Amazon Bedrock AgentCore Memory: Building context-aware agents
Sources: https://aws.amazon.com/blogs/machine-learning/amazon-bedrock-agentcore-memory-building-context-aware-agents, aws.amazon.com
TL;DR
- Amazon Bedrock AgentCore Memory is a fully managed memory service for Bedrock AgentCore that maintains both short‑term and long‑term memories to sustain context across sessions.
- It eliminates the need to build custom memory infrastructure, offering built‑in storage, intelligent extraction, and efficient retrieval with encryption by default.
- The service provides memory resources, event types, namespaces, and memory strategies, including three built‑in strategies and support for custom strategies, plus advanced features like branching and checkpoints.
- It integrates with Bedrock AgentCore tools and follows an API‑first design with pre‑verified defaults to accelerate development while remaining extensible.
Context and background
AI assistants that forget what you told them aren’t very helpful. Large language models (LLMs) excel at generating human‑like responses but are fundamentally stateless; they don’t retain information between interactions. Developers have long built custom memory systems to track conversation history, remember user preferences, and maintain context across sessions, often solving the same problems across multiple applications. At the AWS Summit New York City 2025, Amazon introduced Bedrock AgentCore Memory as a service for agent memory management, designed to simplify memory infrastructure and provide explicit control over what the AI remembers. Amazon Bedrock AgentCore Memory blog This memory layer enables context‑aware agents by maintaining both immediate context within a session and persistent insights across sessions, allowing AI agents to learn from interactions and deliver truly personalized experiences. AgentCore Memory helps transform one‑off conversations into continuous, evolving relationships between users and AI agents. Rather than repeatedly asking for the same information or forgetting critical preferences, agents can maintain context and build upon prior interactions naturally. Beyond a core memory store, AgentCore Memory integrates with other Bedrock AgentCore tools so developers can enhance existing agents with persistent memory without managing complex infrastructure. It’s a fully managed offering with built‑in storage, intelligent extraction, and efficient retrieval that reduces the need for bespoke solutions built from raw storage, vector databases, session caches, and custom retrieval logic. Amazon Bedrock AgentCore Memory blog
What’s new
AgentCore Memory introduces capabilities designed to address the main memory challenges faced by AI agents:
- Memory resources with an event expiry duration (up to 365 days) to control how long raw conversation data is retained in short‑term memory. Data is encrypted in transit and at rest.
- By default, encryption uses AWS managed keys; you can enable encryption with your own customer managed KMS keys for greater control.
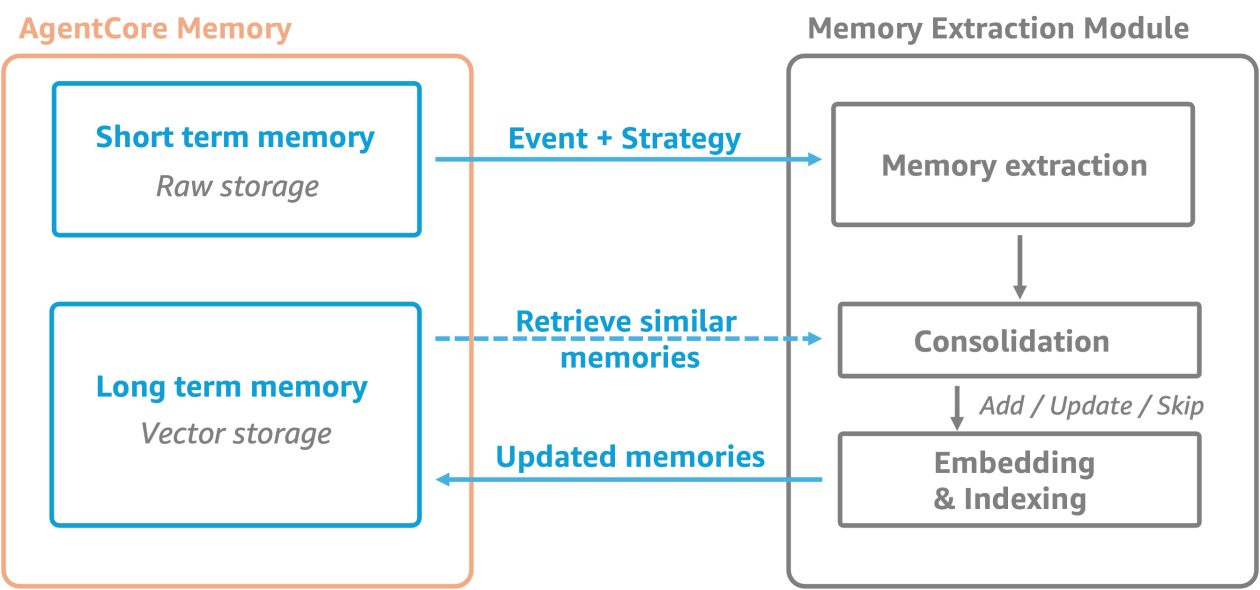
- Short‑term memory captures raw interaction data as immutable events, organized by actor and session, and stored synchronously. Events can be either “Conversational” (USER/ASSISTANT/TOOL or other message types) or “blob” (binary content used for checkpoints or agent state). Only Conversational events feed long‑term memory extraction.
- Long‑term memory stores extracted insights, preferences, and knowledge derived from raw events. Extraction happens asynchronously after events are created, using memory strategies defined for the resource.
- Namespaces provide a hierarchical structure within long‑term memory, functioning like file system paths to logically group memories. This is especially useful in multi‑tenant systems (multi‑agent, multi‑users, or both).
- Memory strategies define the intelligence layer that transforms raw events into long‑term memories. Each strategy is configured with a namespace for storage and consolidation. All strategies ignore PII data by default. There are 3 built‑in strategies defined at resource creation, and Custom memory strategies let you tailor extraction prompts to your domain.
- Branching lets agents create alternative conversation paths from a specific point in the event history by creating a new named branch within the same memory resource, using the same actor_id and session_id, with a rootEventId indicating the branch origin.
- Checkpoints let you save and mark specific states in the conversation for later reference. Checkpoints can be implemented via raw events under a different isolation (actor and session) and retrieved via the GetEvent API. Blob payloads can ingest non‑conversational data and are ignored for long‑term memory extraction, but can support checkpointing or state storage.
- The architecture combines short‑term and long‑term memory layers to provide context retention and progressive learning for agents. For developers, a practical example is available by creating a memory resource with the Boto3 client and defining the event identifiers needed to create events.
Why it matters (impact for developers/enterprises)
