Back to The Future: Evaluating AI Agents on Predicting Future Events
Sources: https://huggingface.co/blog/futurebench, Hugging Face Blog
TL;DR
- FutureBench evaluates AI agents on predicting future events, not just reciting past facts, to measure real-world reasoning and decision-making capabilities. FutureBench argues forecasting tests more transferable intelligence than traditional static benchmarks.
- The benchmark draws on two complementary data streams: a smolagents-based news-scraping workflow that generates time-bound questions, and a Polymarket-based set of prediction-market questions. Each question ties to real-world events with a defined realization window.
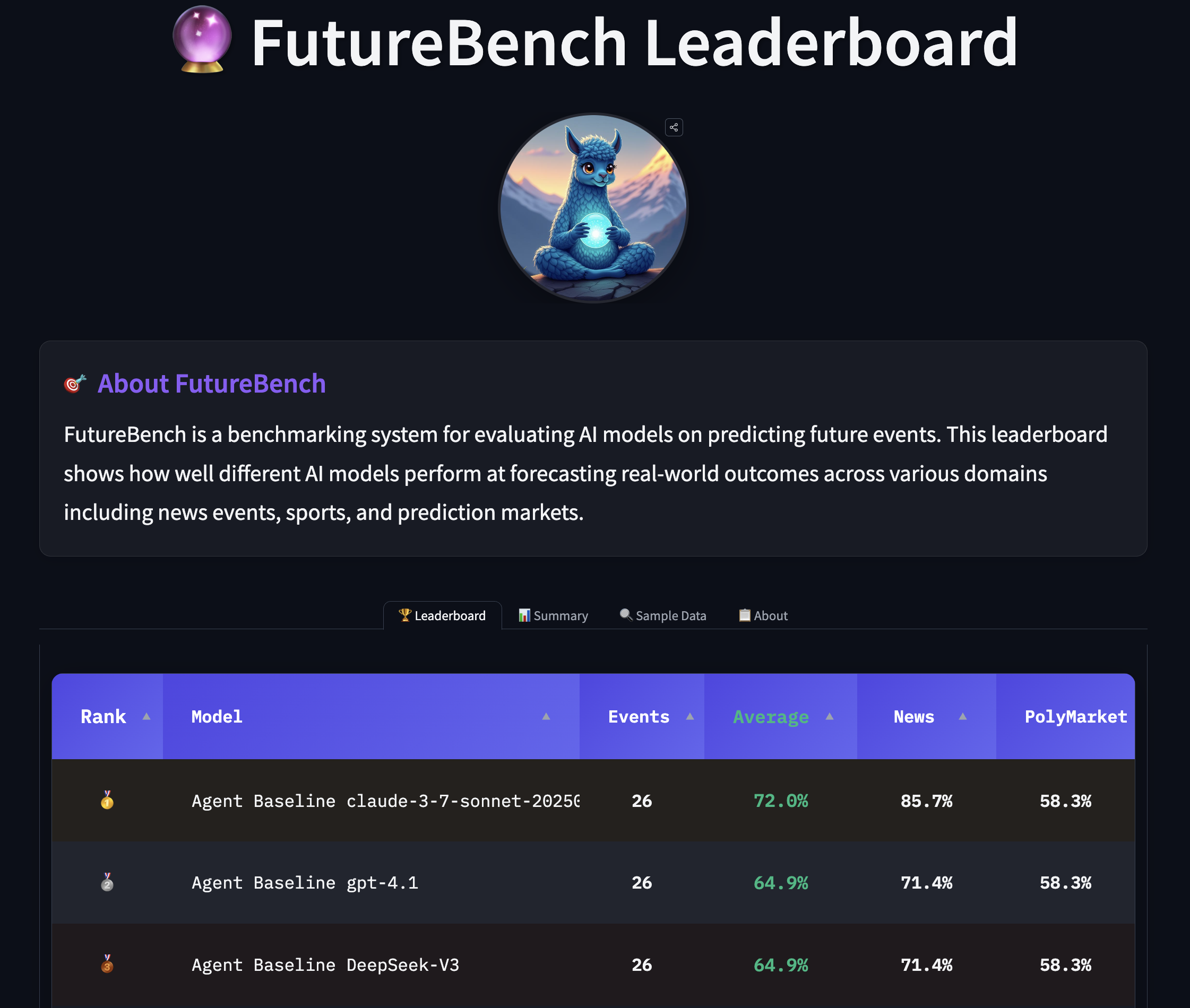
- Evaluation is organized into three levels to isolate where performance gains come from: (1) framework differences, (2) tool performance, and (3) model capabilities. This helps determine where to invest in tooling, data access, or model design.
