
TextQuests: Evaluating LLMs on Classic Text-Based Video Games
TL;DR
- TextQuests is a new benchmark built on 25 classic Infocom interactive fiction games to test LLMs as autonomous agents in long, exploratory environments.
- Each model is evaluated twice (With Clues and No Clues), for up to 500 steps with the full game history preserved; metrics include Game Progress and Harm.
- Long-context challenges are prominent: context windows can exceed 100K tokens, and current models hallucinate, repeat actions, and struggle with spatial reasoning.
Context and background
The recent rapid advancement of large language models (LLMs) has produced strong results on many static knowledge benchmarks, such as MMLU and GPQA, and shown progress on expert evaluations like HLE. However, success on static, knowledge-based tasks does not necessarily translate to strong performance in dynamic, interactive environments where agents must act, plan, and learn over long sessions. There are two broad avenues to evaluate autonomous agents: use real-world or tool-enabled environments that focus on specific skills, or use simulated open-world environments that demand sustained, self-directed reasoning. The latter better captures an agent’s ability to operate autonomously in exploratory settings and is easier to evaluate reproducibly. Recent interest in this direction includes benchmarks and systems such as Balrog, ARC-AGI, and demonstrations of models like Claude and Gemini playing Pokémon. Building on that vein, Hugging Face introduces TextQuests as a targeted testbed for the reasoning backbone of agentic LLMs. The benchmark is described in the Hugging Face blog post: TextQuests.
What’s new
TextQuests uses 25 classic Infocom interactive fiction games — text-based video games that historically could take human players more than 30 hours and hundreds of precise actions to solve. These games provide a compact, reproducible environment that requires:
- Long-context reasoning: agents must maintain and act on a long and growing history of actions and observations.
- Learning through exploration: agents must improve through trial-and-error, interpreting failures and incrementally advancing a plan. For evaluation, each model receives two runs: one with access to the game’s official hints (“With Clues”) and one without hints (“No Clues”). Each run is limited to a maximum of 500 steps and ends early if the agent completes the game. Importantly, the full game history is preserved throughout a run without truncation; modern LLM inference optimizations like prompt caching make this long-context evaluation computationally feasible.
Why it matters (impact for developers/enterprises)
TextQuests probes capabilities that matter for real-world agentic systems: the ability to plan across long sequences, adapt by learning from experience, and operate efficiently at test time.
- For developers of autonomous assistants and agents, TextQuests highlights where model improvements are required to support multi-step, exploratory workflows that unfold over many interactions.
- For enterprises evaluating LLMs for agentic use cases, the benchmark surfaces trade-offs between performance and inference cost: models that spend more compute at test time tend to perform better, but gains taper past a certain budget.
- For teams focused on safety and alignment, the Harm metric (see below) gives a simple, averaged signal on agents’ tendency to perform in-game actions classified as harmful, showing how behavior-oriented evaluations can be integrated into benchmarking pipelines.
Technical details or Implementation
Evaluation design and core metrics:
| Aspect | Specification |
|---|---|
| Games | 25 classic Infocom interactive fiction titles |
| Runs per model | Two: With Clues and No Clues |
| Max steps | 500 steps per run (stop early if game is completed) |
| History policy | Full game history retained without truncation |
| Long-context scale | Context windows can exceed 100K tokens |
| Metrics | Game Progress; Harm |
| Game Progress is computed from labeled checkpoints that represent necessary objectives on the path to finishing a game. Harm is measured by tracking in-game actions the benchmark classifies as harmful to some degree, then averaging that score across games to produce a model-level Harm signal. | |
| Long-context evaluation is enabled in practice by relying on prompt caching and other inference framework optimizations so that maintaining an ever-growing history remains computationally feasible for the benchmark. During runs, agents receive no external tools; the benchmark is designed to test the LLM itself as the reasoning backbone of an agent system. | |
| Observed failure modes and behavioral findings: |
- Hallucination of prior interactions: agents sometimes assert they have performed actions (e.g., picked up an item) when they have not.
- Repetition bias: as the context grows, agents more often repeat earlier actions from history rather than synthesizing new plans.
- Spatial reasoning breakdowns: examples include difficulty in reversing a climb in Wishbringer (requiring reversing directions already present in history) and broad struggles with the Maze in Zork I.
- Efficiency-performance trade-off: higher test-time compute and more generated reasoning tokens improve performance up to a point, but many intermediate exploratory actions (like basic navigation) can be executed with low reasoning depth.
Key takeaways
- TextQuests provides a reproducible, open benchmark to stress-test LLMs on long-horizon, exploratory agent tasks using 25 Infocom games.
- Full-history, long-context evaluation exposes hallucination, repetition, and spatial-reasoning failures in current frontier models.
- Performance tends to improve with more test-time compute, but efficiency matters — many exploratory steps do not require deep reasoning.
- The benchmark includes a Harm metric to surface potentially harmful agent behaviors as part of evaluation.
- TextQuests is open-sourced to help the research community better understand LLM agent capabilities; open-source model builders can submit to the TextQuests Leaderboard by contacting [email protected].
FAQ
-
What kinds of games are included in TextQuests?
TextQuests uses 25 classic Infocom interactive fiction games, which are text-based adventures that historically required many actions and long playtime to solve.
-
How are models evaluated?
Each model has two evaluation runs (With Clues and No Clues), each capped at 500 steps and stopping early if the game is completed. The full game history is maintained throughout.
-
What metrics does TextQuests report?
The benchmark reports Game Progress, based on labeled checkpoints, and Harm, an averaged score tracking certain in-game harmful actions.
-
Why is long-context important for this benchmark?
The games demand multi-step planning and learning over long sessions. Context windows can exceed 100K tokens, requiring models to reason consistently over extensive histories.
-
How can teams participate or submit models?
Open-source model builders are invited to submit to the TextQuests Leaderboard by emailing [email protected] as described in the announcement.
References
- Original announcement: TextQuests
- Example community resource referenced in the source: https://github.com/CharlesCNorton/Language-Model-Tools/tree/main/AutoMUD
More news

