How Amazon Finance built an AI assistant using Amazon Bedrock and Amazon Kendra to support analysts for data discovery and business insights
Sources: https://aws.amazon.com/blogs/machine-learning/how-amazon-finance-built-an-ai-assistant-using-amazon-bedrock-and-amazon-kendra-to-support-analysts-for-data-discovery-and-business-insights, https://aws.amazon.com/blogs/machine-learning/how-amazon-finance-built-an-ai-assistant-using-amazon-bedrock-and-amazon-kendra-to-support-analysts-for-data-discovery-and-business-insights/, AWS ML Blog
TL;DR
- Amazon Finance built an AI-powered assistant that combines Amazon Bedrock’s LLM capabilities with Amazon Kendra’s intelligent search to help analysts discover data and derive business insights.
- The solution uses Retrieval Augmented Generation (RAG): vector stores enable semantic retrieval, and augmentation grounds model outputs in retrieved knowledge to reduce hallucinations.
- Amazon Kendra Enterprise Edition Index was chosen over OpenSearch Service and Amazon Q Business for its built-in capabilities, multi-format document processing, enterprise connectors, and advanced query handling.
- The UI is built with Streamlit; evaluation shows a 30% reduction in search time and an 80% improvement in search result accuracy, with measurable precision and recall gains in data discovery and knowledge search.
- The architecture standardizes data access across Amazon Finance, preserves institutional knowledge, and improves decision-making agility for complex financial planning. The claims below summarize a real-world deployment described by the Amazon Finance team and cited in the AWS ML Blog [https://aws.amazon.com/blogs/machine-learning/how-amazon-finance-built-an-ai-assistant-using-amazon-bedrock-and-amazon-kendra-to-support-analysts-for-data-discovery-and-business-insights/].
Context and background
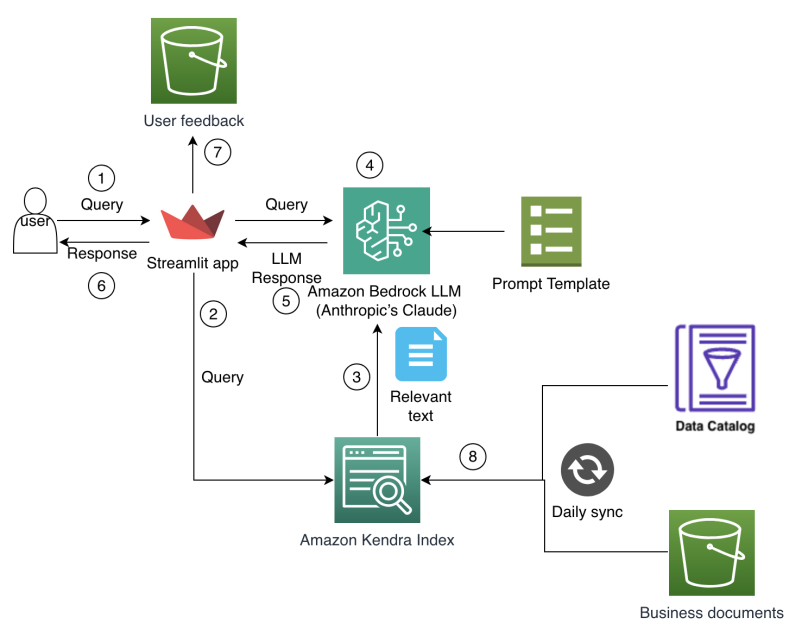
Finance analysts across Amazon Finance face mounting complexity in planning and analysis as they work with vast datasets spanning multiple systems, data lakes, and business units. Manual browsing of data catalogs and reconciling data from disparate sources consumes substantial time, leaving less headroom for analysis and insight generation. Historical data and past decisions live in documents and legacy systems, making it hard to reuse learnings during planning cycles. As business contexts evolve, analysts require quick access to relevant metrics, planning assumptions, and financial insights to drive data-driven decisions. Traditional tools and workflows relying on keyword-based searches and rigid query structures struggle to capture contextual relationships in financial data and often fail to preserve institutional knowledge, leading to redundant analyses and inconsistent planning assumptions across teams. In short, analysts needed a more intuitive way to access, understand, and leverage the organization’s financial knowledge and data assets. The Amazon Finance team built an end-to-end AI-powered assistant to address these challenges by combining generative AI with enterprise search. The goal was to enable analysts to interact with financial data sources and documentation through natural language queries, reducing the need for manual, cross-system searches while ensuring responses stay grounded in an enterprise knowledge base that reflects institutional context and security requirements. This approach not only accelerates data discovery but also helps preserve decision rationales and standardize planning across a distributed organization. The core approach centers on Retrieval Augmented Generation (RAG), which blends retrieval of external knowledge with generation. The system stores and searches high-dimensional representations