The 'Super Weight': How Even a Single Parameter Can Determine a Large Language Model's Behavior
Sources: https://machinelearning.apple.com/research/the-super-weight
TL;DR
- A tiny subset of LLM parameters, termed “super weights,” can disproportionately shape the model’s behavior.
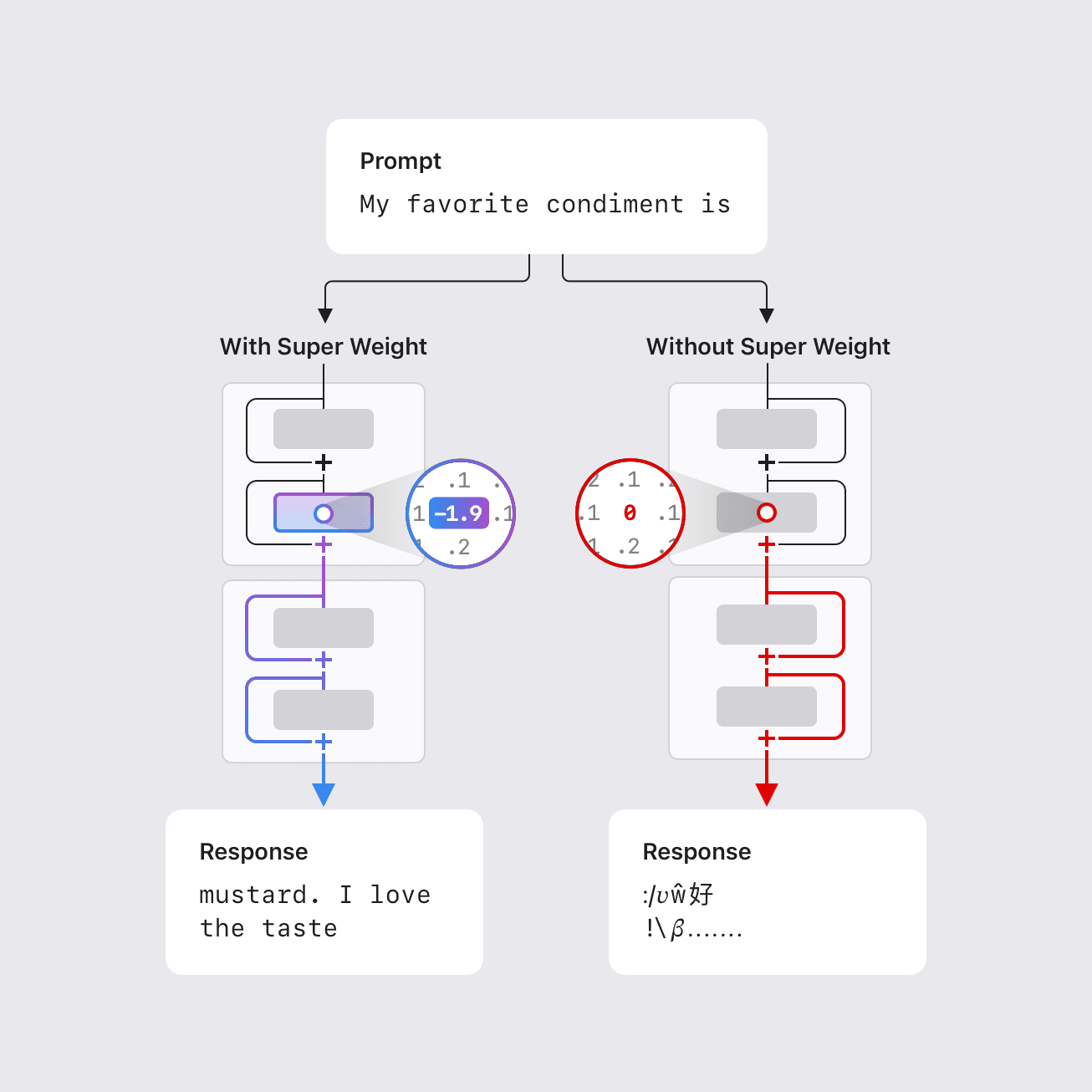
- In some cases, removing a single super weight can destroy the model’s ability to generate coherent text, causing a threefold order of magnitude increase in perplexity and reducing zero-shot accuracy to random-guess levels.
- Super weights induce corresponding “super activations” that persist across layers and bias the model’s outputs globally; removing the weight suppresses this effect.
- A one-pass method can locate these weights by detecting rare, large activation outliers (super activations) that align with the super weight’s channel, typically after the attention block in the down projection of the feed-forward network.
- An index of super weight coordinates has been compiled for several open LLMs to support further research; for example, Llama-7B coordinates are provided.\n
Context and background
Large language models commonly comprise billions or hundreds of billions of parameters, which creates deployment challenges on resource-constrained hardware such as mobile devices. Reducing size and computational demand is essential for local, private use without internet access. Prior work showed that a small fraction of parameter outliers can be vital to maintaining model quality; severing or significantly modifying these weights degrades outputs. In earlier findings, this fraction could be as small as 0.01% of the weights—still hundreds of thousands of parameters in very large models. The new work from Apple researchers identifies a remarkably small number of parameters, called “super weights,” that can destroy an LLM’s ability to generate coherent text when altered. For instance, in the Llama-7B model, removing its single super weight renders the model incapable of producing meaningful output. Conversely, removing thousands of other outlier weights—even those larger in magnitude—produces only modest quality changes. This work proposes a methodology for locating these super weights with a single forward pass through the model, leveraging the observation that super weights induce rare, large activations (super activations) that persist through subsequent layers with a constant magnitude and the same position; their channel aligns with that of the super weight. The study notes that super weights are usually found in the down projection of the feed-forward network after the attention block, often in an early layer. An index of super weight coordinates has been compiled for several common, openly available LLMs (see Table 1) to facilitate further investigation by the research community.\n
What’s new
Apple researchers identify a previously underappreciated phenomenon: a very small number of parameters can decisively determine LLM behavior. The key findings include:
- The existence of “super weights” whose alteration can profoundly disrupt text generation; in some cases, a single parameter is enough to disrupt function. The study notes a threefold order of magnitude increase in perplexity and zero-shot accuracy collapsing toward random guessing when a super weight is removed from certain models.
- The notion of “super activations”: rare, large activations that persist through residual connections and remain aligned with the super weight’s channel, creating a global influence on the model’s internal dynamics.
- A practical, one-pass approach to locate super weights by detecting spikes in activation distributions at specific model components, notably the down projection of the feed-forward network after the attention block.
- The super weight is consistently found in the down projection after the attention block, typically in an early layer, across a range of common LLMs. The researchers provide an index of super weight coordinates for several models to aid replication and further study. An explicit example for Llama-7B on HuggingFace is given: layers[2].mlp.down_proj.weight[3968, 7003].\n
Why it matters (impact for developers/enterprises)
