Scalable Intelligent Document Processing with Amazon Bedrock Data Automation
Sources: https://aws.amazon.com/blogs/machine-learning/scalable-intelligent-document-processing-using-amazon-bedrock-data-automation, aws.amazon.com
TL;DR
- Amazon Bedrock Data Automation introduces confidence scoring, bounding box data, automatic classification, and rapid development through blueprints to advance IDP.
- The solution is designed to be fully serverless, using AWS Step Functions and Amazon A2I to scale workloads and enable human review when needed.
- It supports multiple document types (e.g., immunization documents, conveyance tax certificates, child support enrollment forms, driver licenses) via a single project that applies the appropriate blueprint automatically.
- Data normalization, explicit and implicit extractions, and custom transformations (like structured addresses and date formats) improve data quality and downstream integration.
- The approach reduces development time, increases data accuracy, and enables robust, scalable IDP with human-in-the-loop review when necessary. This summary reflects the AWS blog post on scalable IDP using Bedrock Data Automation and its architectural pattern for production workloads. AWS ML Blog.
Context and background
Intelligent document processing (IDP) automates extraction, analysis, and interpretation of critical information from a wide range of documents. By combining advanced machine learning and natural language processing, IDP can extract structured data from unstructured text, streamlining document-centric workflows. When augmented with generative AI, IDP gains the ability to understand, classify, and transform information with higher resilience to document variety. This capability is increasingly valuable across industries such as child support services, insurance, healthcare, financial services, and the public sector. Traditional manual processing often creates bottlenecks and increases error risk, while AI-enhanced IDP can improve service delivery, reduce administrative burdens, and accelerate decision-making. The AWS blog post Scalable intelligent document processing using Amazon Bedrock demonstrated a scalable IDP pipeline using Anthropic foundation models on Amazon Bedrock. That approach delivered robust performance, but Bedrock Data Automation brings a new level of efficiency and flexibility to IDP solutions. The article explores how Bedrock Data Automation enhancements can streamline data extraction, normalization, transformation, and validation, while integrating seamlessly with human review when needed. For readers who want to deploy the described solution, the article points to a GitHub repository with deployment steps (the post itself provides a detailed walkthrough and example use case centered on child support enrollment forms). The discussion also notes that processing multiple document types in a single project relies on automatic blueprint selection based on content analysis. This enables the correct extraction logic for each document type without manual reconfiguration. AWS ML Blog.
What’s new
Bedrock Data Automation introduces a set of capabilities that directly address IDP scalability and accuracy, complemented by a fully serverless workflow that can handle documents of varying types and sizes. The following elements are highlighted in the post:
- A fully serverless architecture that combines Bedrock Data Automation with AWS Step Functions and Amazon A2I to provide cost-effective scaling for document processing workloads of different sizes.
- A Step Functions workflow that processes multiple document types (including multipage PDFs and images) using Bedrock Data Automation blueprints—both standard and custom—within a single project.
- Content-driven blueprint selection that automatically applies the correct extraction logic for each document type, such as immunization documents, conveyance tax certificates, child support enrollment forms, and driver licenses.
- Data normalization that ensures downstream systems receive uniformly formatted data, with explicit extractions (clearly stated fields) and implicit extractions (fields requiring transformation).
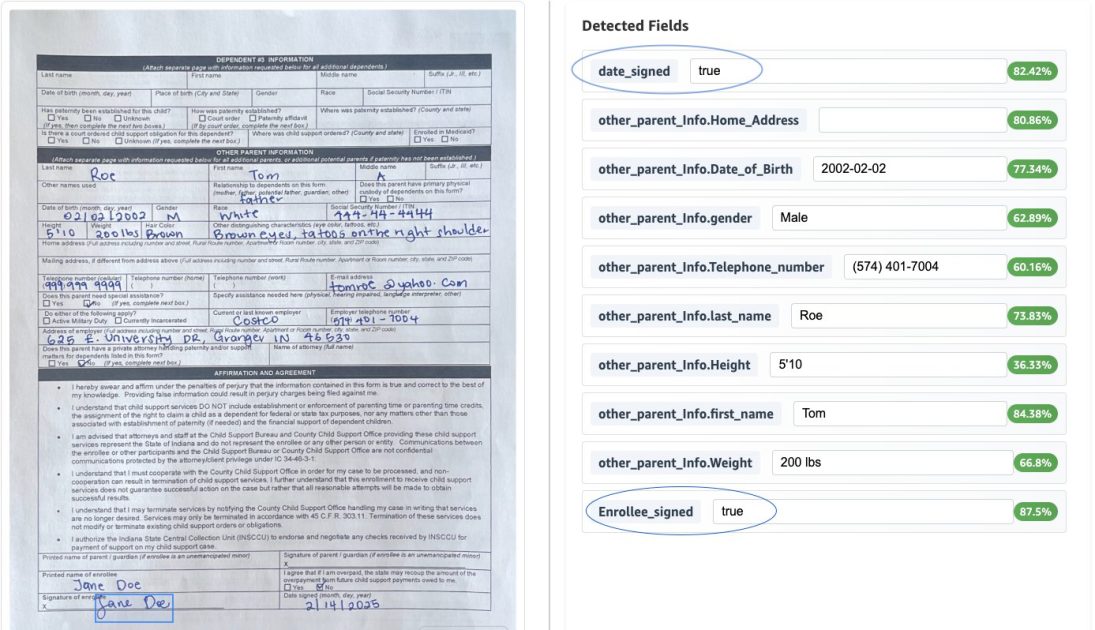
- Concrete data transformations, such as standardizing dates of birth to YYYY-MM-DD and masking Social Security Numbers as XXX-XX-XXXX. The child support enrollment form example includes a custom address data type that breaks down single-line addresses into structured fields (Street, City, State, ZipCode) to support reuse across multiple address fields (employer, home, other parent).
- Validation rules to maintain data accuracy and compliance, including verifying the presence of the enrollee’s signature and ensuring the signed date is not in the future.
- A human-in-the-loop (HITL) review process via Amazon A2I UI with bounding box highlighting for selected fields, enabling reviewers to verify extractions. After review, a callback resumes the state machine and the human-reviewed output is stored in S3.
- The initiative emphasizes confidence scoring, bounding box data, automatic classification, and rapid development through blueprints, enabling faster delivery of robust IDP solutions that can integrate with downstream systems. These features are demonstrated in the context of the child support enrollment form use case and are designed to reduce development time, improve data quality, and scale IDP solutions that incorporate human review where necessary. AWS ML Blog.
Architecture and workflow highlights
The solution showcases a serverless pipeline that leverages AWS Step Functions to orchestrate the processing of documents, with a Map state to handle multiple documents within a file. If a document’s extraction confidence surpasses a defined threshold, the results are written to an S3 bucket. Otherwise, the document is routed to Amazon A2I for human review. Upon completion, the review results are reintroduced into the state machine, and the final output is stored in S3. The approach uses a blend of standard and custom Bedrock Data Automation blueprints within a single project. This enables organizations to handle different document types with the most appropriate extraction logic, while data normalization and validation rules ensure consistent formatting and accuracy across downstream systems. A two-tier validation approach is used: explicit data (e.g., signature presence) and transformations (e.g., reformatting addresses).
Why the architecture matters
By adopting a serverless, blueprint-driven approach, organizations gain flexibility and faster iteration cycles. Bedrock Data Automation brings explicit extraction, implicit extraction through transformations, confidence scoring, and bounding box data to IDP workflows, which enhances traceability and auditability. The human-in-the-loop integration reduces risk by ensuring critical extractions are verified by domain experts when confidence is low.
