How Amazon Health Services Enhanced Discovery in Amazon Search with AWS ML and Gen AI
Sources: https://aws.amazon.com/blogs/machine-learning/learn-how-amazon-health-services-improved-discovery-in-amazon-search-using-aws-ml-and-gen-ai, https://aws.amazon.com/blogs/machine-learning/learn-how-amazon-health-services-improved-discovery-in-amazon-search-using-aws-ml-and-gen-ai/, AWS ML Blog
TL;DR
- Healthcare search involves complex relationships among symptoms, conditions, treatments, and services, requiring advanced understanding of medical terminology and user intent.
- Amazon Health Services solved discovery challenges on Amazon search by leveraging a three part AWS stack: SageMaker for ML models, Bedrock for LLM capabilities, and EMR/Athena for data processing.
- The approach combines ML based query understanding, vector search for product matching, and LLM driven relevance optimization using a retrieval augmented generation pattern.
- A comprehensive knowledge base was expanded with health ontology terms and LLM enhanced prompts, embedded with FAISS for efficient similarity search and stored in S3.
- The solution is now used daily to help customers find everything from prescription medications to primary care and specialized care services through Health Benefits Connector and related offerings.
Context and background
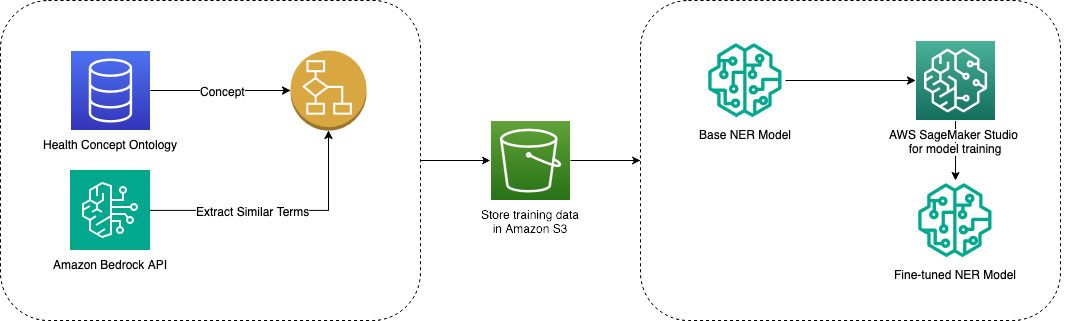
Healthcare discovery on ecommerce domains presents challenges that traditional product search was not designed to handle. Unlike books or electronics, health queries involve nuanced relationships between symptoms, conditions, treatments, and services, requiring sophisticated parsing of medical terminology and customer intent. As Amazon expanded beyond traditional ecommerce into broader healthcare services, the need for improved search discoverability became more pronounced. Amazon now offers direct access to prescription medications via Amazon Pharmacy, primary care via One Medical, and specialized care through Health Benefits Connector. These offerings represent a significant shift from product-only search and introduced unique technical challenges that required a specialized search approach. This post explains how Amazon Health Services (AHS) improved discoverability on Amazon.com search by combining ML, natural language processing, and vector search capabilities across AWS services such as SageMaker, Bedrock, and EMR. The goal was to connect customers with relevant healthcare offerings more effectively, and this solution is now used daily for health related search queries that point customers to prescription medications, care services, or other health focused products. We designed the initiative around two ends of the customer search journey. On one end are spearfishing queries, lower funnel searches where customers know attributes and are seeking specific products such as a prescribed drug with a precise dosage. On the other end are broad upper funnel queries where customers seek information and recommendations related to health topics that might span multiple product types. Examples include back pain relief, acne, and high blood pressure. This framing guided us to build two specialized capabilities that work together to address the full spectrum of health searches. For identifiying spearfishing intent we analyzed anonymized search engagement data for Amazon products and trained a classifier to detect keywords that directly lead to engagement with Amazon Pharmacy ASINs. The data processing for this work leveraged PySpark on Amazon EMR and Athena to collect and process search data at scale. For identifying broad health search intent we trained a named entity recognition model to annotate search keywords at a health terminology level. We built a health ontology based corpus to identify concepts such as health conditions, diseases, treatments, injuries, and medications. When the ontology lacked alternate terms, we used large language models to expand the knowledge base. The NER model is gated behind health relevant product type predictions from query to product type models, ensuring that the right search experience is triggered for different kinds of health intent. A concrete example shows a pharmacy intent like atorvastatin 40 mg triggering a prescription focused experience, while a broad query such as high blood pressure triggers a multi option experience. As part of this effort, Amazon Comprehend Medical is mentioned as a tool for detecting medical entities in text spans, illustrating the broader ecosystem of health NLP capabilities that can be leveraged in similar contexts. To support this capability, we started with our existing offerings and catalog data and used a large language model with a fine tuned prompt and few shot examples to layer in additional health conditions, symptoms, and treatment related keywords for each product or service. The knowledge base was then converted into embeddings using FAISS, and an index file was created to enable efficient similarity search. We maintained mappings from each embedding back to the corresponding knowledge base item to allow accurate reverse lookups when needed. The embedding and knowledge base preparation relied on S3 for storage, and OpenSearch Service was noted as a viable alternative for vector database capabilities. Large scale embedding jobs were executed with scheduled SageMaker Notebook Jobs. A core architectural pattern used is Retrieval Augmented Generation (RAG). The first step is to identify a set of known keywords and Amazon products to establish a ground truth. With the product knowledge base built from catalog metadata and ASIN attributes, we convert incoming customer search queries into embeddings and use them to query the FAISS index. Matches are then evaluated using a relevance labeling scheme known as ESCI — exact, substitute, complement, irrelevant — to maintain quality. Ground truth labeling is performed by a human labeling team, guided by the ESCI framework, and augmented by LLM based labeling using Bedrock batch jobs. The result is a robust, scalable knowledge base that can be efficiently searched and matched to customer queries. The architectural choices are all AWS centric: SageMaker powers the ML models, Bedrock provides LLM capabilities, and EMR together with Athena handles data processing. This combination allows us to cover both the specialized query understanding needed for health search and the scalable processing required to maintain a growing health knowledge base. The outcome is a search experience that aligns customer intent with the most relevant health care products and services, enabling a smoother path to care.
