Build a serverless Amazon Bedrock batch job orchestration workflow with AWS Step Functions
Sources: https://aws.amazon.com/blogs/machine-learning/build-a-serverless-amazon-bedrock-batch-job-orchestration-workflow-using-aws-step-functions, https://aws.amazon.com/blogs/machine-learning/build-a-serverless-amazon-bedrock-batch-job-orchestration-workflow-using-aws-step-functions/, AWS ML Blog
TL;DR
- Amazon Bedrock batch inference offers a cost-effective, scalable path for high-volume workloads with a 50% discount versus on‑demand processing.
- This article presents a serverless orchestration pattern using AWS Step Functions and an AWS CDK stack to manage preprocessing, parallel batch jobs, and postprocessing.
- The workflow is demonstrated on 2.2 million rows from the SimpleCoT dataset, using either text generation or embeddings workflows.
- Prompt templates and input formatting are centralized in code (prompt_templates.py and prompt_id_to_template), with configurable input sources including Hugging Face datasets or S3 CSV/Parquet files.
- The solution is designed to be cost-aware and scalable, with explicit guidance on monitoring, concurrency, and resource cleanup.
Context and background
As organizations increasingly adopt foundation models for AI/ML workloads, large-scale inference patterns fall into two broad categories: real-time inference and batch inference. Batch inference is suited for processing massive datasets where immediate results are not required, and Bedrock provides a cost-effective option with a stated 50% discount compared with on-demand processing. Implementing batch inference at scale introduces challenges such as input formatting, managing job quotas, orchestrating concurrent executions, and handling postprocessing to interpret model outputs. The approach described here addresses these challenges by combining scalable, serverless components into a streamlined batch orchestration framework. The workflow covers three phases: preprocessing input datasets (for example, formatting prompts), executing batch jobs in parallel, and postprocessing model outputs to parse results. This solution is designed to be flexible and scalable, enabling workflows such as generating embeddings for large document collections or running custom evaluation or completion tasks on large datasets. The architecture is embedded in an AWS Cloud Development Kit (CDK) stack that deploys a Step Functions state machine to orchestrate the end-to-end process. In the featured use case, the 2.2 million rows from the SimpleCoT dataset on Hugging Face are used to demonstrate the pipeline. SimpleCoT is a collection of task-oriented examples designed to illustrate chain-of-thought reasoning in language models and spans a range of problem types from reading comprehension to mathematical reasoning and NLP tasks. The Bedrock batch orchestration pattern employs scalable, serverless components to address the core architectural considerations of batch processing workflows. The subsequent sections walk through the steps to deploy the AWS CDK stack and run the workflow in your AWS environment.
What’s new
This post highlights a serverless, scalable architecture for large-scale batch processing with Amazon Bedrock batch inference, orchestrated by AWS Step Functions. It demonstrates how to:
- Preprocess inputs and format prompts via a configurable prompt_templates.py module and a prompt_id_to_template mapping that ties a job to a specific prompt.
- Launch parallel batch inference jobs and manage them with a Step Functions state machine deployed via CDK.
- Postprocess model outputs to extract results, aggregating them into Parquet files that mirror input data columns with added response or embedding information. A concrete workflow is shown using 2.2 million rows from SimpleCoT. The setup uses a CDK-driven stack, and the process can be extended to other datasets or FM workloads. The maximum concurrency is controlled by a context variable maxConcurrentJobs in cdk.json, providing a straightforward knob to tune throughput and cost. The example also demonstrates how to switch between text generation and embedding tasks by adjusting the input data structure and prompt templates. In addition to deploying the stack with CDK, the article shows how to identify the CloudFormation outputs that reveal the names of the input data bucket and the Step Functions workflow, enabling you to locate and monitor resources quickly. The workflow accepts input in the form of an S3 URI pointing to a dataset stored in CSV or Parquet formats, or a Hugging Face dataset reference, depending on the use case.
Why it matters (impact for developers/enterprises)
For developers and enterprises, this approach unlocks scalable, cost-efficient batch processing for large-scale FM workloads. Key benefits include:
- Substantial cost savings for batch inference through Bedrock’s discount vs on-demand processing, making it feasible to run embeddings or generation tasks over millions of records.
- A serverless, orchestration-first pattern that minimizes operational overhead while enabling reliable, repeatable batch workflows.
- A clear separation of concerns across preprocessing, computation, and postprocessing, reducing the complexity of managing large-scale inference pipelines.
- Easy integration with datasets stored in S3 or sourced from Hugging Face, enabling flexible data workflows and reuse across projects.
- Explicit controls for concurrency and batch sizing, allowing cost and performance to be tuned to organizational needs. For organizations exploring data labeling, synthetic data generation, or model distillation workflows, this pattern provides a practical blueprint for building end-to-end batch inferencing pipelines in a cloud-native way.
Technical details or Implementation