Memory enables more natural, coherent, and personalized interactions by preserving context across turns and sessions. Stateless LLMs can lead to repetitive prompts and higher latency and cost if memory isn’t managed effectively. AgentCore Memory reduces the burden of wiring and orchestrating memory layers, letting developers focus on business logic while the agent remembers user preferences and learns over time. This supports persistent customer profiles, streamlined support workflows, and more efficient agent orchestration across applications. By integrating with Bedrock AgentCore components, memory becomes a seamless part of the overall agent platform rather than a separate concern.
Technical details or Implementation
Memory resource and retention
A memory resource is a logical container that encapsulates both raw events and processed long‑term memories. When you create a memory resource, you can specify an event expiry duration (up to 365 days) to determine how long raw conversation data remains in short‑term memory. All data is encrypted in transit and at rest; AWS managed keys are used by default, with an option to use customer‑managed KMS keys.
Short‑term vs long‑term memory
Short‑term memory stores raw interaction data as immutable events, organized by actor and session. This organization enables precise retrieval of relevant context and reduces loading unrelated data. Events come in two types: Conversational and blob; only Conversational events participate in long‑term memory extraction. Long‑term memory contains extracted insights, preferences, and knowledge from raw events. Unlike verbatim data, long‑term memory captures meaningful information across sessions. Extraction happens asynchronously after events are created, following the configured memory strategies.
Namespaces and organization
Namespaces provide a hierarchical structure within long‑term memory, allowing logical grouping by agent, user, or use case. They function like file system paths and are especially powerful in multi‑tenant environments where several agents or users share resources. When retrieving memories, you can search within a specific namespace or use a prefix match.
Memory strategies
Strategies define how raw events are transformed into long‑term memories. Each strategy targets a particular namespace where the extracted memories are stored and consolidated. By default, strategies ignore PII data. There are 3 built‑in strategies defined at resource creation, and Custom memory strategies let you choose an LLM and override prompts for domain tailoring.
Advanced capabilities: branching and checkpoints
Branching creates alternate conversation paths within the same memory resource by adding a branch name and using the same actor_id and session_id; the branch originates from a rootEventId. Checkpoints allow saving and returning to specific states later, with retrieval via the GetEvent API. Blob events can ingest non‑conversational data and can support checkpointing or state storage, while being ignored for long‑term memory extraction.
Security and integration
Data is encrypted at rest and in transit by default, with options for customer‑managed keys to enhance control. AgentCore Memory is designed to work in concert with Bedrock AgentCore Runtime and Observability, providing a cohesive development experience without requiring separate memory infrastructure.
Architecture and design principles
The service is built around five design principles and integrates with Bedrock AgentCore components. It combines API‑first design with pre‑verified defaults so developers can quickly implement basic memory capabilities while retaining extensibility for more advanced scenarios.
Key takeaways
- AgentCore Memory provides a fully managed memory layer for AI agents, covering short‑term and long‑term memory needs.
- It reduces the need to build bespoke memory infrastructure and includes built‑in storage, extraction, and retrieval with encryption by default.
- The solution supports memory resources, event types, namespaces, and strategies, including custom strategies, with branching and checkpoints for advanced workflows.
- It’s designed to integrate with Bedrock AgentCore tools and uses an API‑first approach with sensible defaults.
- Privacy is prioritized by default, with memory strategies that ignore PII data.
FAQ
-
What is AgentCore Memory?
AgentCore Memory is a fully managed service that maintains both short‑term and long‑term memories for AI agents, enabling contextually aware interactions.
-
What is a memory resource?
It is a logical container that holds both raw events and processed long‑term memories, with configurable event expiry, security, and memory strategies.
-
How long is data retained?
You can specify an event expiry duration up to 365 days for raw data in short‑term memory.
-
How is data secured?
Data is encrypted at rest and in transit, by default with AWS managed keys, with an option to use customer‑managed KMS keys.
-
What are branching and checkpoints?
Branching creates alternate conversation paths from a starting point in the history; checkpoints save and return to specific states later, retrievable via the GetEvent API.
References
More news

