Natural language-based database analytics with Amazon Nova
Sources: https://aws.amazon.com/blogs/machine-learning/natural-language-based-database-analytics-with-amazon-nova, https://aws.amazon.com/blogs/machine-learning/natural-language-based-database-analytics-with-amazon-nova/, AWS ML Blog
TL;DR
- Natural language database analytics are enabled by Amazon Nova foundation models (Nova Pro, Nova Lite, Nova Micro) and the ReAct pattern implemented via LangGraph, allowing conversation-like interactions with complex database systems.
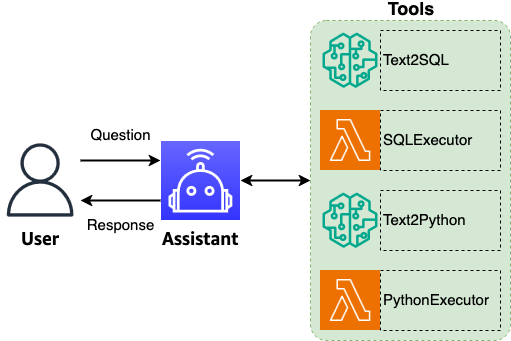
- The solution centers on three core components—UI, generative AI, and data—and uses an agent to coordinate questions, reasoning, workflow orchestration, and comprehensive natural language responses with self-remediation.
- It supports self-healing and human-in-the-loop (HITL) workflows to validate and refine SQL queries, ensuring results match user intent and schema requirements.
- Evaluations on the Spider text-to-SQL dataset show competitive accuracy and low latency for cross-domain translation tasks, with notable strengths on the most complex queries. For production deployments, security considerations for Streamlit in the demo are noted.
- The GenAIIC collaboration provides access to experts to identify valuable use cases and tailor practical generative AI solutions; the architecture is built on Amazon Bedrock to enable natural language to SQL and data visualizations.
Context and background
Natural language interfaces to databases have long been a goal in data management. The approach described here leverages large language model (LLM) agents to decompose complex queries into explicit, verifiable reasoning steps and to enable self-correction through validation loops. By catching errors, analyzing failures, and refining queries, the system moves toward matching user intent and schema requirements with precision and reliability. This enables intuitive, conversation-like interactions with sophisticated database systems while preserving analytical accuracy. To achieve optimal performance with minimal trade-offs, the solution uses the Amazon Nova family of foundation models (Nova Pro, Nova Lite, and Nova Micro). These FMs encode vast amounts of world knowledge, enabling nuanced reasoning and contextual understanding essential for complex data analysis. The ReAct (reasoning and acting) pattern is implemented through LangGraph’s flexible architecture, combining the strengths of Amazon Nova LLMs for natural language understanding with explicit reasoning steps and actions. The result is a modern approach to natural language database analytics that supports automated analysis and natural language querying across datasets. Many customers undergoing generative AI transformation recognize that their vast data stores hold untapped potential for automated analysis. This insight often leads to SQL-based exploration, from simple SELECT statements to complex, multipage queries with rich aggregations and functions. The core challenge remains translating user intent—stated or implicit—into performant, precise, and valid SQL queries that retrieve the correct dataset for downstream visualization and exploration. Our solution excels in generating context- and metadata-aware queries capable of retrieving precise datasets and performing intricate analyses. A user-friendly interface is essential, and we have developed an intuitive interface where users can be guided through their analysis journey with human-in-the-loop (HITL) capabilities, allowing input, approvals, and modifications at key decision points. The interface and workflow are designed to support a cohesive analysis journey, not a single query.
What’s new
The architecture described in this post introduces three core components—UI, generative AI, and data—along with an intelligent agent that serves as the central coordinator. The agent performs question understanding, decision-making, workflow orchestration, intelligent routing, and the generation of comprehensive natural language responses. It enhances questions by improving text quality, standardizing terminology, and maintaining conversational context to enable users to extend analysis through a sequence of related queries while preserving precise analytical intent. Key capabilities include intelligent routing to invoke the correct tools for each user question, enabling end-to-end query processing that can also process tabular and visual data. The agent uses the full context to generate comprehensive summaries explaining findings, highlighting key insights, and suggesting relevant follow-up questions. A notable added benefit is the agent’s ability to propose relevant follow-up topics to deepen data exploration and uncover unexpected insights. The agent maintains context across conversations so users can provide minimal follow-up inputs, while abbreviated questions are reconstructed from earlier context for confirmation. After each exchange, the agent suggests follow-up exploratory questions to continue the investigation. Consistent terminology is enforced, expanding abbreviations to full forms (for example, GDPR becomes General Data Protection Regulation) to ensure clarity in inputs and outputs. The solution supports self-remediation: when an execution error occurs, the agent uses the error and full context to regenerate a corrected SQL query. This self-healing approach provides robustness in complex scenarios and helps maintain reliable query processing. The agent’s outputs include a natural language summary, tabular results with reasoning, visualizations with explanations, and a concise insights summary. Production deployments leverage Streamlit for illustration, though security configurations and deployment architectures should be reviewed to align with organizational requirements. The Generative AI Innovation Center (GenAIIC) at AWS has developed this natural language-based database analytics solution, which combines the strengths of Amazon Nova FMs with explicit reasoning steps and actions implemented via ReAct in LangGraph’s architecture. The solution is built on Amazon Bedrock, enabling intuitive, conversation-like interactions with complex database systems and the seamless translation of natural language queries into accurate SQL statements and insightful data visualizations. Evaluation results indicate competitive performance, highlighting the potential to democratize data access and analysis with natural language interfaces. The GenAIIC also offers access to a team of experts to help identify valuable use cases and implement practical generative AI solutions tailored to specific needs. For more information, see Amazon Nova Foundation Models and Amazon Bedrock. If you’re interested in collaborating with GenAIIC, you can find more information at AWS Generative AI Innovation Center.