Below is a high-level view of how to implement the serverless Bedrock batch orchestration workflow, with the key steps and configuration points drawn from the referenced approach.
- Prerequisites: Install the required packages with the following command: npm i
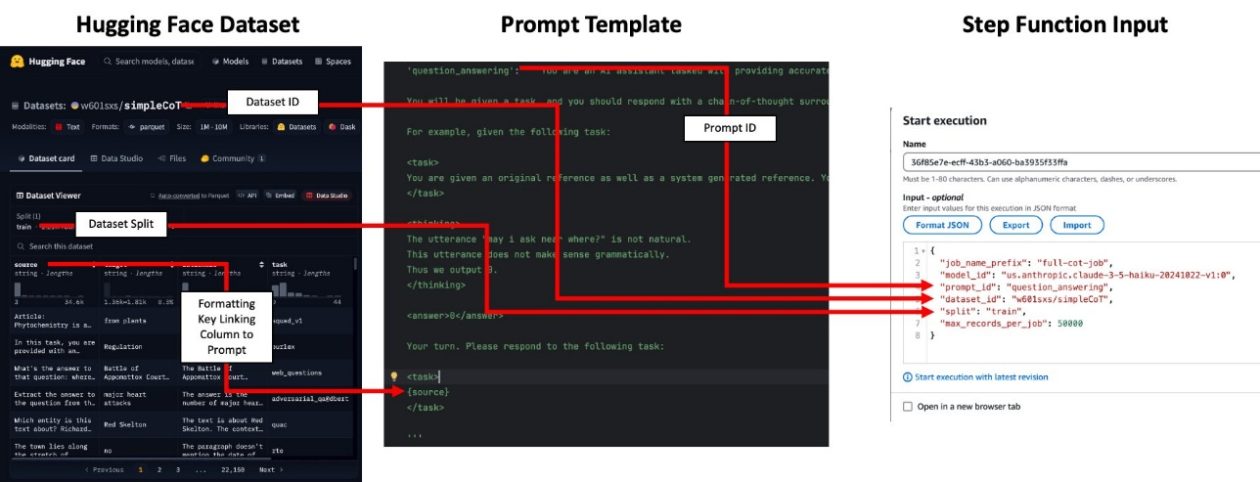
- Prompt templates: Review prompt_templates.py and add a new prompt template to the prompt_id_to_template mapping for your use case. The mapping links a given job to a specific prompt. Ensure that formatting keys in the prompt template correspond to columns in your input dataset, as required for the prompts. Note that prompt templates are not used for embedding model-based jobs.
- Deploy the stack: Deploy the AWS CDK stack with npm run cdk deploy. After deployment, capture the CloudFormation outputs that denote the names of the input data bucket and the Step Functions workflow.
- Prepare input data: Your input can be a Hugging Face dataset ID (for example, w601sxs/simpleCoT) or an S3-based dataset (CSV or Parquet). If using a Hugging Face dataset, reference the dataset ID and a split (for example, train); the dataset will be pulled from the Hugging Face Hub. The dataset columns must align with the required formatting keys in the prompts.
- Prompt mapping and data formatting: The dataset column used for prompting is exposed via a formatting key (for example, topic). The input data must contain a column matching the required key so the prompt can be populated correctly. For embedding tasks, you do not need to provide a prompt_id, but the input CSV must include a column named input_text containing the text to embed.
- Data ingestion and job orchestration: Upload your input CSV or Parquet to the designated S3 bucket (for example, aws s3 cp topics.csv s3://batch-inference-bucket-/inputs/jokes/topics.csv). Open the Step Functions console, and submit an input with an s3_uri pointing to your dataset. The prompt_id maps to a template that formats the query and generates the rationale and answer for each row (or, for embeddings, operates on input_text).
- Concurrency and monitoring: The maximum number of concurrent jobs is controlled by the maxConcurrentJobs context variable in cdk.json. The workflow aggregates the resulting Parquet files, which include the same columns as the input file along with the model outputs. For text generation, the output column is response; for embeddings, the output column is embedding (a list of floats).
- Observability and runtime: There are no guaranteed SLAs for the Batch Inference API. Runtimes vary with model demand. In the presented experiment, processing 2.2 million records spread across 45 jobs with up to 20 concurrent jobs yielded an average per-job runtime of about 9 hours, totaling around 27 hours end to end.
- Cleanup: To avoid ongoing costs, you can tear down resources with cdk destroy. The solution, including the CDK stack, is available in a public GitHub repository linked from the article.
- References and attribution: The workflow and its rationale are described in the AWS blog post linked below, which provides a complete walkthrough and example configuration. The article also includes a conceptual diagram of the solution architecture and implementation details that you can adapt to your own data and models.
| Key configuration | Description |
|---|---|
| maxConcurrentJobs | Controlled via the CDK context variable in cdk.json (key: maxConcurrentJobs) to regulate throughput and cost |
| Input formats | Hugging Face dataset ID or S3 CSV/Parquet files |
| Output format | Parquet files containing the input columns plus either response (text generation) or embedding (list of floats) |
Example workflow steps in practice
- Step 1: Preprocess input data to match prompt templates, ensuring all required formatting keys are present in the dataset.
- Step 2: Launch parallel batch jobs to perform Bedrock batch inference, with concurrency governed by the maxConcurrentJobs setting.
- Step 3: Postprocess outputs to parse model results, aggregating them into Parquet files that preserve the input structure while appending response or embedding data.
Key takeaways
- Bedrock batch inference provides a scalable, cost-efficient path for large-scale inference workloads when real-time results are not required.
- A serverless, Step Functions–driven orchestration pattern can simplify batch workflows by separating preprocessing, computation, and postprocessing concerns.
- The approach supports multiple data sources (Hugging Face datasets or S3) and both text generation and embedding tasks, with outputs stored in Parquet for easy downstream analytics.
- Concurrency controls and CDK-based deployment enable repeatable, auditable pipelines that can be scaled up or down to match workload demands.
- The workflow is documented with concrete examples (including a 2.2 million row dataset) and is ready to adapt to other FM workloads and datasets.
FAQ
-
What problem does this solution address?
It provides a robust, serverless framework to orchestrate batch Bedrock inference at scale, handling preprocessing, parallel execution, and postprocessing.
-
What data sources are supported for input datasets?
You can reference a Hugging Face dataset (by dataset ID and split) or point to a dataset stored in S3 as CSV or Parquet.
-
How is concurrency controlled?
The maximum number of concurrent jobs is controlled by the maxConcurrentJobs context variable in the CDK configuration (cdk.json).
-
How do I clean up resources after testing?
Run cdk destroy to tear down the resources created by the CDK stack.
-
What outputs are produced by the workflow?
The resulting Parquet files contain the input columns plus the model outputs; for text generation this is a response column, and for embeddings this is an embedding column.
References
More news

