Empowering air quality research with secure, ML-driven predictive analytics
Sources: https://aws.amazon.com/blogs/machine-learning/empowering-air-quality-research-with-secure-ml-driven-predictive-analytics, https://aws.amazon.com/blogs/machine-learning/empowering-air-quality-research-with-secure-ml-driven-predictive-analytics/, AWS ML Blog
TL;DR
- A data imputation workflow fills PM2.5 gaps using ML trained in SageMaker Canvas, orchestrated by AWS Lambda and AWS Step Functions.
- The sample dataset includes over 15 million records from March 2022 to Oct 2022 across Kenya and Nigeria, from 23 sensors in 15 locations.
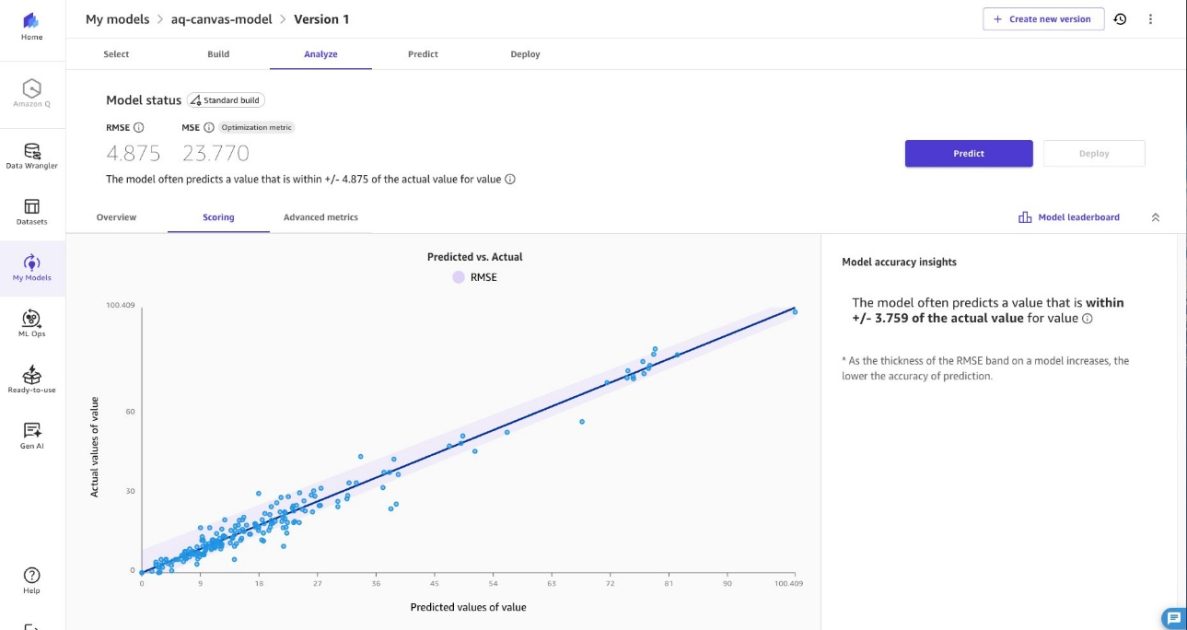
- Predictions are generated for missing PM2.5 values within a range of plus or minus 4.875 µg/m³ to preserve trend accuracy.
- The solution emphasizes security, encryption, and private-network deployment, with a shared responsibility model guiding customer protections.
Context and background
Air pollution remains a critical environmental health challenge in Africa. Organizations like sensors.AFRICA have deployed hundreds of air quality sensors to monitor conditions, but data gaps persist due to power instability and connectivity issues in high-risk regions where maintenance is limited. Missing PM2.5 data reduces statistical power and biases parameter estimates, hindering reliable trend detection and sound conclusions about air quality patterns. These gaps compromise evidence-based decisions for pollution control, health impact assessments, and regulatory compliance. PM2.5 exposure contributes to millions of premature deaths globally, underscoring the importance of accurate forecasting for public health. The post showcases the time-series forecasting capability of Amazon SageMaker Canvas, a low-code/no-code ML platform, to predict PM2.5 values from incomplete datasets. SageMaker Canvas offers resilience to incomplete data, enabling continuous operation of air quality networks during sensor outages or maintenance periods. This helps environmental agencies and public health officials maintain uninterrupted access to critical air quality information for timely alerts and long-term trend analysis. The approach combines SageMaker Canvas forecasting with a data imputation workflow implemented using Amazon SageMaker AI, AWS Lambda, and AWS Step Functions. A sample training dataset sourced from openAFRICA contains over 15 million records (Mar 2022–Oct 2022) from 23 sensor devices across 15 locations in Kenya and Nigeria, illustrating how the solution can be adapted to real-world PM2.5 datasets. The README in the repository provides detailed deployment guidance. The solution’s architecture centers on two ML components: a training workflow and an inference workflow. These workflows are built with SageMaker Canvas for model development and exporting a trained model for batch inference. The end-to-end process begins by extracting sensor data from a database, importing it into SageMaker Canvas for transformation and model training, and then exporting a Canvas-trained model for batch processing. The approach supports retraining as new PM2.5 data become available, ensuring models stay current with evolving sensor patterns.
What’s new
This article demonstrates a complete, secure data-imputation workflow for PM2.5 data gaps using a combination of AWS services. Key features include:
- Time-series forecasting with SageMaker Canvas to predict missing PM2.5 values in datasets containing gaps.
- A robust end-to-end workflow: data extraction from a database, Canvas-based model training, model export, and a batch transform inference pipeline.
- Daily orchestration: a Lambda function runs every 24 hours to trigger a SageMaker batch transform job on newly received data with gaps, then updates the dataset with predicted values.
- Realistic sample data: the demonstration uses a training corpus of over 15 million records from 23 sensors across 15 locations in Kenya and Nigeria (Mar 2022–Oct 2022).
- Security-first deployment: encryption at rest for S3, Aurora PostgreSQL-compatible database, and SageMaker Canvas; encryption in transit via SSL/TLS; temporary IAM-based credentials for RDS access; least-privilege Lambda roles; and a private-subnet deployment using VPC endpoints for S3 and SageMaker AI.
- IaC-driven deployment: model training and deployment stages described within a CDK-based workflow, enabling repeatable, version-controlled updates. To implement the approach, the project provides a Git repository with sample code and a README for step-by-step deployment. The architecture aims to deliver completed PM2.5 datasets to public health decision-makers, supporting timely pollution alerts and more comprehensive long-term analyses.
Why it matters (impact for developers/enterprises)
For developers and enterprises working on environmental monitoring, this approach offers:
- Resilient data pipelines that maintain operational continuity despite sensor downtime, reducing data gaps and downtime costs.
- Actionable PM2.5 insights extracted from incomplete data without requiring complete data streams, helping researchers and policymakers maintain timely trend visibility.
- A scalable, secure, cloud-based solution that integrates with existing data stores (e.g., relational databases like Aurora) and object storage (S3) while maintaining strict security controls.
- An auditable deployment pattern: infrastructure-as-code via CDK enables consistent, repeatable deployments and easier updates when sensor networks change.
- Clear guidance on protecting data in transit and at rest, with granular IAM permissions and private networking to minimize exposure. This work aligns with public health objectives by enabling continuous monitoring and more reliable PM2.5 trend analyses, ultimately supporting evidence-based pollution control strategies and regulatory compliance.
Technical details or Implementation
