Optimizing Salesforce model endpoints with Amazon SageMaker AI inference components
Sources: https://aws.amazon.com/blogs/machine-learning/optimizing-salesforces-model-endpoints-with-amazon-sagemaker-ai-inference-components, aws.amazon.com
TL;DR
- Salesforce used Amazon SageMaker AI inference components to host multiple foundation models on a single endpoint with per-model resource controls (accelerators and memory).
- Inference components enable dynamic scaling across models, improving GPU utilization and reducing infrastructure costs.
- A hybrid deployment combined SMEs for predictable workloads with inference components for variable workloads, yielding substantial cost reductions and better resource packing.
- Salesforce moved from solely high-end multi-GPU setups to a flexible architecture that accommodates both large, low-traffic models and medium, high-traffic models, with plans to leverage newer GPU generations.
- Reports indicate substantial cost savings, including up to an eight-fold reduction in deployment and infrastructure costs.
Context and background
The Salesforce AI Platform Model Serving team focuses on onboarding models, hosting infrastructure, and enabling efficient inference for large language models (LLMs) and other AI workloads within Salesforce. Their work supports applications like Agentforce and other inference-driven features, aiming to streamline deployment, enhance inference performance, and optimize cost efficiency. In collaboration with AWS, Salesforce began integrating SageMaker AI inference components to manage and optimize GPU usage across a portfolio of models, including proprietary models such as CodeGen and XGen. Salesforce operates a mix of model sizes, ranging from a few gigabytes up to about 30 GB, distributed across multiple single-model endpoints (SMEs). Today, Salesforce runs large models (20–30 GB) on high-performance GPUs to meet relatively low-traffic patterns, which can lead to underutilized multi-GPU instances. Medium-sized models (around 15 GB) face high-traffic workloads requiring low latency and high throughput, but can incur higher costs due to over-provisioning on similar hardware. The company previously relied on Amazon EC2 P4d instances and planned to adopt the newer P5en generation with NVIDIA H200 Tensor Core GPUs. The challenge was to maximize GPU utilization, balance performance with cost, and provide a scalable foundation for evolving AI initiatives. Salesforce’s goal was to deploy models efficiently, reliably, and cost-effectively while maintaining strong performance for customers.
What’s new
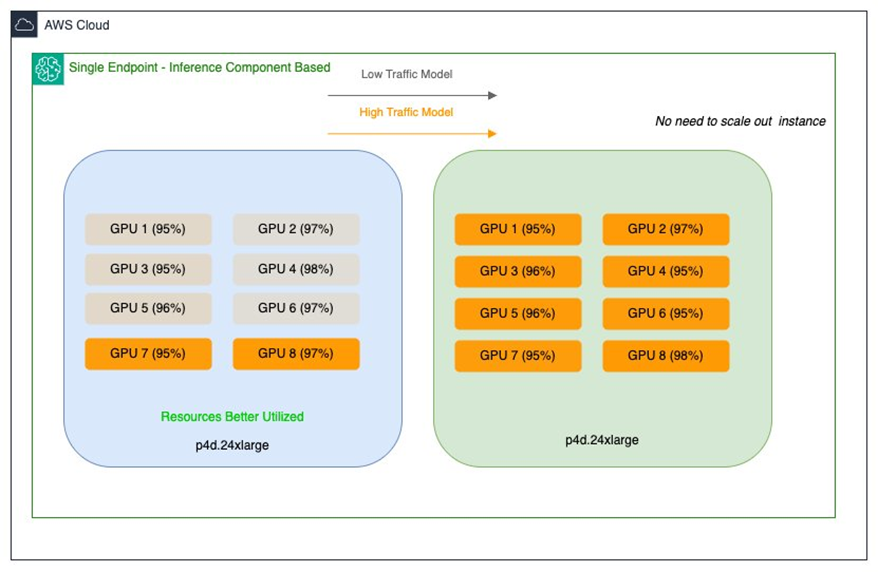
The Salesforce AI Platform team adopted SageMaker AI inference components to address these challenges. Inference components let you deploy one or more foundation models on the same SageMaker AI endpoint and allocate resources at the model level—specifying the number of accelerators and the memory reserved for each copy of a model, along with artifacts, container images, and the number of model copies to deploy. This enables multiple models to share GPUs on a single endpoint, improving resource utilization and reducing deployment costs. Each foundation model can also have its own scaling policy, enabling more granular control aligned with usage patterns. As Salesforce explains, inference components abstract ML models and allow per-model CPU/GPU assignments and scaling policies. The endpoint is created with an initial instance type and count, and models are attached dynamically as inference components. For example, BlockGen and TextEval can be configured as separate components with precise allocations, including accelerator counts, memory requirements, model artifacts, container image, and the number of copies to deploy. With auto scaling, the number of copies and GPU resources can be adjusted automatically as traffic changes. When managed instance auto scaling is enabled, SageMaker AI scales compute instances based on the number of inference components loaded at a given time, optimizing for cost while preserving model performance. Salesforce’s approach combines inference components with existing SMEs to expand hosting options without compromising stability or usability. SMEs provide dedicated hosting for individual models and predictable performance for workloads with steady traffic, while inference components optimize resource utilization for variable workloads through dynamic scaling and efficient GPU sharing. This hybrid strategy allows multiple models to reside on one endpoint and automatically adapt capacity to traffic, reducing costs associated with traffic spikes and improving overall efficiency. An illustration in Salesforce’s implementation shows large and medium SageMaker endpoints after applying inference components: multiple models can share GPU resources, while maintaining per-model control and scaling behavior. The result is a more efficient use of high-performance GPUs and a reduction in operational overhead due to fewer endpoints to manage.
Why it matters (impact for developers/enterprises)