Technical details or Implementation
Architecture and core components
The solution architecture comprises three core components: UI, generative AI, and data. An agent acts as the central coordinator, combining capabilities such as question understanding, decision-making, workflow orchestration, intelligent routing, and generating comprehensive natural language responses. The agent enhances text quality, standardizes terminology, and preserves conversational context to support a sequence of related queries while maintaining precise analytical intent. Its intelligent routing ensures that the correct tools are invoked for each user question, enabling cohesive end-to-end query processing. The workflow enables processing of tabular and visual data and uses full context to generate summaries and insights.
The agent and self-healing capabilities
A key feature is the agent’s self-remediation capability. When execution errors occur, the agent uses the errors and the full context to regenerate a corrected SQL query. This self-healing approach provides robust and reliable query processing, even in complex scenarios. The agent processes inputs—the rewritten question, results from analysis, and context—to produce a natural language summary and a response that includes tabular results with reasoning, explanations for visualizations, and a concise insights summary. The agent maintains context across conversations, reconstructing abbreviated questions from prior context for confirmation and suggesting follow-up questions after each exchange.
Data processing, visualization, and language standardization
The system’s design supports processing both tabular and visual data and generating comprehensive outputs that explain findings and highlight insights. It standardizes terminology to align with industry standards, customer guidelines, and brand requirements, expanding abbreviations to their full forms to improve clarity in both inputs and outputs.
Evaluation and production considerations
The solution was evaluated on the Spider text-to-SQL dataset, a widely used benchmark for cross-domain semantic parsing and text-to-SQL tasks. The Spider dataset comprises 10,181 questions and 5,693 unique complex SQL queries across 200 databases spanning 138 domains. The evaluation was conducted in a zero-shot setting (no fine-tuning on dataset examples) to assess general text-to-SQL translation abilities. Metrics focused on overall accuracy and efficiency, with results indicating competitive performance and low latency for translation tasks, especially on complex queries. The Spider evaluation helps compare Amazon Nova against state-of-the-art approaches and demonstrates its potential to support natural language querying at scale.
Demo and production readiness notes
The Streamlit interface is used for illustration purposes in the demo. For production deployments, security configurations and deployment architectures should be reviewed to ensure alignment with organizational security requirements and best practices. The GenAIIC provides access to experts who can help identify valuable use cases and tailor practical generative AI solutions to specific needs, complementing the underlying Nova and Bedrock technologies.
Prerequisites and deployment steps (high-level)
- Use SageMaker notebook instances to experiment with the solution.
- Download and prepare the database used for querying.
- Start the Streamlit application with the command: streamlit run app.py. The demo illustrates the interface and flow; production deployments should account for security and scalability considerations.
Tables and key facts
| Component | Description |
|---|---|
| Core models | Amazon Nova Pro, Nova Lite, Nova Micro |
| Pattern | ReAct (reasoning and acting) implemented via LangGraph |
| Platform | Amazon Bedrock |
| Evaluation dataset | Spider text-to-SQL (zero-shot) |
| Data domains | 138 domains across 200 databases |
Why it matters (impact for developers/enterprises)
- Enables end-to-end natural language querying over structured data with precise SQL generation, reducing the barrier to data access for analysts and decision-makers.
- Uses explicit reasoning steps and actions, improving transparency and traceability of the analytical process.
- Supports self-healing queries and HITL workflows to improve robustness and reliability in real-world deployments.
- Provides a scalable approach to cross-domain query translation and data exploration with low latency, even for complex queries.
- Offers access to expert guidance through GenAIIC to identify impactful use cases and tailor solutions to organizational needs.
Key takeaways
- Amazon Nova, guided by the ReAct pattern and LangGraph, enables natural language to SQL translation with explicit reasoning.
- A central agent coordinates questions, routing, and outputs, while maintaining context across a multi-turn dialogue.
- Self-remediation and HITL allow the system to recover from execution errors and refine results to user intent.
- Spider dataset evaluation demonstrates competitive performance in zero-shot cross-domain text-to-SQL tasks with low latency.
- Streamlit demo showcases the interface, but production deployments require security-conscious configurations.
FAQ
-
What is the role of Amazon Nova in this solution?
mazon Nova provides the foundation models used for natural language understanding and reasoning, enabling NL-to-SQL translation within the ReAct framework.
-
How does self-healing work in practice?
When execution errors occur, the agent uses the errors and full context to regenerate a corrected SQL query, improving robustness.
-
What is LangGraph’s role?
LangGraph implements the ReAct pattern, coordinating reasoning steps and actions with the Nova models to drive end-to-end query processing.
-
What dataset underpins the evaluation, and what does it show?
The Spider text-to-SQL dataset (10,181 questions, 5,693 SQL queries across 200 databases / 138 domains) was used in a zero-shot setting to assess generalization, showing competitive accuracy and low latency.
-
Where can I learn more or collaborate with GenAIIC?
The GenAIIC offers access to experts to help identify use cases and implement practical generative AI solutions; more information is available through AWS Generative AI Innovation Center channels described in the post.
References
- https://aws.amazon.com/blogs/machine-learning/natural-language-based-database-analytics-with-amazon-nova/
- Amazon Nova Foundation Models and Amazon Bedrock references are mentioned in the article as part of the solution context.
More news