Why it matters (impact for developers/enterprises)
For developers and enterprises, the Bedrock Data Automation approach offers several tangible benefits:
- Reduced development time: Prebuilt blueprints and standardized data transformations accelerate the creation of IDP pipelines, enabling teams to deliver value faster.
- Improved data quality and consistency: Data normalization and validation rules ensure downstream systems receive uniformly formatted, accurate data, reducing rework and integration friction.
- Scalable, cost-effective processing: A fully serverless architecture with Step Functions and A2I scales to workloads of varying size while maintaining cost efficiency, thanks to threshold-based processing and targeted HITL review.
- Robust accuracy with human oversight: Confidence scoring, bounding box data, and a streamlined HITL UI provide a practical balance between automation and human judgment for critical documents.
- Cross-document type handling: The system can automatically apply the correct blueprint when processing multiple document types in a single project, simplifying management and reducing maintenance overhead.
- Practical, real-world applicability: The architecture supports real-world forms such as immunization records, tax certificates, enrollment applications, and driver licenses, illustrating broad applicability across public sector and regulated environments. These outcomes align with common public-sector and enterprise objectives: faster service delivery, improved data-driven decision making, and stronger governance around regulated data. The example use case (child support enrollment forms) illustrates how customized data types and validations can be implemented to meet policy requirements while maintaining a scalable, reusable architecture. AWS ML Blog.
Technical details or Implementation
The solution centers on a serverless, blueprint-driven IDP pipeline that integrates Bedrock Data Automation with Step Functions and A2I. The following technical elements are central to the implementation:
- Document ingestion and type handling: The workflow processes files (PDF, JPG, PNG, TIFF, DOC, DOCX) that may contain a single document or multiple documents. A content-analytic step determines the appropriate blueprint to apply for extraction.
- Blueprint-driven extraction: The system uses a mix of standard and custom Bedrock Data Automation blueprints to extract data from diverse document types (e.g., immunization documents, conveyance tax certificates, child support enrollment forms, driver licenses). The architecture automatically selects the proper blueprint based on document content analysis.
- Data normalization and transformation: Downstream systems receive consistently formatted data. Explicit extractions capture clearly stated fields, while implicit extractions handle data transformations (e.g., dates to YYYY-MM-DD, SSN masking). The child support enrollment form demonstrates a custom address data type that parses single-line addresses into structured fields (Street, City, State, ZipCode), enabling reuse across multiple address fields.
- Validation and compliance: The pipeline includes validation rules to ensure data accuracy, such as verifying the enrollee’s signature and ensuring the signed date is not in the future.
- Confidence scoring and bounding boxes: Bedrock Data Automation provides confidence scores and bounding box data for extracted fields, facilitating traceability and quality control.
- Automatic classification: The system classifies documents and routes outputs accordingly, improving routing and downstream processing.
- Rapid development with blueprints: Developers can rapidly assemble IDP solutions by using predefined blueprints, reducing code and configuration effort.
- Serverless orchestration with Step Functions: A Map state enables per-document processing within a file, scaling to large or small document sets without provisioning servers.
- Human review integration with A2I: When outputs fall below the confidence threshold, documents are sent to Amazon A2I for human review via the A2I UI, which includes bounding box highlighting for selected fields. After review, a callback task resumes the state machine and stores the human-reviewed output in S3.
- Deployment and reuse: The solution is demonstrated in a fully reproducible pattern within a GitHub repository accompanying the post, enabling practitioners to deploy in their own AWS accounts and tailor blueprints to their document mix. AWS ML Blog.
Key components in a simplified flow
| Component | Role |
|---|---|
| Bedrock Data Automation | Core extraction, classification, normalization, and transformation engine. |
| AWS Step Functions | Orchestrates the workflow, including Map state for multi-document processing. |
| Amazon A2I | Human review interface for low-confidence extractions. |
| Amazon S3 | Storage for final outputs and intermediate review results. |
| Content analysis | Determines which blueprint to apply based on document content. |
| The above flow enables a scalable, auditable, and reusable approach to IDP, with the flexibility to handle multiple document types under a single project. AWS ML Blog. |
Key takeaways
- Bedrock Data Automation elevates IDP by introducing confidence scoring, bounding box data, automatic classification, and rapid blueprint-driven development.
- A serverless, orchestrated pipeline with Step Functions and A2I enables scalable, cost-effective processing and controlled human-in-the-loop review.
- Multi-document-type support within a single project simplifies maintenance and ensures the correct extraction logic is applied automatically.
- Data normalization and validation improve downstream data quality and regulatory compliance.
- The approach is demonstrated on concrete use cases such as child support enrollment forms, illustrating practical applicability across public sector workflows. AWS ML Blog.
FAQ
-
What is Amazon Bedrock Data Automation in this context?
It is a feature set that enhances IDP by providing confidence scoring, bounding box data, automatic classification, and blueprint-based data extraction, transformation, and validation flows.
-
How does the workflow scale with document volume?
The architecture is fully serverless and uses AWS Step Functions with a Map state to process multiple documents in a file, automatically routing outputs to S3 or to A2I for review when needed.
-
How are data formatting and validation handled?
The solution uses data normalization (e.g., DOB to YYYY-MM-DD, SSN masking) and custom transformations (e.g., structured addresses) along with validation rules like signature presence and date validation.
-
How does human review integrate into the pipeline?
If confidence is below the threshold, the document is sent to Amazon A2I for review via the A2I UI with bounding box highlighting; after review, the output is recommenced to the state machine and stored in S3.
References
More news