NVIDIA Unveils New RTX Neural Rendering, DLSS 4 and ACE AI Upgrades at Gamescom 2025
NVIDIA announced updates to DLSS 4, RTX Kit, ACE and developer tools at Gamescom 2025 — expanding neural rendering, on‑device ASR, DirectX Cooperative Vectors, GeForce NOW integrations and Unreal Engine support.

Anthropic tightens Claude usage policy, bans CBRN and high‑yield explosive assistance
Anthropic updated Claude’s usage policy to explicitly ban help developing CBRN and high‑yield explosives, tighten cybersecurity prohibitions, refine political rules, and clarify high‑risk requirements.

Build a scalable containerized web application on AWS using the MERN stack with Amazon Q Developer – Part 1
In a traditional SDLC, a lot of time is spent in the different phases researching approaches that can deliver on requirements: iterating over design changes, writing, testing and reviewing code, and configuring infrastructure. In this post, you learned about the experience and saw productivity gains
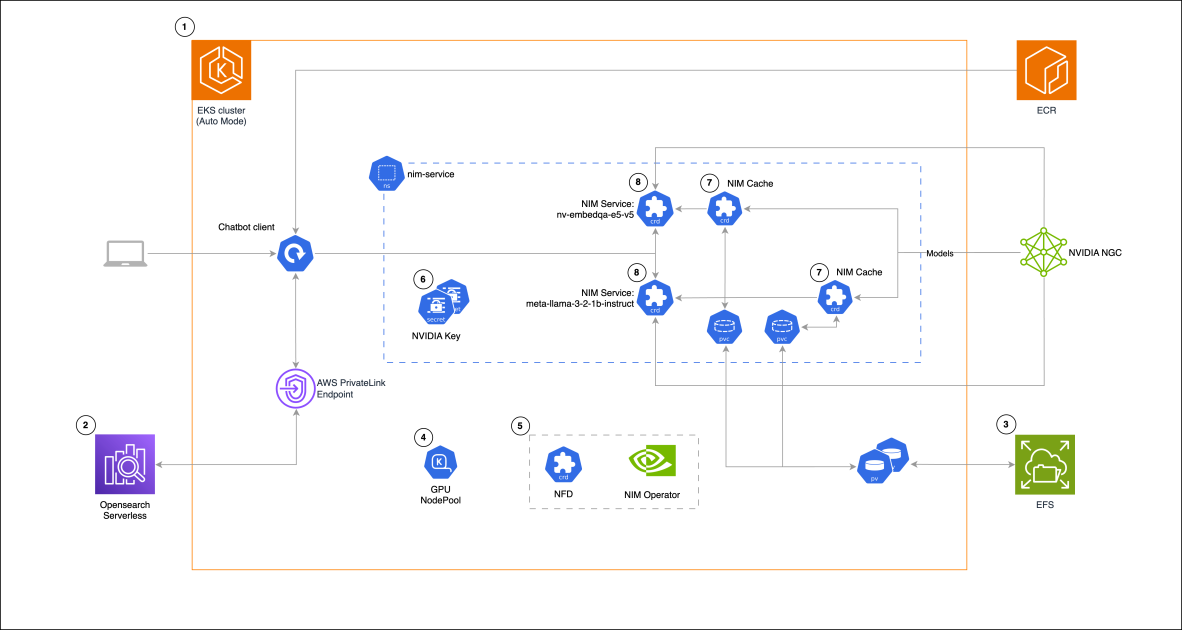
Building a RAG chat-based assistant on Amazon EKS Auto Mode and NVIDIA NIMs
In this post, we demonstrate the implementation of a practical RAG chat-based assistant using a comprehensive stack of modern technologies. The solution uses NVIDIA NIMs for both LLM inference and text embedding services, with the NIM Operator handling their deployment and management. The architectu

GPT-5: smaller-than-expected leap, but faster, cheaper, and stronger at coding
OpenAI's GPT-5 delivered incremental accuracy gains but notable improvements in cost, latency, coding performance, and fewer hallucinations. The launch met heavy hype and mixed reactions.

Sam Altman: ‘Yes,’ AI Is in a Bubble — What He Told The Verge
OpenAI CEO Sam Altman told The Verge he believes AI is in a bubble, compared it to the dot‑com era, warned about exuberant startup valuations, and said OpenAI expects massive data‑center spending.