
GPT-5: smaller-than-expected leap, but faster, cheaper, and stronger at coding
Sources: https://www.theverge.com/openai/759755/gpt-5-failed-the-hype-test-sam-altman-openai
TL;DR
- GPT-5 launch was met with intense hype but generated mixed reactions from users and experts.
- Notable gains include lower cost, reduced latency, improved coding performance, fewer hallucinations, and a new backend switch system.
- Users criticized tone and writing quality, reported unexpected factual errors, and some emotional-support users found the model colder.
- OpenAI emphasized real-world utility and affordability; some legacy models were temporarily restored amid feedback.
Context and background
Expectations for GPT-5 had been building since the 2023 release of GPT-4. In advance of the launch, OpenAI and its leadership amplified anticipation: CEO Sam Altman described GPT-5 as ‘something that I just don’t wanna ever have to go back from’, likening it to a meaningful milestone. A preannouncement post that used an image of the Death Star further raised public expectations, and commentary on social platforms compared the atmosphere to major product moments. Community interest had been high for months. In a Reddit AMA the previous October, users repeatedly asked about GPT-5 and its features. Altman cited compute limits as a reason for the longer timetable, saying that models had become complex and the team could not ship as many things in parallel as they would like. The release day therefore came with unusually heightened scrutiny from both general users and AI experts. For reporting and context, see the original piece at The Verge.
What s new
GPT-5 introduced several pragmatic improvements rather than a singular, dramatic leap in general intelligence. Key announced and observed changes include:
- Reduced cost and latency, improving everyday responsiveness and affordability.
- A backend ‘switch’ system that automatically routes a query to the model variant best suited to answer it, removing the need for users to choose between models.
- Better performance on coding tasks, with at least one GPT-5 iteration topping a popular AI model leaderboard in the coding category, with Anthropic s Claude reported as runner-up.
- Improvements intended to cut hallucinations, better calibration, more frequent refusals to answer when uncertain, and clearer separation between facts and guesses, including grounding with citations when requested. OpenAI positioned GPT-5 as focused on ‘real-world utility and mass accessibility/affordability’, and internal messaging emphasized usefulness for shipping code, creative writing, and navigating health information with more steadiness and less friction.
Why it matters (impact for developers and enterprises)
The most tangible benefits for businesses and developers are practical rather than purely headline-grabbing. Incremental model improvements that reduce cost and latency can translate directly into lower operating expenses and better user experience at scale. For enterprise customers, those savings and reliability gains can be more valuable than dramatic but narrow research breakthroughs. Key enterprise implications:
- Cost and latency reductions make broader deployment more feasible for production services and large-scale workloads.
- Improved coding ability strengthens GPT-5 s value proposition for developer tooling, automated code generation, code review, and internal platforms, where companies are already willing to pay for performance gains.
- Fewer hallucinations, better calibration, and the ability to cite sources increase the model s suitability for workflows that require higher factual accuracy and traceability, such as knowledge work and certain regulated domains. However, OpenAI s healthcare claims remain largely untested in practice, and organizations should treat that use case with caution until more real-world validation is available.
Technical details or implementation
OpenAI emphasized pragmatic engineering goals in GPT-5 development. The team focused on enhancing utility and accessibility, with efforts aimed at reducing inference cost and latency. The company also introduced an automatic routing system that directs requests to the model variant most appropriate for a given task on the backend. Benchmarks and evaluation
- GPT-5 performed better than its predecessors on multiple industry tests, but many industry observers characterized the improvements as incremental rather than transformative.
- The AI coding leaderboard cited during rollout showed a GPT-5 iteration at the top for coding performance, with Anthropic s Claude in second place. Model behavior and calibration According to OpenAI researchers, GPT-5 reduces hallucinations, is better calibrated, says ‘I don t know’ more often when appropriate, and can provide citations to ground answers. These changes reflect a shift toward measured responses and reliability rather than maximally eloquent prose. Developer experience and tooling
- The switch system changes how users interact with multiple model variants by handling routing on the backend, simplifying developer and user decisions over which model to use for a task.
- Improved coding capabilities have been demonstrated in promotional examples and early user projects, with success more likely on straightforward coding tasks than on complex, glitch-prone game projects.
