How Infosys Topaz leverages Amazon Bedrock to transform technical help desk operations
TL;DR
- Infosys Topaz leverages Amazon Bedrock to power a generative AI-based technical help desk for a large energy supplier. AWS blog
- The system ingests past and new call transcripts, builds a knowledge base, and uses retrieval-augmented generation to provide resolutions, reducing manual search time.
- Data security and access controls rely on AWS services such as IAM, KMS, Secrets Manager, TLS, CloudTrail, and OpenSearch Serverless with role-based access.
- The architecture uses AWS Step Functions, Lambda, S3, DynamoDB, and a Streamlit frontend to deliver a production-ready experience with time-tracking and QoS metrics.
Context and background
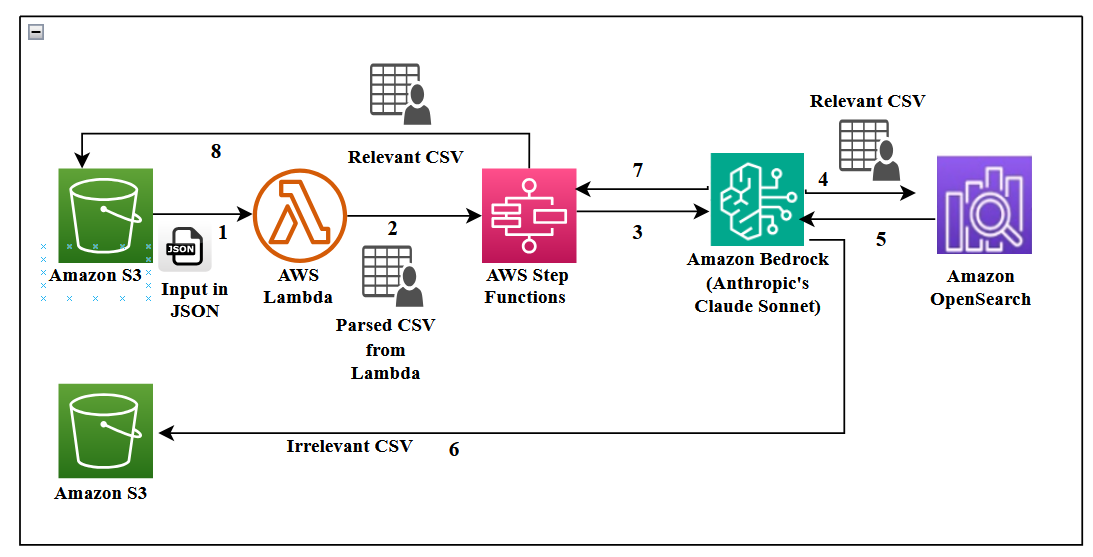
A large energy supplier relies on a technical help desk where agents address customer calls and support field technicians who install, exchange, service, and repair meters. The volume is substantial, with approximately 5,000 calls per week (about 20,000 per month). Hiring more agents and training them with the required knowledge is costly and not easily scalable. To address this, Infosys Topaz integrates with AWS Bedrock capabilities to create an AI-powered technical help desk that ingests transcripts, builds a searchable knowledge base, and offers resolutions to agents in near real time. The goal is to reduce call handling times, automate repetitive tasks, and improve overall support quality. The solution emphasizes tight integration with AWS services for data flow and management within a single cloud system, including Step Functions, DynamoDB, and OpenSearch Service. AWS blog Conversations are recorded for quality and analysis purposes. Transcripts are stored in JSON format in an S3 bucket, then parsed and processed to create a knowledge base that the AI assistant can query. The system highlights the importance of role-based access control and secure data handling, particularly for PII. The architecture demonstrates an end-to-end workflow from raw transcripts to an interactive UI used by support agents. The approach also covers metrics such as sentiment, tone, response quality, and user satisfaction.
What’s new
The implementation combines Infosys Topaz with Amazon Bedrock, including Anthropic’s Claude Sonnet as the LLM for summarization and context assessment. Titan Text Embeddings on Bedrock are used to power efficient retrieval for RAG (Retrieval-Augmented Generation) through an OpenSearch Serverless vector store. Key design choices include chunking transcripts into 1,000-token blocks with a 150–200 token overlap to optimize retrieval quality. An event-driven AWS Lambda function triggers a Step Functions workflow whenever new transcripts are loaded into S3. The raw transcripts are converted to a CSV for filtering (fields include a unique contact ID, speaker role, and content). The pipeline ingests CSV files via Step Functions to build the knowledge base. Irrelevant conversations are discarded, while relevant ones feed the embedding process. A notable architectural element is the OpenSearch Serverless vector store, which supports near real-time updates of embeddings for fast retrieval. The system uses a vector engine capable of adding, updating, and deleting embeddings without harming query performance. A production-ready RAG setup relies on a robust vector store and a suitable embedding model to retrieve the most contextually relevant information. Security and governance are integral: AWS Secrets Manager protects credentials, with automatic rotation; S3 uses AES-256 encryption via AWS KMS, and versioning is enabled for audit trails. PII data is encrypted with strict IAM controls and AWS KMS policies. OpenSearch Serverless data is encrypted at rest (KMS) and in transit (TLS 1.2). Access control is granular and audited via AWS CloudTrail. Access is organized around three personas—administrator (full access), technical desk analyst (medium access), and technical agent (minimal access)—with separate OpenSearch collections per transcript type to enforce content permissions. A Streamlit-based frontend provides a UI with an FAQ section and a search metrics insights panel. The UI uses authenticate.login to obtain a user ID and st.cache_data() to cache results for faster responses. The result set is augmented with sentiment, tone, and satisfaction metrics to inform improvements.
Why it matters (impact for developers/enterprises)
This implementation demonstrates how to operationalize a generative AI solution that complements human agents rather than replacing them. By building a knowledge base from real transcripts and using a robust vector search (RAG), organizations can shorten call handling times, standardize resolutions, and scale support without proportionally increasing headcount. The architecture showcases how Bedrock integrates with core AWS services to deliver end-to-end data flow, secure handling of sensitive information, and auditable governance. For enterprises, this pattern highlights practical steps for deploying enterprise-friendly AI assistants in customer care, CRM, and help desks while maintaining compliance and security standards.
Technical details or Implementation
The architecture begins with call transcripts recorded by agents and meter technicians. Transcripts are stored in S3 as JSON and subsequently parsed into CSV for structured processing. The CSV includes fields such as a unique contact ID, the speaker, and the conversation content. Step Functions orchestrate a data ingestion workflow that transforms raw transcripts into a production-ready knowledge base. The embedding and retrieval layer leverages Titan Text Embeddings for text vectorization and OpenSearch Serverless for vector storage and search, enabling Retrieval-Augmented Generation with an LLM (Anthropic Claude Sonnet on Amazon Bedrock) to summarize conversations and identify contextually relevant information. A core aspect is the chunking strategy: 1,000-token chunks with an overlap of 150–200 tokens, coupled with sentence window retrieval, to maximize retrieval quality without processing vast documents at once. The system uses Streamlit as the frontend framework, with a simple authentication mechanism (authenticate.login) to assign user IDs. The UI presents an FAQ section and a side panel with metrics insights, including sentiment, tone, and satisfaction percentages. Results are cached via st.cache_data() to improve performance across user sessions. From a security perspective, the solution relies on AWS Secrets Manager for credential storage, KMS for encryption at rest, TLS 1.2 for data in transit, and CloudTrail for auditing. Access is controlled through IAM policies and a middleware layer that reads ACL data from DynamoDB, with per-collection access enforced by OpenSearch Serverless collections. Three personas define access levels: administrator, technical desk analyst, and technical agent. This RBAC approach is supported by role-based collections and a DynamoDB-backed user/role mapping, ensuring that only authorized users can view sensitive transcripts. The system also demonstrates how a production-ready caching strategy and a dynamic FAQ counter (top five FAQs) can improve user experience and response times.
Key takeaways
- Real-world AI for help desks is viable when backed by a strong data ingestion and retrieval framework.
- Bedrock-based LLMs (Claude Sonnet) and Titan Embeddings enable effective retrieval-augmented generation over operational transcripts.
- End-to-end security, encryption, and auditable governance are essential for handling customer data and PII in enterprise AI applications.
- A combination of Step Functions, Lambda, S3, and OpenSearch Serverless provides scalable orchestration, storage, and fast retrieval for production use.
- Role-based access control across multiple personas ensures that sensitive data remains protected while enabling efficient support workflows.
FAQ
-
What problem does this solution aim to solve?
It reduces call handling times and automates repetitive tasks by building a knowledge base from past transcripts and providing context-aware AI resolutions to support agents.
-
Which AI components are used?
Anthropic’s Claude Sonnet on Amazon Bedrock for summarization and context analysis, and Titan Text Embeddings on Bedrock for vector search and Retrieval-Augmented Generation (RAG).
-
How is data security and access handled?
Data is encrypted at rest with AWS KMS and in transit with TLS 1.2; Secrets Manager protects credentials; access is controlled by IAM policies and a granular RBAC model with OpenSearch Serverless collections and CloudTrail auditing.
-
How is access control implemented?
Three personas (administrator, technical desk analyst, technical agent) define distinct access levels, with per-collection permissions and a DynamoDB-backed user/role mapping.
References
More news