The solution comprises two main ML components: a training workflow and an inference workflow, both integrated into a secure end-to-end pipeline.
- Data inputs and training
- Historical PM2.5 datasets are ingested from a relational database and prepared in SageMaker Canvas for predictive analysis.
- Canvas supports training a model for single-target PM2.5 prediction with data wrangling steps (transformations, feature engineering) suitable for time-series forecasting.
- After training, Canvas exports the model for batch inference.
- The training dataset referenced in the example contains over 15 million records spanning March 2022 to Oct 2022, drawn from 23 sensor devices across 15 locations in Kenya and Nigeria.
- Inference and data imputation
- A Step Functions orchestration coordinates the workflow, with a Lambda function invoked every 24 hours.
- The Lambda function starts a SageMaker Batch Transform job to predict missing PM2.5 values for the new data with gaps.
- The batch transform processes the entire dataset in one pass, and the Lambda function updates the existing dataset with the predicted values.
- The resulting completed dataset enables distribution to public health decision-makers for more effective pattern analysis of PM2.5 data.
- Model lifecycle and deployment
- After training and evaluation (including RMSE and other metrics), the model is registered in the SageMaker model registry and deployed for batch inference.
- CDK-based deployment creates a SageMaker AI domain and user profile, then provisions the necessary resources for model training and inference.
- A workflow includes creating the SageMaker model in a VPC, deploying the batch transform job, and updating the infrastructure with the new model ID via cdk deploy.
- The solution supports retraining with updated PM2.5 datasets to adapt to evolving sensor data patterns.
- Security and compliance highlights
- Encryption at rest is enabled for Amazon S3, Aurora PostgreSQL-compatible database, and the SageMaker Canvas application.
- Encryption in transit is enforced by SSL/TLS for all connections from Lambda functions.
- Temporary dynamic credentials are used for Amazon RDS access via IAM authentication, eliminating static passwords.
- Each Lambda function operates with least-privilege permissions tailored to its function.
- The Lambda functions, Aurora PostgreSQL-compatible instance, and SageMaker Batch Transform jobs run in private VPC subnets that do not traverse the public Internet, with VPC endpoints for S3 and SageMaker AI.
- Configuration and extensibility
- The architecture is designed to be adaptable to future configuration changes via CDK, with a configuration file detailing parameter defaults.
- The approach emphasizes a security-first mindset and aligns with AWS Shared Responsibility Model, encouraging customers to review responsibilities for secure deployment.
- Tables: key architecture components and roles
| Component | Role |
|---|---|
| SageMaker Canvas | Training and exporting the predictive model for batch inference |
| AWS Lambda | Orchestrates data updates and kicks off batch transforms on a 24-hour cadence |
| AWS Step Functions | Coordinates the end-to-end workflow across services |
| Amazon Aurora PostgreSQL-Compatible | Stores sensor data with IAM-authenticated access |
| Amazon S3 | Immutable data lake storage with encryption at rest |
- References and deployment notes
- The approach is documented with sample code and step-by-step deployment guidance in the referenced Git repository: [email protected]:aws-samples/sample-empowering-air-quality-research-secure-machine-learning-predictive-analytics.git
- The published article is available at https://aws.amazon.com/blogs/machine-learning/empowering-air-quality-research-secure-ml-driven-predictive-analytics/.
Key takeaways
- Incomplete PM2.5 data can be effectively imputed using a SageMaker Canvas-based model and a batch inference pipeline.
- Daily Lambda-triggered batch transforms keep datasets up-to-date with minimal downtime and interruptions to monitoring.
- Security-by-design choices—including encryption, IAM-based credentials, and private subnets—help protect sensitive environmental data.
- An IaC-driven deployment pattern supports repeatable, auditable infrastructure changes and easier scaling.
FAQ
-
How does this solution impute missing PM2.5 values?
The workflow trains a SageMaker Canvas model on historical PM2.5 data and uses a SageMaker Batch Transform job to predict missing values within a range of plus or minus 4.875 µg/m³ of the actual PM2.5 concentration.
-
What data were used in the example?
sample training dataset from openAFRICA containing over 15 million records from March 2022 to Oct 2022, collected across Kenya and Nigeria from 23 sensor devices at 15 locations.
-
Which AWS services comprise the end-to-end pipeline?
SageMaker Canvas for model training and export, AWS Lambda for orchestration, AWS Step Functions for workflow coordination, SageMaker Batch Transform for inference, Amazon Aurora PostgreSQL-compatible database for storage, and Amazon S3 for data lake storage, all in a secure network configuration.
-
How is security implemented?
Encryption at rest for S3, Aurora, and SageMaker Canvas; TLS for data in transit; IAM authentication for temporary RDS credentials; least-privilege Lambda roles; private subnets with VPC endpoints; and alignment with the AWS Shared Responsibility Model.
-
How can I deploy this in my environment?
The solution provides a CDK-based deployment approach and a README in the Git repository, enabling you to reproduce the end-to-end workflow and adapt it to your PM2.5 datasets.
References
- https://aws.amazon.com/blogs/machine-learning/empowering-air-quality-research-secure-ml-driven-predictive-analytics/
- [email protected]:aws-samples/sample-empowering-air-quality-research-secure-machine-learning-predictive-analytics.git
More news

