la longitud de entrada que puede codificarse de forma fiable en un único embedding. Aunque los experimentos se centraron en 32 tokens, los autores reconocen que otros modelos de embedding pueden apoyar longitudes mayores, lo que resalta la importancia de entender las capacidades de cada embedding en contextos reales. En resumen, estos resultados revelan una vulnerabilidad práctica y enfatizan la necesidad de considerar la seguridad y la privacidad en sistemas que usan embeddings The Gradient.
Conclusiones clave
- Los embeddings de texto pueden contener información suficiente para reconstruir el texto de entrada bajo ciertas técnicas de inversión.
- vec2text propone una optimización aprendida que refina iterativamente las hipótesis de texto para acercarlas al texto original.
- En un escenario de 32 tokens, BLEU puede aumentar de ~30 a ~50 tras la corrección, y con ~50 pasos se recupera aproximadamente el 92% de las secuencias exactas con BLEU ~97.
- La posibilidad de invertir embeddings plantea preguntas de privacidad y seguridad para las bases de datos vectoriales, lo que requiere prácticas sólidas de protección de datos.
- Los hallazgos se alinean con trabajos en visión que muestran que las representaciones de alto nivel pueden retener información recuperable de la entrada original, desafiando la noción de que los embeddings son intrínsecamente privados.
FAQ
-
¿Se puede recuperar perfectamente el texto a partir de embeddings?
En este marco, el match exacto en una sola pasada es casi nulo, pero la inversión sustancial es posible y la recuperación casi perfecta puede lograrse mediante refinamiento iterativo (BLEU cercano a 97). Consulte los resultados del método vec2text para más detalles.
-
¿Por qué los embeddings permiten recuperación si la desigualdad de procesamiento de datos dice que no añaden información?
Los embeddings pueden conservar información sobre la entrada de formas que permiten reconstrucción con estrategias de optimización específicas, especialmente con retroalimentación de re-embedding y pasos de refinamiento.
-
¿Cuáles son las implicaciones para la privacidad de las bases de vectores?
Si los embeddings pueden invertirse para recuperar texto, exponerlos o compartirlos con terceros puede conllevar filtración de datos sensibles. El estudio subraya la necesidad de considerar la seguridad y las políticas de manejo de datos de embedding en entornos empresariales.
-
¿Qué es vec2text y qué puede hacer?
vec2text trata la inversión de embeddings como una optimización aprendida que usa un embedding objetivo, una hipótesis de texto y su posición en el espacio para predecir una secuencia de texto más cercana al ground-truth. Los resultados muestran mejoras significativas y la posibilidad de refinamiento recursivo.
-
¿Cuáles son los límites de estos hallazgos?
Los resultados se reportan para un escenario específico (32 tokens, embeddings de 768 dimensiones). Otros parámetros o configuraciones podrían producir resultados diferentes y distintas implicaciones para la privacidad.
Referencias
More news

Agilizar el acceso a cambios de contenido ISO-rating con Verisk Rating Insights y Amazon Bedrock
Verisk Rating Insights, impulsado por Amazon Bedrock, LLM y RAG, ofrece una interfaz conversacional para acceder a cambios ERC ISO, reduciendo descargas manuales y acelerando información precisa.

Automatizar pipelines RAG avanzados con Amazon SageMaker AI
Optimiza la experimentación a la producción para Retrieval Augmented Generation (RAG) con SageMaker AI, MLflow y Pipelines, para flujos reproducibles, escalables y con gobernanza.

Desbloquea insights del modelo con soporte de probabilidades de registro para la importación de modelos personalizados de Amazon Bedrock
Explica datos de confianza por token para modelos importados en Bedrock mediante probabilidades de log, cómo habilitarlos y usos prácticos.

Despliega Inferencia de IA escalable con NVIDIA NIM Operator 3.0.0
NVIDIA NIM Operator 3.0.0 amplía la inferencia de IA escalable en Kubernetes, habilitando despliegues multi-LLM y multi-nodo, integración con KServe y soporte DRA en modo tecnología, con colaboración de Red Hat y NeMo Guardrails.

Desplegar bases de conocimiento de Amazon Bedrock con Terraform para aplicaciones de IA generativa basadas en RAG
Automatiza el despliegue de bases de conocimiento Bedrock y las conexiones a fuentes de datos para flujos RAG mediante un template Terraform IaC, brindando configuraciones rápidas y reproducibles en producción.
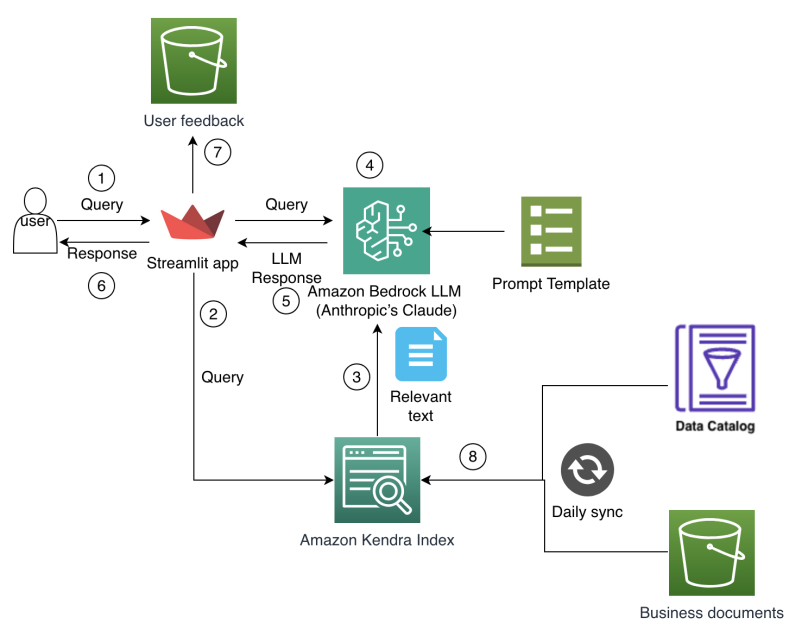
Cómo Amazon Finance construyó un asistente de IA usando Amazon Bedrock y Amazon Kendra para apoyar a los analistas en el descubrimiento de datos y conocimientos comerciales
Amazon Finance describe un asistente de IA que combina Bedrock y Kendra para acelerar el descubrimiento de datos, preservar el conocimiento institucional y entregar insights financieros precisos a escala.