Key comparisons
| Area | Reported strength | Reported weakness |---|---:|---| | Cost and latency | Lower cost and reduced latency | N/A |Coding | Top of a popular coding leaderboard; strong at shipping code | Complex projects may still show glitches |Hallucinations and calibration | Fewer hallucinations; better at refusing when uncertain; can cite sources | Some factual errors observed in public examples |Writing and tone | More calibrated and utilitarian | Critics and users report loss of nuance and a colder, less eloquent voice |
Key takeaways
- GPT-5 delivered meaningful operational improvements in cost, speed, and coding performance rather than a dramatic leap in broad capabilities.
- User and expert reaction was mixed: praise for utility and coding gains, criticism for writing tone and unexpected factual errors.
- The new switch system and calibration efforts aim to improve real-world reliability and reduce friction for users and developers.
- Businesses that prioritize cost, latency, and coding productivity may find GPT-5 a compelling upgrade; other users seeking highly expressive or lyrical prose noted regression.
- Healthcare applications are highlighted by OpenAI but remain to be validated in real-world settings.
FAQ
-
Did GPT-5 meet expectations?
Reaction was mixed. Many users and experts expected a larger leap; instead, GPT-5 showed incremental benchmark gains and practical improvements in cost, latency, and coding.
-
Is GPT-5 better at coding than previous models?
Yes. At least one iteration of GPT-5 topped a prominent AI model leaderboard in the coding category, and OpenAI presented examples of coding and creative tooling in its launch.
-
Did OpenAI change models in response to feedback?
Yes. After users criticized writing quality and tone, OpenAI temporarily restored an older model (GPT-4o) in ChatGPT to address user concerns.
-
Are GPT-5 s healthcare claims proven?
Not yet. OpenAI highlighted healthcare capabilities, but practical success in clinical or production healthcare contexts remains largely untested based on reporting.
-
What are the main risks or downsides reported?
Users reported a colder writing voice, some unexpected factual errors (for example in public examples), and that certain applications like emotional support felt less empathetic.
