Oldcastle accelerates document processing with Amazon Bedrock and Textract
Sources: https://aws.amazon.com/blogs/machine-learning/oldcastle-accelerates-document-processing-with-amazon-bedrock, https://aws.amazon.com/blogs/machine-learning/oldcastle-accelerates-document-processing-with-amazon-bedrock/, AWS ML Blog
TL;DR
- Oldcastle APG processes 100,000–300,000 ship tickets per month across more than 200 facilities, a task previously hampered by an unreliable OCR system. AWS ML Blog
- The company moved to an end-to-end, event-driven workflow using Amazon SES, S3 Event Notifications, Textract, and Amazon Bedrock to automate the processing of POD documents. AWS ML Blog
- Bedrock, paired with Textract, provided cost-effective batch processing and consistent field extraction across similar document formats, reducing the need for manual intervention. AWS ML Blog
- Oldcastle is exploring expansion to AP invoices, W-9 form validation, and automated document approvals, signaling a scalable path for AI-powered document processing. AWS ML Blog
Context and background
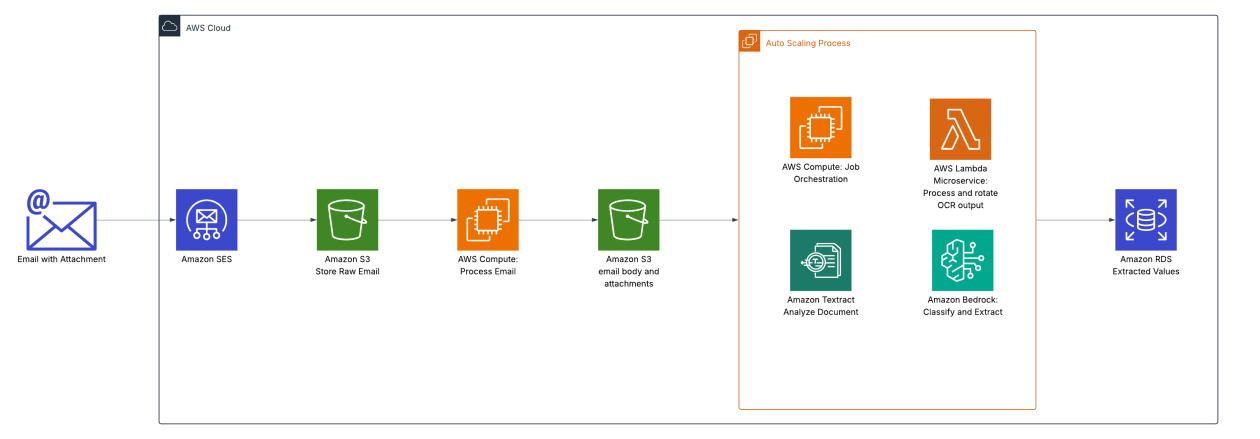
Oldcastle APG, a major global network in the architectural products industry, faced a labor-intensive and error-prone process for handling proof of delivery (POD) documents, commonly known as ship tickets. The organization relied on an OCR system that was unreliable and required constant maintenance and manual intervention. The result was low accuracy, high resource consumption, and delays across more than 200 facilities. The challenge was twofold: streamline POD processing and implement a solution for processing supplier invoices and matching them against purchase orders, given the variability in document formats. AWS ML Blog The company’s dispatch network relied on manual handling by on-site staff, with 4–5 hours per day spent on ship-ticket processing. The IT team also bore the burden of ongoing maintenance and development to keep the OCR system functioning. AWS Solutions Architects collaborated with Oldcastle engineers to design a scalable solution that could automate the document processing workflow end to end. AWS ML Blog Oldcastle’s approach centers on an event-driven architecture that begins with Amazon Simple Email Service (Amazon SES) receiving ship tickets sent directly from drivers. The workflow leverages Amazon S3 Event Notifications to process documents at scale and routes them to an auto-scaling compute job orchestrator. The architecture highlights how Amazon Textract handles large PDF files, producing outputs with geometries used to rotate and fix layouts before converting content into markdown. Quality markdown layouts are essential for Amazon Bedrock to identify the correct key-value pairs. AWS ML Blog
What’s new
The integration combines multiple AWS services to automate POD processing and invoice matching with a focus on cost efficiency and scalability:
- Email-based intake via Amazon SES for ship tickets
- Event-driven processing using Amazon S3 Event Notifications
- Automatic scaling compute job orchestrator to handle variable loads
- Document extraction with Amazon Textract, including handling large PDFs and producing structured geometry data for layout correction
- Data extraction and formatting into Markdown to enable downstream extraction by Amazon Bedrock
- Use of Amazon Bedrock for cost-effective data extraction on standardized fields across similar document formats
- Cost optimization by extracting only the data needed to limit output tokens and by employing Bedrock batch processing for lower token costs
- A demonstrated pathway toward expanding to AP invoices, W-9 form validation, and automated document approvals These steps collectively demonstrate a practical, scalable approach that can be adapted to other document-processing challenges and to AI-powered business-process optimization. AWS ML Blog
Why it matters (impact for developers/enterprises)
This case shows how a large, distributed operation can modernize its document workflows with an end-to-end AI-powered pipeline. Key takeaways include:
- An end-to-end, event-driven architecture can scale to hundreds of thousands of documents per month while reducing manual intervention. AWS ML Blog
- Leveraging Textract alongside Bedrock can exploit the strengths of a powerful OCR/structure extraction tool and a cost-effective large-language model platform to extract consistent fields across similar document formats. AWS ML Blog
- Cost optimization is achievable by limiting output tokens and using Bedrock batch processing, making AI-powered document processing financially viable at scale. AWS ML Blog
- The solution demonstrates a path to broader AI adoption, including AP invoices, W-9 validation, and automated document approvals, indicating a scalable template for enterprise workflows. AWS ML Blog
Technical details or Implementation
The architecture centers on a robust, scalable, and secure intake and processing pipeline:
- Intake: Ship tickets arrive via Amazon SES and are delivered to the system from drivers in the field. AWS ML Blog
- Ingestion and routing: Documents are surfaced through an event-driven workflow using Amazon S3 Event Notifications, enabling scalable processing as soon as new tickets arrive. AWS ML Blog
- Orchestration: An automatic scaling compute job orchestrator manages processing tasks, ensuring resources grow or shrink with demand. AWS ML Blog
- Extraction and layout handling: Textract processes large PDF files, producing outputs that contain the geometries needed to rotate content and fix layout issues before generating markdown. This markdown is designed to support Bedrock’s key-value extraction, helping identify correct data fields. AWS ML Blog
- Data shaping and cost control: The extracted data is reshaped into a format suitable for Bedrock, and only the necessary data is extracted to limit output tokens. Bedrock batch processing is used to reduce token costs further. AWS ML Blog
- Platform choice: Bedrock was selected for its cost-effectiveness and its ability to process formats where the fields to extract are the same, enabling a consistent extraction process across tickets. AWS ML Blog The implementation is designed to be replicable for similar experience with supplier invoices and purchase-order matching, providing a scalable blueprint for AI-powered document processing. The original publication documents these choices and outcomes. AWS ML Blog
Key takeaways
- AI-powered document processing can replace brittle OCR with a robust, scalable workflow that spans email intake through to AI-assisted data extraction. AWS ML Blog
- An end-to-end, event-driven architecture enables handling large document volumes across hundreds of facilities with reduced manual effort. AWS ML Blog
- Textract and Bedrock work together to extract and structure data efficiently, with cost-conscious design choices like limiting output tokens and batch processing. AWS ML Blog
- The solution opens opportunities for expanding to related use cases such as AP invoice processing, W-9 validations, and automated document approvals. AWS ML Blog
FAQ
-
What problem did Oldcastle face?
Oldcastle struggled with an inefficient, labor-intensive POD processing workflow and an OCR system that could only read 30–40% of documents, requiring ongoing maintenance. [AWS ML Blog](https://aws.amazon.com/blogs/machine-learning/oldcastle-accelerates-document-processing-with-amazon-bedrock/)
-
How does the new solution work at a high level?
It uses SES to receive ship tickets, S3 Event Notifications for event-driven processing, a scalable orchestrator, Textract for extraction, and Bedrock for cost-effective data processing on standardized fields. [AWS ML Blog](https://aws.amazon.com/blogs/machine-learning/oldcastle-accelerates-document-processing-with-amazon-bedrock/)
-
How is cost managed in this setup?
The approach limits output tokens by extracting only the data needed and leverages Bedrock batch processing to minimize token costs. [AWS ML Blog](https://aws.amazon.com/blogs/machine-learning/oldcastle-accelerates-document-processing-with-amazon-bedrock/)
-
What future use cases are envisioned?
Potential expansion includes AP invoice processing, W-9 form validation, and automated document approval workflows. [AWS ML Blog](https://aws.amazon.com/blogs/machine-learning/oldcastle-accelerates-document-processing-with-amazon-bedrock/)
References
- AWS ML Blog: Oldcastle accelerates document processing with Amazon Bedrock. https://aws.amazon.com/blogs/machine-learning/oldcastle-accelerates-document-processing-with-amazon-bedrock/
More news