of text meanings in vector stores to support semantic search, then conditions the language model on retrieved context before generating responses that are grounded in verified sources. This combination substantially lowers the risk of hallucinations and improves factual accuracy in finance-focused conversations. The architecture and implementation rely on large language models (LLMs) hosted on Amazon Bedrock and intelligent search powered by Amazon Kendra to deliver a cohesive, enterprise-grade assistant. This alignment with Bedrock and Kendra enables a seamless, secure, and scalable experience for finance analysts. The specific LLM used is Anthropic’s Claude 3 Sonnet, accessed through Bedrock, chosen for its language generation and reasoning capabilities. The integration with Amazon Kendra enables natural language understanding of user intent and robust retrieval, including semantic search that leverages both keyword and vector representations. The enterprise security features of Kendra are designed to protect data and support compliance requirements for finance use cases. The architecture also benefits from a Streamlit-based UI to enable rapid development, iterative improvements, and an engaging user experience. Inline prompts and templates guide how user queries are formatted, how retrieved knowledge is integrated, and how responses are constrained to stay aligned with enterprise policies and data sources. The result is a conversational AI assistant that can discuss data sources, metrics, planning assumptions, and business context in a way that feels natural to analysts while remaining grounded in corporate knowledge. The overall solution was built around two key components: intelligent retrieval and augmented generation. The retrieval layer uses vector stores to enable semantic search by transforming user queries into vector representations and finding similar vectors in the knowledge base. The augmentation layer then conditions Claude 3 Sonnet on the retrieved context and generates refined, contextually appropriate responses. This separation of retrieval and generation makes it possible to maintain accuracy and reduce hallucinations while delivering a natural-language, data-driven experience for analysts. The system is designed to handle knowledge-intensive tasks typical for finance operations and planning. This Retrieval Augmented Generation (RAG) approach is implemented through a combination of LLMs on Amazon Bedrock and intelligent search using Amazon Kendra, and the architecture is described in detail in the AWS blog post [source].
What’s new
The implementation brings together several modern technologies in a tightly integrated workflow. Key components include:
- Retrieval and augmented generation (RAG) as the core pattern, combining semantic retrieval with grounded generation to produce accurate responses.
- A vector-store-based retrieval layer that enables semantic search beyond keyword matching by representing text meaning in high-dimensional vectors.
- An LLM integrated via Amazon Bedrock (Anthropic Claude 3 Sonnet) to perform natural-language reasoning and generation conditioned on retrieved context.
- Amazon Kendra as the semantic search and enterprise search engine with strong natural language understanding, document processing for many formats, and enterprise connectors. Kendra is integrated with Bedrock to support meaningful conversations informed by retrieved knowledge.
- A choice of tools and UI: Streamlit for a Python-based frontend that accelerates development, supports interactive components, and enables rapid deployment.
- Prompt templates to structure user queries, combine retrieved knowledge, and impose response constraints for better relevance and factual grounding.