References
- Main reporting and quotes: The Verge
More news

NVIDIA Unveils New RTX Neural Rendering, DLSS 4 and ACE AI Upgrades at Gamescom 2025
NVIDIA announced updates to DLSS 4, RTX Kit, ACE and developer tools at Gamescom 2025 — expanding neural rendering, on‑device ASR, DirectX Cooperative Vectors, GeForce NOW integrations and Unreal Engine support.

Anthropic tightens Claude usage policy, bans CBRN and high‑yield explosive assistance
Anthropic updated Claude’s usage policy to explicitly ban help developing CBRN and high‑yield explosives, tighten cybersecurity prohibitions, refine political rules, and clarify high‑risk requirements.

Build a scalable containerized web application on AWS using the MERN stack with Amazon Q Developer – Part 1
In a traditional SDLC, a lot of time is spent in the different phases researching approaches that can deliver on requirements: iterating over design changes, writing, testing and reviewing code, and configuring infrastructure. In this post, you learned about the experience and saw productivity gains
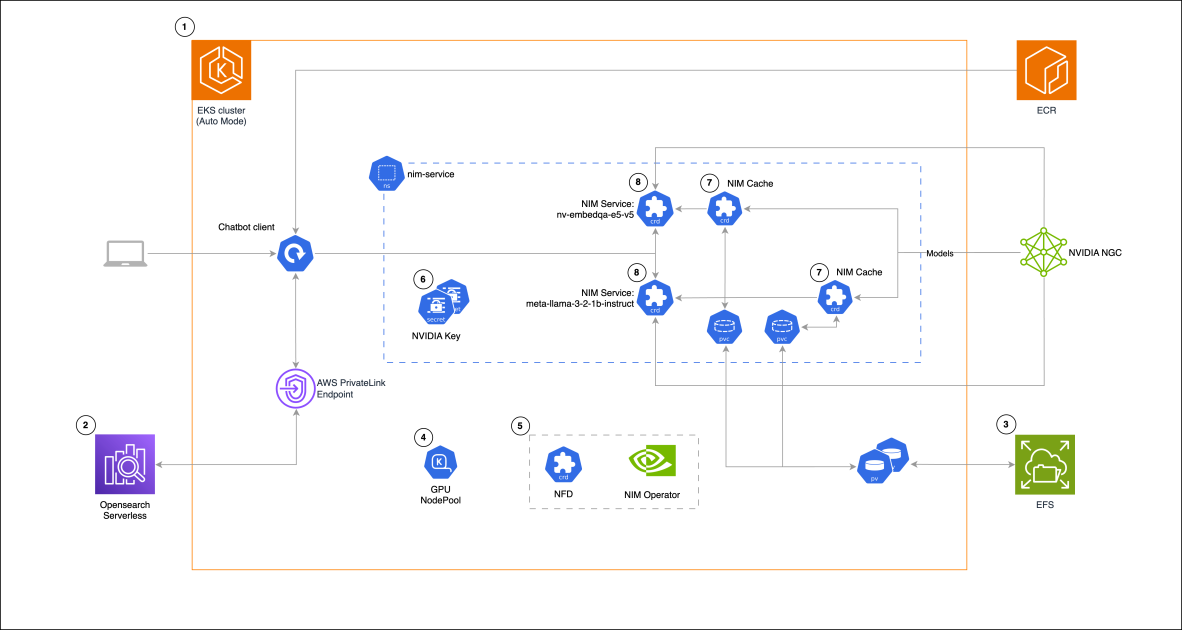
Building a RAG chat-based assistant on Amazon EKS Auto Mode and NVIDIA NIMs
In this post, we demonstrate the implementation of a practical RAG chat-based assistant using a comprehensive stack of modern technologies. The solution uses NVIDIA NIMs for both LLM inference and text embedding services, with the NIM Operator handling their deployment and management. The architectu

Sam Altman: ‘Yes,’ AI Is in a Bubble — What He Told The Verge
OpenAI CEO Sam Altman told The Verge he believes AI is in a bubble, compared it to the dot‑com era, warned about exuberant startup valuations, and said OpenAI expects massive data‑center spending.
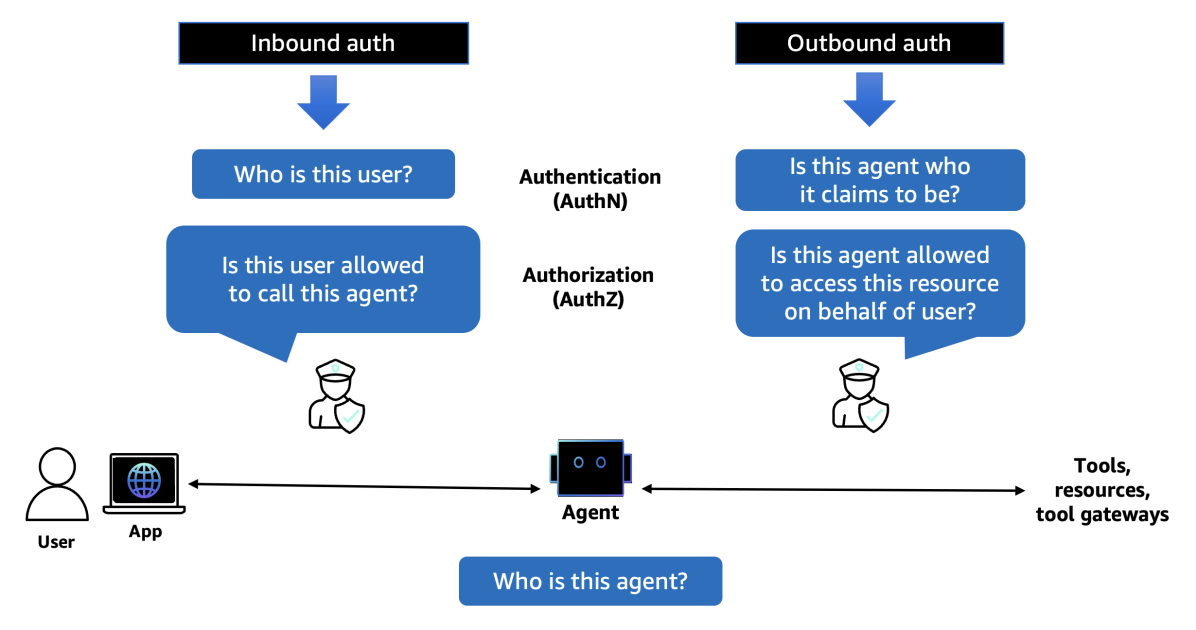
Introducing Amazon Bedrock AgentCore Identity: Securing agentic AI at scale
In this post, we explore Amazon Bedrock AgentCore Identity, a comprehensive identity and access management service purpose-built for AI agents that enables secure access to AWS resources and third-party tools. The service provides robust identity management features including agent identity director