What’s new
- Explicit separation of spearfishing and broad health search intents with dedicated ML and NLP models.
- Introduction of a two step retrieval mechanism: a FAISS based similarity search against a richly expanded health knowledge base, followed by ES CI guided relevance labeling.
- Expanded health knowledge base using an LLM driven augmentation pipeline via Bedrock batch inference, combined with ontology based health terms for accurate entity recognition.
- Use of a RAG style architecture to feed embeddings into a retrieval system and produce relevant results integrated into health oriented search experiences.
- Explicit mention of OpenSearch Service as a viable vector database alternative and the use of S3 for knowledge base storage along with scheduled SageMaker Notebook Jobs for embedding generation.
Why it matters (impact for developers/enterprises)
This work demonstrates how a healthcare focused search solution can be built on top of standard cloud data processing and ML tooling to address domain specific challenges. By incorporating specialized query understanding, ontology based health concepts, and a scalable vector search, teams can improve the relevance of search results for services and products that exist in a broader healthcare ecosystem. The approach also shows how RAG style architectures can be used to maintain up to date health knowledge bases, and how supervision via human labeling combined with LLM based labeling can help sustain high quality results at scale.
Technical details or Implementation
AHS built the solution entirely on AWS and relied on three main components:
- ML models and pipelines powered by Amazon SageMaker for training and inference on health related queries.
- Large language models provided by Amazon Bedrock for relevance optimization and knowledge base augmentation via batch inference.
- Data processing and orchestration using Amazon EMR and Amazon Athena for scalable data collection, processing, and querying. The architecture recognizes two ends of the health search journey:
- Spearfishing queries with explicit product search intent and precise attributes like drug name and dosage.
- Broad health queries seeking information and recommendations across multiple product types. To build the system we implemented several interlocking capabilities:
- A classifier that identifies spearfishing intent by analyzing anonymized search engagement data for pharmacy focused queries, trained on data processed with PySpark on EMR and Athena.
- A named entity recognition model for broad health intent built on a health ontology corpus to recognize conditions, diseases, treatments, injuries, and medications. Terms lacking in the knowledge base were expanded with LLMs, increasing coverage of synonyms and related terms.
- A gating mechanism that routes broad health intents behind health relevant product type predictions, ensuring appropriate search experiences for categories like prescription medications or care services.
- A knowledge base built from catalog metadata and ASIN attributes, enriched with an LLM using Bedrock batch inference to add additional health terms. The entire knowledge base is converted into embeddings with FAISS and stored with an index file. Mappings from embeddings back to knowledge base items are preserved for reverse lookups.
- Storage and orchestration infrastructure including S3 for knowledge base and embeddings files, with OpenSearch Service as a viable vector database option.
- Large scale embedding jobs run via scheduled SageMaker Notebook Jobs to keep the embeddings up to date.
- The Retrieval Augmented Generation pattern is used to connect query embeddings to relevant knowledge base items and to rank results using a defined ES CI framework (exact, substitute, complement, irrelevant).
- Ground truth labeling is performed by a human team and augmented with LLM based labeling using Bedrock batch jobs to improve the model and relevance signals over time.
Key implementation details
| Component | Role
| --- |
|---|
| SageMaker |
| Bedrock |
| EMR and Athena |
| FAISS |
| S3 |
| OpenSearch Service |
| SageMaker Notebook Jobs |
| The overall flow follows a Retrieval Augmented Generation pattern where a query is converted to an embedding, matched against a FAISS index built from a knowledge base of health offerings, and then refined by ES CI labeled relevance signals and an LLM enhanced reranking pass. The system is designed to help customers find relevant health products and services in scenarios ranging from prescription medications to primary and specialized care. |
Key takeaways
- Domain aware search requires specialized query understanding and knowledge representations beyond generic product search.
- A RAG style retrieval system can effectively connect customer queries to health related products and services by combining embeddings with a curated knowledge base.
- LLM based augmentation and ES CI relevance labeling help keep the system aligned with medical terminology and user intent.
- AWS tools like SageMaker, Bedrock, EMR, and FAISS enable scalable construction and maintenance of healthcare knowledge bases within an ecommerce environment.
- Using a combination of ground truth human labeling and LLM based labeling provides strong quality signals for ranking and relevance, improving the discoverability of health offerings on Amazon.
FAQ
-
What problem did AHS address in Amazon search?
They addressed discoverability challenges arising from complex health related queries that involve symptoms, conditions, treatments, and services, beyond traditional product search capabilities.
-
Which AWS services were used to implement the solution?
mazon SageMaker for ML models, Amazon Bedrock for LLM capabilities, and Amazon EMR together with Amazon Athena for data processing.
-
What is the Retrieval Augmented Generation pattern in this context?
RAG uses embeddings to retrieve relevant knowledge base items and then applies generation capability to produce relevant results with improved ranking and relevance.
-
How was health knowledge expanded beyond existing catalog data?
LLMs via Bedrock batch inference augmented the health knowledge base, with terms expanded using health ontology data and few shot prompts.
-
How are embeddings stored and queried?
Embeddings are created with FAISS and stored in a knowledge base with mappings back to items, enabling efficient similarity search and reverse lookups via S3 storage and optional OpenSearch.
References
More news