- An evaluation framework to quantify both performance (precision, recall, search time) and user experience (response quality, usefulness). The architecture emphasizes grounding responses with verified sources and institutional knowledge, which is essential for finance use cases where accuracy and auditability matter. The team selected Anthropic’s Claude 3 Sonnet for its language-generation capabilities, and integrated it with Bedrock to deliver a cohesive RAG flow that leverages Kendra’s powerful retrieval. The decision to use Kendra Enterprise Edition Index over alternatives reflects a focus on built-in NLP, document processing, connectors, and refined query handling that align with the strict accuracy demands of financial data. A table below summarizes the comparison driving those choices. [source]
Architecture and workflow
The AI assistant’s workflow follows three steps: (1) retrieve relevant information from knowledge sources using semantic search, (2) condition the language model with this retrieved context, and (3) generate refined responses that incorporate the retrieved information. This loop ensures that the assistant’s outputs are grounded in corporate documents and data catalogs while still providing natural-language explanations and insights. The frontend architecture was designed to support rapid modifications, scalability, and security, enabling analysts to interact with data sources and documents through a clean, responsive UI. The dashboard and chat interface are built to accommodate evolving data catalogs and new knowledge sources as metadata expands over time. The evaluation framework was designed to capture both quantitative metrics and qualitative indicators of user experience and response quality. In benchmarking with analysts, the solution achieved a 30% reduction in search time and an 80% improvement in search-result accuracy, reflecting meaningful gains in data discovery efficiency and trust in results. Precision and recall metrics were collected across data discovery and knowledge search tasks: data discovery began at 65% precision and 60% recall without metadata enrichment, while knowledge search reached 83% precision and 74% recall without enrichment. These improvements come with an understanding that metadata richness will continue to evolve, and ongoing metadata collection is expected to uplift performance further. This framework demonstrates a practical path to measuring real-world impact in finance environments. The overall takeaway is that integrating semantic search with a grounded, generative model can transform how analysts access data and derive insights. The source for these design choices and results is the AWS ML Blog post linked in References. [source]
Technical details or Implementation
Core components and rationale:
- Intelligent retrieval with vector stores for semantic search, enabling richer context for the model and more accurate results compared to keyword-only approaches.
- Augmented generation (RAG) to produce contextual, accurate responses by conditioning Claude 3 Sonnet on retrieved information.
- Large language models (LLMs) on Amazon Bedrock, with Anthropic Claude 3 Sonnet chosen for its language-generation and reasoning capabilities.
- Amazon Kendra Enterprise Edition Index used for its advanced NLP, automatic document processing for 40+ formats, pre-built connectors, and intelligent query handling including synonyms and refinement suggestions. This combination reduces the need for manual configuration and improves retrieval quality. The team explicitly contrasted Kendra with OpenSearch Service, noting that OpenSearch requires substantial customization to reach similar capabilities, whereas Kendra provides built-in features that are well-suited to finance use cases. They also compared Kendra with Amazon Q Business and chose Kendra for its robustness and flexibility in retrieval. See the comparisons and rationale in the References.
- UI and tooling: Streamlit was selected for rapid development, Python integration, interactive components, visualization potential, and straightforward deployment. Prompt templates are used to format user queries, integrate retrieved knowledge, and enforce response constraints.
- Evaluation framework: measured metrics such as precision, recall, and time-to-answer to quantify improvements in data discovery and knowledge search. The results highlighted a substantial reduction in search time and a significant uplift in accuracy, with the expectation that metadata enrichment will further improve performance as data catalogs mature. The outcomes and the tool choices are described in the AWS blog post [source]. A concise comparison table helps illustrate why Kendra was favored over alternatives: | Service | Rationale for use | Key features relevant to this use case |---|---|---| | Amazon Kendra Enterprise Edition Index | Out-of-the-box NLP, lower configuration burden | Natural language understanding, automatic document processing for 40+ formats, pre-built enterprise connectors, intelligent query handling including synonyms and refinement suggestions |OpenSearch Service | Requires extensive customization and expertise | Manual feature implementation for keyword/semantic/vector search |Amazon Q Business | Less robust/flexible for this domain | Retrieval capabilities, but not as mature as Kendra for enterprise search | Across these choices, the integration with Bedrock and Kendra enables a cohesive RAG workflow that anchors responses in enterprise data while delivering a natural conversation experience. For the full context, see the AWS blog post linked in References. [source]
Why it matters (impact for developers/enterprises)
This approach demonstrates how enterprises can scale AI-powered data discovery and decision support while maintaining data governance and security. By grounding responses in a centralized knowledge base and using semantic search to surface the right documents, analysts gain faster access to relevant metrics, planning assumptions, and historical rationale. The Retrieval Augmented Generation pattern helps preserve institutional knowledge, reducing the loss of critical decision context when people rotate roles or teams grow. For developers and data engineers, the architecture shows how to combine vector-based retrieval with a capable LLM and a robust enterprise search layer to deliver a production-ready assistant that can handle finance-domain queries with high fidelity. The enterprise-grade features of Kendra, including document processing, connectors, and synonym handling, provide a pragmatic, standards-aligned path for compliance-conscious organizations. The overall impact is improved planning agility, more consistent decision-making, and better interoperability across global operations. The AWS blog post provides a concrete example of these benefits in the context of Amazon Finance. [source]
Key takeaways
- Grounded AI workflows (RAG) can dramatically improve data discovery and insights in finance contexts.
