Benchmarking document information localization with Amazon Nova Pro on Bedrock
Sources: https://aws.amazon.com/blogs/machine-learning/benchmarking-document-information-localization-with-amazon-nova, aws.amazon.com
TL;DR
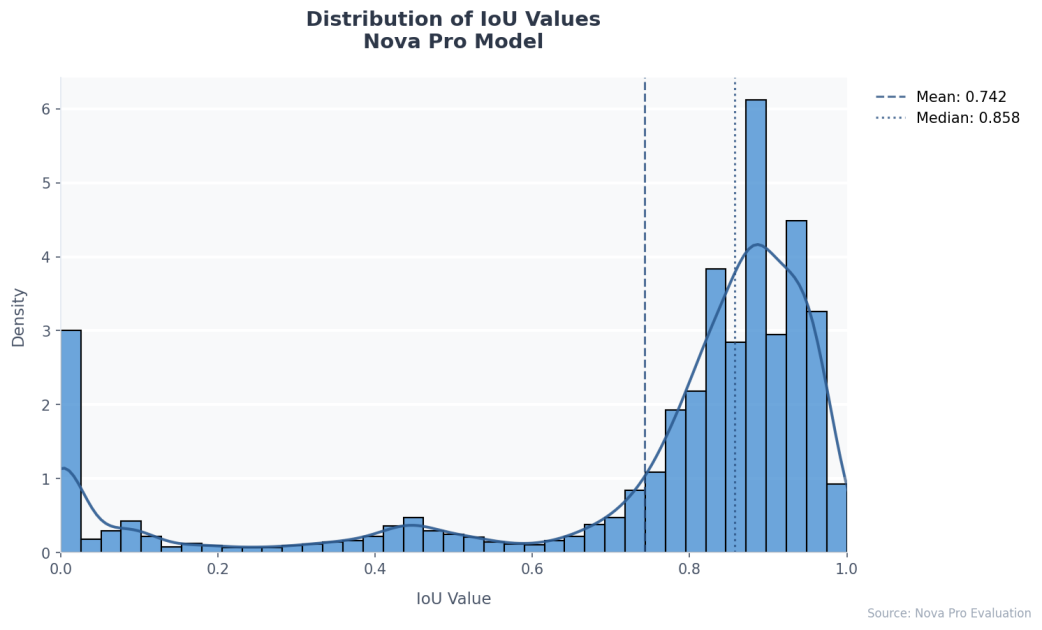
- Benchmark shows Amazon Nova Pro on Amazon Bedrock localizes document fields with a mean average precision (mAP) of 0.8305 on FATURA invoices.
- Scaled coordinate prompting was identified as the optimal strategy for Nova models in this workflow.
- The solution delivers robust localization for common fields (e.g., invoice numbers, dates) and remains resilient to currency format variations, with some processing failures attributed to guardrails and JSON issues.
- The approach emphasizes a modular design, configurable field schemas, and enterprise-scale deployment via Bedrock.
- Detailed results and guidance are provided, with code available in the authors’ GitHub repository and recommendations to review Amazon Bedrock docs for latest capabilities.
Context and background
Document processing today combines OCR with vision and language understanding to locate and interpret critical fields within documents such as invoices, forms, and contracts. Traditional object-detection approaches required substantial training data, bespoke architectures, and ongoing maintenance. Multimodal large language models (LLMs) offer a new paradigm by unifying visual layout understanding with natural language processing, enabling localization that identifies where information resides, not only what text appears. In this study, the authors demonstrate how foundation models available on Amazon Bedrock, specifically Amazon Nova Pro, can achieve high-accuracy document field localization with substantially reduced frontend and pipeline complexity. The benchmarking work emphasizes how localization, when paired with LLMs, can simplify workflows from automated checks and redaction to document comparison and validation. https://aws.amazon.com/blogs/machine-learning/benchmarking-document-information-localization-with-amazon-nova Document information localization goes beyond OCR by locating the precise spatial position of information within documents. This capability changes how organizations approach scalable document processing, reducing the need for tailor-made computer vision systems for every document type. The study frames the discussion around multimodal models with localization capabilities on Amazon Bedrock, highlighting the potential to implement robust localization with lower technical overhead and greater adaptability to new document formats. We designed a simple localization solution that takes a document image and a text prompt as input, processes it through selected foundation models on Amazon Bedrock, and returns field locations using either absolute or normalized coordinates. The design is modular to support easy extension for custom field schemas via configuration rather than code changes, aligning with enterprise needs for scalable, maintainable workflows.
What’s new
- The benchmarking leveraged FATURA, a public invoice dataset with 10,000 single-page invoices, 50 distinct layout templates, and 24 annotated fields per document. The dataset provides both text values and precise bounding box coordinates in JSON format, enabling robust evaluation of field localization.
- The evaluation compared two prompt strategies—image dimension and scaled coordinate—and, based on initial experiments, adopted the scaled coordinate approach for Amazon Nova models due to its favorable performance characteristics.
- Evaluation used standard metrics, including Intersection over Union (IoU) with a 0.5 threshold and a 5% margin tolerance for field positioning. Nova Pro achieved a mean Average Precision (mAP) of 0.8305, with 45 of 50 templates scoring above 0.80 and the lowest template-specific mAP at 0.665.
- The results show strong performance for locating structured fields such as invoice numbers and dates and robustness to currency format variations, indicating practical applicability across invoices from different sources or regions.
- The study notes processing challenges, including 170 failures out of 10,000 images, largely due to guardrail refusals and malformed JSON output, or misclassifications like confusing buyer versus seller addresses. These insights point to real-world considerations for deployment and error handling.
- The authors highlight a modular solution architecture that can be extended to additional field schemas through configuration updates and point to a complete codebase on their GitHub repository, along with guidance to review Amazon Bedrock documentation for up-to-date model capabilities.
Why it matters (impact for developers/enterprises)
- Reduced technical overhead: Multimodal models with localization capabilities simplify the traditional need for bespoke computer vision pipelines to locate document fields. This reduces maintenance burden and accelerates deployment across new document types.
- Consistent, scalable performance: The Nova Pro model demonstrated robust accuracy across diverse invoice layouts, supporting automated processing pipelines in enterprises with large document volumes.
- Field-level precision: Localization provides the spatial context needed for downstream workflows such as automated quality checks, redaction, and multi-document comparisons, enabling more reliable automation.
- Flexible deployment and extension: The modular design supports custom field schemas via configuration, enabling organizations to tailor the localization layer without rewriting code.
- Practical benchmarks and guidance: The FATURA-based results offer concrete expectations on accuracy, failure modes, and handling of real-world variations, helping teams plan deployments with realistic SLAs.
Technical details or Implementation
- Architecture: A simple localization solution takes a document image and a text prompt, processes them with chosen foundation models on Amazon Bedrock, and returns the field locations in absolute or normalized coordinates. The approach is designed to be modular, allowing easy extension to support additional field schemas via configuration updates rather than code changes.
- Prompting strategies: The workflow tests two prompting strategies—image dimension and scaled coordinate. Based on initial results, the scaled coordinate strategy was selected for Nova models due to favorable performance characteristics in the study.
- Evaluation framework: The benchmarking uses standard document-understanding metrics, including IoU with a 0.5 threshold and a 5% tolerance for field positioning, across 50 distinct invoice templates. The FATURA dataset comprises 10,000 invoices, 50 templates, 200 invoices per template, and 24 annotated fields per document, with bounding box coordinates provided in JSON. The prompts and outputs are designed to yield coordinates that can be consumed by downstream extraction and validation stages. For the full workflow and results, refer to the AWS post linked above.
- Performance and failure modes: Nova Pro achieved a mAP of 0.8305. It maintained mAP above 0.80 for 45 of 50 templates, with a template-specific minimum of 0.665. Field localization excelled for structured fields like invoice numbers and dates and showed resilience to currency format variations. Processing failures (170/10,000) were mainly due to guardrail over-refusal and malformed JSON outputs, or misclassifications such as confusing buyer versus seller addresses. These insights inform practical error handling and guardrail tuning in production.
- Availability and guidance: The study emphasizes Bedrock’s scalability for enterprise deployment and directs readers to review the Amazon Bedrock documentation for the latest model capabilities and best practices. The authors also point to a GitHub repository for the complete solution code and implementation details.
Key takeaways
- Multimodal foundation models on Bedrock can localize document fields with high accuracy, reducing reliance on traditional vision-centric pipelines.
- The scaled coordinate prompting strategy can be effective for field localization tasks in Nova Pro workflows.
- FATURA benchmarking demonstrates strong performance across varied invoice layouts, with clear guidance on expected accuracy and failure modes.
- A modular, configurable design supports enterprise-scale deployment and easy extension to new document schemas.
- Real-world deployment requires robust handling of guardrail outputs and JSON formatting to minimize processing failures.
FAQ
-
What dataset was used for benchmarking?
The FATURA dataset, consisting of 10,000 single-page invoices, 50 layout templates, 200 invoices per template, and 24 annotated fields with bounding boxes in JSON format.
-
Which model and platform were used for localization?
mazon Nova Pro running on Amazon Bedrock.
-
What prompting strategy was found to be effective?
The scaled coordinate prompting strategy was selected based on initial experiments for Nova models in this workflow.
-
What were the main causes of processing failures?
Guardrail over-refusals, malformed JSON output, and misclassifications such as confusion between buyer and seller addresses.
-
Where can developers find the implementation details?
The complete solution code is available in the authors’ GitHub repository, and readers are encouraged to review the Amazon Bedrock documentation for current capabilities.
References
- Benchmarking document localization with Amazon Nova on Bedrock: https://aws.amazon.com/blogs/machine-learning/benchmarking-document-information-localization-with-amazon-nova
More news