The key impact is a notable improvement in resource efficiency and substantial cost savings without sacrificing performance for AI workloads. By refining GPU allocation at the model level, inference components enable smarter packing and dynamic resource allocation. This allows Salesforce to deploy smaller models on high-end GPUs to achieve high throughput and low latency, while avoiding the typical cost overhead of provisioning large, underutilized hardware. The approach supports a broad portfolio of models, from large proprietary LLMs to smaller, high-traffic variants, and provides a scalable foundation for future AI initiatives. The ability to run multiple models on a single endpoint with per-model resource controls reduces the number of endpoints to manage and simplifies operations, which is particularly valuable for organizations operating at scale. From a strategic perspective, the combination of SME stability and inference-component efficiency offers a balanced path to scale AI infrastructure. It preserves performance where it matters most while enabling cost-effective handling of fluctuating workloads. Salesforce’s experience suggests that intelligent model packing and per-model scaling policies are central to achieving significant cost reductions and improved utilization of expensive GPUs.
Technical details or Implementation
Key architectural choices include deploying multiple foundational models (FMs) on a single SageMaker AI endpoint, with explicit per-model allocations for accelerators and memory. The process begins by creating a SageMaker AI endpoint with a baseline instance type and initial instance count. Model packages are attached dynamically as inference components, each configured with:
- Number of accelerators per model copy
- Amount of memory per model copy
- Model artifacts location and container image
- The number of model copies to deploy Inference components can scale up or down the number of copies based on traffic, using auto-scaling policies. SageMaker AI handles the packing and placement to optimize for availability and cost. If managed instance auto scaling is enabled, SageMaker AI adjusts compute instances to meet the number of inference components needed at any given time, balancing performance with cost efficiency. Salesforce’s hybrid deployment strategy leverages both SMEs and inference components. SMEs deliver predictable performance for critical workloads with stable traffic, while inference components optimize resource utilization for variable workloads through dynamic scaling and GPU sharing. This arrangement enables hosting multiple model variants on the same endpoint, each with its own resource allocation and scaling behavior, while preserving overall endpoint stability. Implementation highlights include:
- Starting with an endpoint configured for baseline inference needs, then attaching models as individual inference components.
- Defining model-specific resources (accelerators, memory) and deployment copies per component.
- Enabling per-model scaling policies to respond to usage patterns and maintain desired performance.
- Allowing automatic GPU resource adjustment as traffic fluctuates, reducing costs during spikes and underutilization periods. 实践表明,这种方法使 Salesforce 能够在同一端点上高效托管多种模型,同时实现对资源的细粒度控制和灵活扩展。In English, Salesforce notes that this capability enables consolidation of workloads, reduces the number of endpoints, and improves overall cost-per-transaction for AI inference.
Table: SMEs vs Inference Components (high level)
| Aspect | SMEs | Inference Components |---|---|---| | Hosting model per endpoint | Dedicated hosting for each model | Multiple models share a single endpoint |Resource isolation | Strong, model-level isolation | Per-model accelerators and memory allocations |Scaling granularity | Often fixed per model | Per-model scaling policies with auto-scaling |Typical workload fit | Predictable, steady workloads | Variable workloads with dynamic scaling |Cost impact | Higher potential for over-provisioning | Optimized packing and cost-aware scaling | For reference, Salesforce highlights that the approach can reduce deployment and infrastructure costs by significant margins, including reports of substantial cost savings across their endpoint portfolio. This is consistent with AWS guidance on leveraging inference components to reduce model deployment costs on SageMaker.
Key takeaways
- Inference components enable deploying multiple foundation models on a single SageMaker AI endpoint with per-model resource controls.
- Auto scaling and smart packing by SageMaker AI help optimize GPU utilization and reduce costs.
- A hybrid SME + inference components strategy provides stability for critical workloads while improving efficiency for variable workloads.
- Resource allocation at the model level allows high-end GPUs to be used more efficiently, supporting both large and medium models within the same infrastructure.
- The approach can deliver substantial cost savings and more flexible AI infrastructure management for enterprises deploying complex model portfolios.
FAQ
-
What are SageMaker AI inference components?
They are a deployment construct that lets you host one or more foundation models on a single SageMaker AI endpoint, with per-model allocations of accelerators and memory, dynamic scaling, and model-specific deployment copies.
-
How do inference components differ from traditional SMEs?
SMEs provide dedicated hosting for individual models with predictable performance for steady workloads, while inference components optimize resource utilization for variable workloads through dynamic scaling and GPU sharing on a shared endpoint.
-
Can resources be adjusted automatically as traffic changes?
Yes. Inference components support auto scaling of model copies and, with managed instance auto scaling, SageMaker AI scales instances based on the number of loaded inference components.
-
What are the practical benefits Salesforce observed?
Improved GPU utilization, better resource efficiency, and substantial cost savings—up to an eight-fold reduction in deployment and infrastructure costs—without compromising performance.
-
What models were involved in this deployment?
Salesforce deployed proprietary models such as CodeGen and XGen, including ensembles like BlockGen and TextEval, using inference components alongside SMEs.
References
More news