Understanding and identifying super weights has practical implications for model compression and deployment:
- Preservation of super activations with high precision can enable effective compression with simple round-to-nearest quantization, potentially achieving competitive performance with broader quantization methods.
- For weight quantization, preserving the super weight while clipping other weight outliers can allow larger quantization block sizes to remain effective, enabling better compression ratios.
- This targeted approach can offer a hardware-friendly path to running powerful LLMs on resource-constrained devices (e.g., mobile) while maintaining higher overall model quality compared to broader pruning or outlier handling strategies.
- The discovery informs broader questions about LLM design and training, suggesting that a few outliers can shape the model’s semantic outputs and that maintaining their integrity during compression is critical. The work also provides a directory of super weights to spur ongoing community investigation.\n
Technical details or Implementation
The core ideas are summarized as follows:
- Super weights are a tiny, highly influential subset of parameters. Removing a super weight can catastrophically degrade output quality, sometimes more than removing a much larger weight outlier.
- Super activations are large, rare activations that arise after the super weight and persist through subsequent layers with fixed magnitude and position; they align with the super weight’s channel and survive residual connections.
- The proposed detection method requires only a single forward pass and relies on spikes in activation distributions—specifically in components like the down projection of the feed-forward network after the attention block—to locate the super weight and its corresponding activation.
- Location patterns are robust across models: the super weight is typically found in the down projection following the attention block, in an early layer of the network.
- Table 1 in the source lists layer numbers, layer types, and weight types for several models; an explicit example is given for Llama-7B on HuggingFace: access the super weight using layers[2].mlp.down_proj.weight[3968, 7003]. The authors also provide an index of super weight coordinates for several models (Llama 13B, Llama 30B, Llama2 7B/13B, Mistral 7B v0.1, OLMo series, Phi-3 mini, etc.). See the original research for full details.\n | Model (example) | Super weight coordinate (sample) |--- |--- |Llama-7B (HuggingFace) | layers[2].mlp.down_proj.weight[3968, 7003] |
Key takeaways
- A very small subset of parameters can govern LLM behavior, with the potential to drastically alter performance if modified or pruned.
- The concepts of “super weights” and “super activations” offer a lens into the internal dynamics of LLMs and have practical implications for compression strategies.
- A practical, single-pass method can locate these weights by tracking activation outliers, enabling targeted preservation during quantization and pruning.
- The research provides an official coordinate index for several well-known models, enabling broader community validation and experimentation.\n
FAQ
-
What are super weights?
Super weights are an extremely small set of LLM parameters whose alteration can disproportionately affect the model’s ability to generate coherent text or degrade performance.
-
How are super weights found?
The method requires only a single forward pass and detects rare, large activation outliers (super activations) that align with the super weight's channel, typically after the attention block in the down projection of the feed-forward network.
-
Why do super weights matter for compression?
Preserving super activations with high precision can enable effective quantization, and clipping other outliers while preserving the super weight can improve compression ratios without sacrificing much quality.
-
Where are these weights usually located?
The super weight is consistently found in the down projection of the feed-forward network following the attention block, usually in an early layer; an example coordinate is provided for Llama-7B.
References
More news