Move AI agents from proof of concept to production with Amazon Bedrock AgentCore
A detailed look at how Amazon Bedrock AgentCore helps transition agent-based AI applications from experimental proof of concept to enterprise-grade production systems, preserving security, memory, observability, and scalable tool management.

Prompting for precision with Stability AI Image Services in Amazon Bedrock
Amazon Bedrock now offers Stability AI Image Services, extending Stable Diffusion and Stable Image with nine tools for precise image creation and editing. Learn prompting best practices for enterprise use.

Monitor Amazon Bedrock batch inference using Amazon CloudWatch metrics
Learn how to monitor and optimize Amazon Bedrock batch inference jobs with CloudWatch metrics, alarms, and dashboards to improve performance, cost efficiency, and operational oversight.

Scale visual production using Stability AI Image Services in Amazon Bedrock
Stability AI Image Services are now available in Amazon Bedrock, delivering ready-to-use media editing via the Bedrock API and expanding on Stable Diffusion models already in Bedrock.

Use AWS Deep Learning Containers with Amazon SageMaker AI managed MLflow
Explore how AWS Deep Learning Containers (DLCs) integrate with SageMaker AI managed MLflow to balance infrastructure control and robust ML governance. A TensorFlow abalone age prediction workflow demonstrates end-to-end tracking, model governance, and deployment traceability.

Build Agentic Workflows with OpenAI GPT OSS on SageMaker AI and Bedrock AgentCore
An end-to-end look at deploying OpenAI GPT OSS models on SageMaker AI and Bedrock AgentCore to power a multi-agent stock analyzer with LangGraph, including 4-bit MXFP4 quantization, serverless orchestration, and scalable inference.