First look at the Google Home app powered by Gemini
The Verge reports Google is updating the Google Home app to bring Gemini features, including an Ask Home search bar, a redesigned UI, and Gemini-driven controls for the home.

Shadow Leak shows how ChatGPT agents can exfiltrate Gmail data via prompt injection
Security researchers demonstrated a prompt-injection attack called Shadow Leak that leveraged ChatGPT’s Deep Research to covertly extract data from a Gmail inbox. OpenAI patched the flaw; the case highlights risks of agentic AI.

Move AI agents from proof of concept to production with Amazon Bedrock AgentCore
A detailed look at how Amazon Bedrock AgentCore helps transition agent-based AI applications from experimental proof of concept to enterprise-grade production systems, preserving security, memory, observability, and scalable tool management.

Predict Extreme Weather in Minutes Without a Supercomputer: Huge Ensembles (HENS)
NVIDIA and Berkeley Lab unveil Huge Ensembles (HENS), an open-source AI tool that forecasts low-likelihood, high-impact weather events using 27,000 years of data, with ready-to-run options.

Scaleway Joins Hugging Face Inference Providers for Serverless, Low-Latency Inference
Scaleway is now a supported Inference Provider on the Hugging Face Hub, enabling serverless inference directly on model pages with JS and Python SDKs. Access popular open-weight models and enjoy scalable, low-latency AI workflows.

Google expands Gemini in Chrome with cross-platform rollout and no membership fee
Gemini AI in Chrome gains access to tabs, history, and Google properties, rolling out to Mac and Windows in the US without a fee, and enabling task automation and Workspace integrations.