Move AI agents from proof of concept to production with Amazon Bedrock AgentCore
A detailed look at how Amazon Bedrock AgentCore helps transition agent-based AI applications from experimental proof of concept to enterprise-grade production systems, preserving security, memory, observability, and scalable tool management.

Prompting for precision with Stability AI Image Services in Amazon Bedrock
Amazon Bedrock now offers Stability AI Image Services, extending Stable Diffusion and Stable Image with nine tools for precise image creation and editing. Learn prompting best practices for enterprise use.

Monitor Amazon Bedrock batch inference using Amazon CloudWatch metrics
Learn how to monitor and optimize Amazon Bedrock batch inference jobs with CloudWatch metrics, alarms, and dashboards to improve performance, cost efficiency, and operational oversight.

Scale visual production using Stability AI Image Services in Amazon Bedrock
Stability AI Image Services are now available in Amazon Bedrock, delivering ready-to-use media editing via the Bedrock API and expanding on Stable Diffusion models already in Bedrock.

Use AWS Deep Learning Containers with Amazon SageMaker AI managed MLflow
Explore how AWS Deep Learning Containers (DLCs) integrate with SageMaker AI managed MLflow to balance infrastructure control and robust ML governance. A TensorFlow abalone age prediction workflow demonstrates end-to-end tracking, model governance, and deployment traceability.

Build Agentic Workflows with OpenAI GPT OSS on SageMaker AI and Bedrock AgentCore
An end-to-end look at deploying OpenAI GPT OSS models on SageMaker AI and Bedrock AgentCore to power a multi-agent stock analyzer with LangGraph, including 4-bit MXFP4 quantization, serverless orchestration, and scalable inference.