First look at the Google Home app powered by Gemini
The Verge reports Google is updating the Google Home app to bring Gemini features, including an Ask Home search bar, a redesigned UI, and Gemini-driven controls for the home.

Shadow Leak shows how ChatGPT agents can exfiltrate Gmail data via prompt injection
Security researchers demonstrated a prompt-injection attack called Shadow Leak that leveraged ChatGPT’s Deep Research to covertly extract data from a Gmail inbox. OpenAI patched the flaw; the case highlights risks of agentic AI.

Move AI agents from proof of concept to production with Amazon Bedrock AgentCore
A detailed look at how Amazon Bedrock AgentCore helps transition agent-based AI applications from experimental proof of concept to enterprise-grade production systems, preserving security, memory, observability, and scalable tool management.

Predict Extreme Weather in Minutes Without a Supercomputer: Huge Ensembles (HENS)
NVIDIA and Berkeley Lab unveil Huge Ensembles (HENS), an open-source AI tool that forecasts low-likelihood, high-impact weather events using 27,000 years of data, with ready-to-run options.

Scaleway Joins Hugging Face Inference Providers for Serverless, Low-Latency Inference
Scaleway is now a supported Inference Provider on the Hugging Face Hub, enabling serverless inference directly on model pages with JS and Python SDKs. Access popular open-weight models and enjoy scalable, low-latency AI workflows.

Google expands Gemini in Chrome with cross-platform rollout and no membership fee
Gemini AI in Chrome gains access to tabs, history, and Google properties, rolling out to Mac and Windows in the US without a fee, and enabling task automation and Workspace integrations.