First look at the Google Home app powered by Gemini
The Verge reports Google is updating the Google Home app to bring Gemini features, including an Ask Home search bar, a redesigned UI, and Gemini-driven controls for the home.

Shadow Leak shows how ChatGPT agents can exfiltrate Gmail data via prompt injection
Security researchers demonstrated a prompt-injection attack called Shadow Leak that leveraged ChatGPT’s Deep Research to covertly extract data from a Gmail inbox. OpenAI patched the flaw; the case highlights risks of agentic AI.

Move AI agents from proof of concept to production with Amazon Bedrock AgentCore
A detailed look at how Amazon Bedrock AgentCore helps transition agent-based AI applications from experimental proof of concept to enterprise-grade production systems, preserving security, memory, observability, and scalable tool management.

Predict Extreme Weather in Minutes Without a Supercomputer: Huge Ensembles (HENS)
NVIDIA and Berkeley Lab unveil Huge Ensembles (HENS), an open-source AI tool that forecasts low-likelihood, high-impact weather events using 27,000 years of data, with ready-to-run options.

Scaleway Joins Hugging Face Inference Providers for Serverless, Low-Latency Inference
Scaleway is now a supported Inference Provider on the Hugging Face Hub, enabling serverless inference directly on model pages with JS and Python SDKs. Access popular open-weight models and enjoy scalable, low-latency AI workflows.

Google expands Gemini in Chrome with cross-platform rollout and no membership fee
Gemini AI in Chrome gains access to tabs, history, and Google properties, rolling out to Mac and Windows in the US without a fee, and enabling task automation and Workspace integrations.