- Semantic retrieval with vector stores complements LLM reasoning to reduce hallucinations and improve factual accuracy.
- Selecting a feature-rich enterprise search like Kendra Enterprise Edition over general-purpose search offers meaningful gains in NLP, document processing, and customization.
- A Streamlit-based UI supports rapid development and iteration while delivering a user-friendly interface for analysts.
- A structured evaluation framework with precision/recall and time-to-answer metrics provides tangible evidence of impact and guides metadata enrichment efforts.
FAQ
-
How does the AI assistant ground its responses?
The assistant retrieves relevant information from knowledge sources using semantic search in a vector-store, conditions the Claude 3 Sonnet model on that context, and then generates refined responses anchored to the retrieved knowledge.
-
Why choose Anthropic’s Claude 3 Sonnet via Bedrock for this use case?
Claude 3 Sonnet offers strong language generation and reasoning capabilities that pair well with retrieval-based grounding, enabling more natural and contextually accurate conversations in finance tasks.
-
What metrics did the team observe during evaluation?
The solution achieved a 30% reduction in search time and an 80% improvement in search-result accuracy, with precision/recall gains in both data discovery and knowledge search.
-
What advantages does Amazon Kendra Enterprise Edition Index provide over options like OpenSearch or Q Business?
Kendra Enterprise Edition offers built-in NLP, automatic document processing for many formats, pre-built connectors, and advanced query features (including synonyms and refinement), reducing manual setup and improving retrieval quality.
References
More news

First look at the Google Home app powered by Gemini
The Verge reports Google is updating the Google Home app to bring Gemini features, including an Ask Home search bar, a redesigned UI, and Gemini-driven controls for the home.

Shadow Leak shows how ChatGPT agents can exfiltrate Gmail data via prompt injection
Security researchers demonstrated a prompt-injection attack called Shadow Leak that leveraged ChatGPT’s Deep Research to covertly extract data from a Gmail inbox. OpenAI patched the flaw; the case highlights risks of agentic AI.

Move AI agents from proof of concept to production with Amazon Bedrock AgentCore
A detailed look at how Amazon Bedrock AgentCore helps transition agent-based AI applications from experimental proof of concept to enterprise-grade production systems, preserving security, memory, observability, and scalable tool management.

Predict Extreme Weather in Minutes Without a Supercomputer: Huge Ensembles (HENS)
NVIDIA and Berkeley Lab unveil Huge Ensembles (HENS), an open-source AI tool that forecasts low-likelihood, high-impact weather events using 27,000 years of data, with ready-to-run options.

Scaleway Joins Hugging Face Inference Providers for Serverless, Low-Latency Inference
Scaleway is now a supported Inference Provider on the Hugging Face Hub, enabling serverless inference directly on model pages with JS and Python SDKs. Access popular open-weight models and enjoy scalable, low-latency AI workflows.

Google expands Gemini in Chrome with cross-platform rollout and no membership fee
Gemini AI in Chrome gains access to tabs, history, and Google properties, rolling out to Mac and Windows in the US without a fee, and enabling task automation and Workspace integrations.