Schedule topology-aware workloads using Amazon SageMaker HyperPod task governance
Sources: https://aws.amazon.com/blogs/machine-learning/schedule-topology-aware-workloads-using-amazon-sagemaker-hyperpod-task-governance, https://aws.amazon.com/blogs/machine-learning/schedule-topology-aware-workloads-using-amazon-sagemaker-hyperpod-task-governance/, AWS ML Blog
TL;DR
- AWS announced topology-aware scheduling as a new capability of Amazon SageMaker HyperPod task governance to optimize training efficiency and network latency on Amazon EKS clusters.
- The approach leverages EC2 topology information to place interdependent training tasks within the same network nodes and layers, reducing network hops and latency.
- There are two primary submission methods for topology-aware workloads: annotating Kubernetes manifests with a topology annotation and using the SageMaker HyperPod CLI with topology-related flags.
- The workflow includes confirming topology information, identifying nodes sharing network layers, and submitting topology-aware training tasks to achieve greater visibility and control over placement.
- The post provides practical steps, an example topology overview, and invites feedback from users.
Context and background
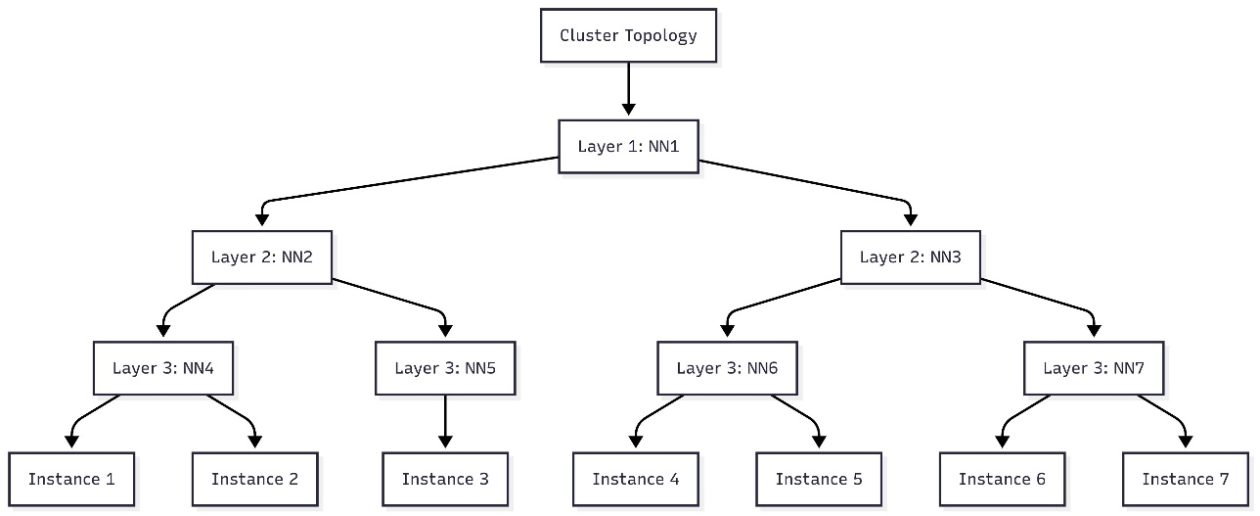
Generative AI workloads often require extensive cross-node communication across EC2 instances. In these environments, network latency is influenced by how instances are physically and logically placed within a data center’s hierarchical topology. AWS describes data centers as comprising nested organizational units such as network nodes and node sets, with multiple instances per node and multiple nodes per set. Instances that share closer network nodes tend to have faster processing times due to fewer network hops. To optimize the placement of AI workloads in SageMaker HyperPod clusters, practitioners can incorporate EC2 topology information when submitting jobs. An EC2 instance’s topology is described by a set of nodes, with one node in each layer of the network. Data centers organize topology into layers, and the availability of shared layers informs proximity and communication efficiency. Network topology labels enable topology-aware scheduling that prioritizes workloads with optimized network communication, thereby improving task efficiency and resource utilization. In this context, SageMaker HyperPod task governance extends governance capabilities to accelerated compute allocation and priority policies across teams and projects on EKS clusters. This governance helps administrators align resource allocation with organizational priorities, enabling faster AI innovation and reduced time-to-market by minimizing the need to coordinate resource provisioning and replanning tasks. For readers seeking deeper guidance, AWS points to Best practices for Amazon SageMaker HyperPod task governance for more information.
What’s new
This post introduces topology-aware scheduling as a capability within SageMaker HyperPod task governance. The goal is to optimize training efficiency and network throughput/latency by considering the physical and logical arrangement of resources in the cluster. Key points:
- Topology-aware scheduling uses EC2 topology information to inform job placement, with instances in the same network node layers sharing faster interconnects.
- Administrators can govern accelerated compute allocation and enforce task priority policies to improve resource utilization.
- Data scientists interact with SageMaker HyperPod clusters to ensure capacity and permission alignment when working with GPU-backed resources.
- The approach supports two primary submission methods and a third alternative workflow, providing flexibility for different teams and workflows.
Two primary submission methods (plus an alternative workflow)
- Kubernetes manifest annotation: modify your existing Kubernetes manifest to include a topology annotation such as kueue.x-k8s.io/podset-required-topology to schedule pods that share the same layer 3 network node. To verify pod placement, you can inspect node allocations with:
- kubectl get pods -n hyperpod-ns-team-a -o wide
- SageMaker HyperPod CLI: submit topology-aware jobs via the HyperPod CLI using either —preferred-topology or —required-topology in your create job command. An example is provided to illustrate starting a topology-aware MNIST training job with a placeholder for the AWS account ID (XXXXXXXXXXXX). The post also notes practical considerations for environments where new resources were deployed and points readers to the Clean Up section in the SageMaker HyperPod EKS workshop to avoid unintended charges. It also emphasizes that LLM training involves significant pod-to-pod communication and that topology-aware scheduling improves throughput and latency for these workloads.
How to get started
To begin, you should:
- Confirm topology information for all nodes in your cluster.
- Run a script to identify which instances are on the same network nodes across layers 1–3.
- Schedule topology-aware training tasks on your cluster using either submission method. This workflow aims to provide greater visibility and control over the placement of training instances, which can translate into more predictable performance for distributed AI workloads. The article notes that network topology labels help in achieving these benefits and points readers to inline examples and visualizations (via Mermaid.js.org) to aid topology understanding.
Why it matters (impact for developers/enterprises)