First look at the Google Home app powered by Gemini
The Verge reports Google is updating the Google Home app to bring Gemini features, including an Ask Home search bar, a redesigned UI, and Gemini-driven controls for the home.

Shadow Leak shows how ChatGPT agents can exfiltrate Gmail data via prompt injection
Security researchers demonstrated a prompt-injection attack called Shadow Leak that leveraged ChatGPT’s Deep Research to covertly extract data from a Gmail inbox. OpenAI patched the flaw; the case highlights risks of agentic AI.

Predict Extreme Weather in Minutes Without a Supercomputer: Huge Ensembles (HENS)
NVIDIA and Berkeley Lab unveil Huge Ensembles (HENS), an open-source AI tool that forecasts low-likelihood, high-impact weather events using 27,000 years of data, with ready-to-run options.

Scaleway Joins Hugging Face Inference Providers for Serverless, Low-Latency Inference
Scaleway is now a supported Inference Provider on the Hugging Face Hub, enabling serverless inference directly on model pages with JS and Python SDKs. Access popular open-weight models and enjoy scalable, low-latency AI workflows.

Google expands Gemini in Chrome with cross-platform rollout and no membership fee
Gemini AI in Chrome gains access to tabs, history, and Google properties, rolling out to Mac and Windows in the US without a fee, and enabling task automation and Workspace integrations.

How to Reduce KV Cache Bottlenecks with NVIDIA Dynamo
NVIDIA Dynamo offloads KV Cache from GPU memory to cost-efficient storage, enabling longer context windows, higher concurrency, and lower inference costs for large-scale LLMs and generative AI workloads.