NVIDIA HGX B200 Reduces Embodied Carbon Emissions Intensity
NVIDIA HGX B200 lowers embodied carbon intensity by 24% vs. HGX H100, while delivering higher AI performance and energy efficiency. This article reviews the PCF-backed improvements, new hardware features, and implications for developers and enterprises.

Move AI agents from proof of concept to production with Amazon Bedrock AgentCore
A detailed look at how Amazon Bedrock AgentCore helps transition agent-based AI applications from experimental proof of concept to enterprise-grade production systems, preserving security, memory, observability, and scalable tool management.

Scaleway Joins Hugging Face Inference Providers for Serverless, Low-Latency Inference
Scaleway is now a supported Inference Provider on the Hugging Face Hub, enabling serverless inference directly on model pages with JS and Python SDKs. Access popular open-weight models and enjoy scalable, low-latency AI workflows.

How to Reduce KV Cache Bottlenecks with NVIDIA Dynamo
NVIDIA Dynamo offloads KV Cache from GPU memory to cost-efficient storage, enabling longer context windows, higher concurrency, and lower inference costs for large-scale LLMs and generative AI workloads.

Prompting for precision with Stability AI Image Services in Amazon Bedrock
Amazon Bedrock now offers Stability AI Image Services, extending Stable Diffusion and Stable Image with nine tools for precise image creation and editing. Learn prompting best practices for enterprise use.

Monitor Amazon Bedrock batch inference using Amazon CloudWatch metrics
Learn how to monitor and optimize Amazon Bedrock batch inference jobs with CloudWatch metrics, alarms, and dashboards to improve performance, cost efficiency, and operational oversight.