First look at the Google Home app powered by Gemini
The Verge reports Google is updating the Google Home app to bring Gemini features, including an Ask Home search bar, a redesigned UI, and Gemini-driven controls for the home.

Shadow Leak shows how ChatGPT agents can exfiltrate Gmail data via prompt injection
Security researchers demonstrated a prompt-injection attack called Shadow Leak that leveraged ChatGPT’s Deep Research to covertly extract data from a Gmail inbox. OpenAI patched the flaw; the case highlights risks of agentic AI.

Move AI agents from proof of concept to production with Amazon Bedrock AgentCore
A detailed look at how Amazon Bedrock AgentCore helps transition agent-based AI applications from experimental proof of concept to enterprise-grade production systems, preserving security, memory, observability, and scalable tool management.

Predict Extreme Weather in Minutes Without a Supercomputer: Huge Ensembles (HENS)
NVIDIA and Berkeley Lab unveil Huge Ensembles (HENS), an open-source AI tool that forecasts low-likelihood, high-impact weather events using 27,000 years of data, with ready-to-run options.

Scaleway Joins Hugging Face Inference Providers for Serverless, Low-Latency Inference
Scaleway is now a supported Inference Provider on the Hugging Face Hub, enabling serverless inference directly on model pages with JS and Python SDKs. Access popular open-weight models and enjoy scalable, low-latency AI workflows.

Google expands Gemini in Chrome with cross-platform rollout and no membership fee
Gemini AI in Chrome gains access to tabs, history, and Google properties, rolling out to Mac and Windows in the US without a fee, and enabling task automation and Workspace integrations.