First look at the Google Home app powered by Gemini
The Verge reports Google is updating the Google Home app to bring Gemini features, including an Ask Home search bar, a redesigned UI, and Gemini-driven controls for the home.

Shadow Leak shows how ChatGPT agents can exfiltrate Gmail data via prompt injection
Security researchers demonstrated a prompt-injection attack called Shadow Leak that leveraged ChatGPT’s Deep Research to covertly extract data from a Gmail inbox. OpenAI patched the flaw; the case highlights risks of agentic AI.

Move AI agents from proof of concept to production with Amazon Bedrock AgentCore
A detailed look at how Amazon Bedrock AgentCore helps transition agent-based AI applications from experimental proof of concept to enterprise-grade production systems, preserving security, memory, observability, and scalable tool management.

Predict Extreme Weather in Minutes Without a Supercomputer: Huge Ensembles (HENS)
NVIDIA and Berkeley Lab unveil Huge Ensembles (HENS), an open-source AI tool that forecasts low-likelihood, high-impact weather events using 27,000 years of data, with ready-to-run options.

Scaleway Joins Hugging Face Inference Providers for Serverless, Low-Latency Inference
Scaleway is now a supported Inference Provider on the Hugging Face Hub, enabling serverless inference directly on model pages with JS and Python SDKs. Access popular open-weight models and enjoy scalable, low-latency AI workflows.

Google expands Gemini in Chrome with cross-platform rollout and no membership fee
Gemini AI in Chrome gains access to tabs, history, and Google properties, rolling out to Mac and Windows in the US without a fee, and enabling task automation and Workspace integrations.