Topology-aware scheduling addresses a core performance factor for distributed AI training: inter-node communication. For generative AI and other large-scale training tasks, reducing network hops between GPUs across nodes can meaningfully decrease training time and inference latency. By leveraging EC2 topology data within SageMaker HyperPod task governance, organizations can:
- Improve resource utilization by aligning compute placement with network proximity.
- Simplify governance of accelerated compute allocations across teams and projects.
- Accelerate time-to-market for AI innovations by reducing the coordination overhead associated with resource planning and task replanning.
- Provide data scientists with clearer visibility into where their training jobs will run, enabling more informed experimentation and optimization. These capabilities are particularly valuable for teams deploying large distributed models that require frequent cross-node synchronization and data exchange. The governance model aims to strike a balance between performance (through topology-aware placement) and administrative control (through task priority policies and resource governance).
Technical details or Implementation
Prerequisites and setup:
- Start by showing node topology labels in your cluster. The topology label you’ll commonly encounter is topology.k8s.aws/network-node-layer-3, with sample outputs such as topology.k8s.aws/network-node-layer-3: nn-33333example. This reveals how instances are organized across network layers.
- Use a script to identify which nodes share layers 1, 2, and 3 in your cluster. The output can be used to construct a flow diagram (for example, in Mermaid.js.org) to visualize cluster topology.
- AWS provides two practical submission paths for topology-aware workloads:
- Kubernetes manifest annotation: add the kueue.x-k8s.io/podset-required-topology annotation to your Pod or Job manifests so that pods sharing the same layer 3 network node are scheduled together.
- SageMaker HyperPod CLI: use the HyperPod CLI with either —preferred-topology or —required-topology when creating a job. This approach enables programmatic, topology-informed scheduling within SageMaker HyperPod governance.
- Verifying placement: after launching pods, you can verify node assignments with a command such as kubectl get pods -n hyperpod-ns-team-a -o wide, which shows the node IDs for each pod.
- The article includes an example command to start a topology-aware MNIST training job via the HyperPod CLI, where you replace XXXXXXXXXXXX with your AWS account ID. While the exact command is not reproduced here, the example demonstrates the CLI workflow. Ongoing considerations:
- If you deployed new resources as part of adopting topology-aware scheduling, consider following the Clean Up guidance in the SageMaker HyperPod EKS workshop to avoid unintended charges.
- The approach is particularly relevant for large language model (LLM) training, where pod-to-pod data exchange is frequent and sensitive to network topology.
- AWS highlights that topology-aware scheduling can offer higher visibility and control over training placements, which can translate into improved efficiency and performance for AI workloads.
Practical example and visualization
The workflow includes generating a flow chart that shows how nodes relate across layers 1–3. You can visualize this topology in tools such as Mermaid.js.org to plan pod placement before submitting topology-aware tasks. The example cluster discussed in the article demonstrates how a seven-instance cluster maps to the hierarchical topology and informs decisions about shared network layers.
Key considerations when implementing
- Decide between the manifest-based approach and the CLI-based approach based on your workflow and automation preferences.
- Ensure your team has the necessary permissions to interact with the SageMaker HyperPod cluster and to annotate Kubernetes resources.
- Plan for ongoing monitoring of topology-aware placements and performance metrics to validate gains in throughput and latency.
Key takeaways
- SageMaker HyperPod task governance now supports topology-aware scheduling to improve AI training efficiency and network latency.
- You can implement topology-aware scheduling via Kubernetes manifest annotations or the SageMaker HyperPod CLI, offering flexibility for different teams.
- EC2 topology information is leveraged to place related pods within the same network layers, reducing inter-node communication costs.
- A structured workflow includes verifying topology, identifying shared network layers, and submitting topology-aware tasks to achieve better resource utilization.
- The approach is particularly beneficial for distributed training workloads such as LLMs, where pod-to-pod communication dominates runtime.
FAQ
-
What is SageMaker HyperPod task governance topology-aware scheduling?
It is a capability to optimize training efficiency and network latency by scheduling workloads with awareness of the underlying EC2 topology and network layers within SageMaker HyperPod governance.
-
How can I submit topology-aware tasks?
You can either annotate your Kubernetes manifests with a topology-aware annotation (kueue.x-k8s.io/podset-required-topology) or use the SageMaker HyperPod CLI with --preferred-topology or --required-topology when creating a job.
-
What prerequisites do I need to start?
You should confirm topology information for all cluster nodes, run a script to identify shared network layers, and verify pod placements with kubectl commands. You may also review the example MNIST/topology scenario provided in the article.
-
Where can I find more information?
See the AWS blog post linked in References, and explore the Mermaid visualization reference and the Kubernetes pod topology annotation (kueue.x-k8s.io/podset-required-topology) for implementation details.
References
More news