First look at the Google Home app powered by Gemini
The Verge reports Google is updating the Google Home app to bring Gemini features, including an Ask Home search bar, a redesigned UI, and Gemini-driven controls for the home.

NVIDIA HGX B200 Reduces Embodied Carbon Emissions Intensity
NVIDIA HGX B200 lowers embodied carbon intensity by 24% vs. HGX H100, while delivering higher AI performance and energy efficiency. This article reviews the PCF-backed improvements, new hardware features, and implications for developers and enterprises.

Shadow Leak shows how ChatGPT agents can exfiltrate Gmail data via prompt injection
Security researchers demonstrated a prompt-injection attack called Shadow Leak that leveraged ChatGPT’s Deep Research to covertly extract data from a Gmail inbox. OpenAI patched the flaw; the case highlights risks of agentic AI.

Move AI agents from proof of concept to production with Amazon Bedrock AgentCore
A detailed look at how Amazon Bedrock AgentCore helps transition agent-based AI applications from experimental proof of concept to enterprise-grade production systems, preserving security, memory, observability, and scalable tool management.

Predict Extreme Weather in Minutes Without a Supercomputer: Huge Ensembles (HENS)
NVIDIA and Berkeley Lab unveil Huge Ensembles (HENS), an open-source AI tool that forecasts low-likelihood, high-impact weather events using 27,000 years of data, with ready-to-run options.

Scaleway Joins Hugging Face Inference Providers for Serverless, Low-Latency Inference
Scaleway is now a supported Inference Provider on the Hugging Face Hub, enabling serverless inference directly on model pages with JS and Python SDKs. Access popular open-weight models and enjoy scalable, low-latency AI workflows.