Shadow Leak shows how ChatGPT agents can exfiltrate Gmail data via prompt injection
Security researchers demonstrated a prompt-injection attack called Shadow Leak that leveraged ChatGPT’s Deep Research to covertly extract data from a Gmail inbox. OpenAI patched the flaw; the case highlights risks of agentic AI.

Move AI agents from proof of concept to production with Amazon Bedrock AgentCore
A detailed look at how Amazon Bedrock AgentCore helps transition agent-based AI applications from experimental proof of concept to enterprise-grade production systems, preserving security, memory, observability, and scalable tool management.

Prompting for precision with Stability AI Image Services in Amazon Bedrock
Amazon Bedrock now offers Stability AI Image Services, extending Stable Diffusion and Stable Image with nine tools for precise image creation and editing. Learn prompting best practices for enterprise use.

Monitor Amazon Bedrock batch inference using Amazon CloudWatch metrics
Learn how to monitor and optimize Amazon Bedrock batch inference jobs with CloudWatch metrics, alarms, and dashboards to improve performance, cost efficiency, and operational oversight.

Scale visual production using Stability AI Image Services in Amazon Bedrock
Stability AI Image Services are now available in Amazon Bedrock, delivering ready-to-use media editing via the Bedrock API and expanding on Stable Diffusion models already in Bedrock.

Use AWS Deep Learning Containers with Amazon SageMaker AI managed MLflow
Explore how AWS Deep Learning Containers (DLCs) integrate with SageMaker AI managed MLflow to balance infrastructure control and robust ML governance. A TensorFlow abalone age prediction workflow demonstrates end-to-end tracking, model governance, and deployment traceability.