First look at the Google Home app powered by Gemini
The Verge reports Google is updating the Google Home app to bring Gemini features, including an Ask Home search bar, a redesigned UI, and Gemini-driven controls for the home.

Shadow Leak shows how ChatGPT agents can exfiltrate Gmail data via prompt injection
Security researchers demonstrated a prompt-injection attack called Shadow Leak that leveraged ChatGPT’s Deep Research to covertly extract data from a Gmail inbox. OpenAI patched the flaw; the case highlights risks of agentic AI.

Move AI agents from proof of concept to production with Amazon Bedrock AgentCore
A detailed look at how Amazon Bedrock AgentCore helps transition agent-based AI applications from experimental proof of concept to enterprise-grade production systems, preserving security, memory, observability, and scalable tool management.

Predict Extreme Weather in Minutes Without a Supercomputer: Huge Ensembles (HENS)
NVIDIA and Berkeley Lab unveil Huge Ensembles (HENS), an open-source AI tool that forecasts low-likelihood, high-impact weather events using 27,000 years of data, with ready-to-run options.

Scaleway Joins Hugging Face Inference Providers for Serverless, Low-Latency Inference
Scaleway is now a supported Inference Provider on the Hugging Face Hub, enabling serverless inference directly on model pages with JS and Python SDKs. Access popular open-weight models and enjoy scalable, low-latency AI workflows.

Google expands Gemini in Chrome with cross-platform rollout and no membership fee
Gemini AI in Chrome gains access to tabs, history, and Google properties, rolling out to Mac and Windows in the US without a fee, and enabling task automation and Workspace integrations.