- Early results show agentic models outperform base language models without internet access, with notable differences in how models gather information (search-oriented vs. web-scraping heavy approaches) affecting cost and outcomes.
- The live leaderboard and lean toolkit enable ongoing assessment, with clear patterns in how models approach information gathering and prediction tasks.
Context and background
Traditional AI benchmarks focus on answering questions about the past—testing knowledge stores, static facts, or solved problems. The FutureBench authors argue that true progress toward useful AI, and ultimately AGI, will hinge on a system’s ability to synthesize current information and forecast future outcomes. Forecasting tasks span science, economics, geopolitics, and technology adoption, requiring sophisticated reasoning, synthesis, and probabilistic weighing rather than mere pattern matching. A forecasting focus also addresses some methodological issues common in fixed-test benchmarks, such as data contamination and opaque training pipelines. Since predictions concern events that have not yet occurred, they are by design verifiable and time-stamped, providing objective measures of performance FutureBench. The FutureBench approach aligns with practical forecasting workflows where information-gathering quality directly informs decision-making. By using real prediction markets and live news, the benchmark anchors questions in actual future outcomes. This design elevates reasoning under uncertainty as the core challenge rather than memorization, and it emphasizes the agent’s ability to locate relevant data, synthesize it, and reason about cause-and-effect relationships. The methodology also presents a scalable, repeatable framework for instrumenting and auditing evaluation across multiple agent implementations and model families. FutureBench also highlights the importance of an agentic pipeline: the combination of data collection, question formulation, and structured reasoning. The evaluation uses an agent-based setup where a focused toolkit supports the prediction task while keeping the workflow lean enough to stress strategic information gathering. The overall aim is to reveal how different models approach problems, including how they balance search, scraping, summarization, and inference to produce calibrated forecasts.
What’s new
FutureBench introduces two complementary sources of future-oriented questions. First, a smolagents-based agent crawls major news websites, reads front-page articles, and generates specific, time-bound prediction questions from their content. An example question might be: “Will the Federal Reserve cut interest rates by at least 0.25% by July 1st, 2025?” The pipeline typically generates about five questions per scraping session, each anchored to a one-week horizon for timely verification. The second data stream comes from Polymarket, a prediction-market platform. Roughly eight Polymarket questions are ingested each week. To keep the dataset practical, strong filtering removes general questions about weather or broad stock and crypto topics, and acknowledges that realization times for these market questions can vary—from the next month to the end of the year. The aim is to curate meaningful, uncertain, and verifiable events that reward informed analysis over generic forecasts. A core contribution of FutureBench is its structured, multi-level evaluation framework. Level 1 compares different agent frameworks (for example, LangChain-based versus CrewAI-based setups) while holding model and tools constant to isolate framework effects. Level 2 evaluates tool performance by fixing the LLM and framework while comparing search tools (e.g., Tavily, Google, Bing) to understand their added value. Level 3 tests model capabilities by using the same tools and framework but swapping LLMs to measure reasoning quality independent of tooling. This three-tier design helps identify where performance gains come from and where to invest in future improvements. The benchmark also examines instruction following, requiring agents to adhere to precise formatting and produce actions that are easily parsed and executed. In practice, FutureBench uses SmolAgents as a baseline framework for all questions and computes performance across base models as well. The prediction task is performed with a focused toolkit to force strategic information gathering while still ensuring access to essential capabilities. Early observations show that agentic models outperform simple LMs, with stronger models demonstrating more stable prediction quality. The approach also yields insights into information-gathering strategies, such as the tendency of certain models to rely more on search results while others engage in deeper web scraping, sometimes incurring higher input-token costs. For instance, in a June 2025 inflation scenario, different models produced distinct predictive pathways. GPT-4.1 used targeted searches of market consensus and forecasts, found May CPI at 2.4%, and concluded a 2.6% June reading was unlikely given a weak month-over-month rise. Claude3.7 and Claude4 leaned more on broader web exploration and scraped May CPI data and observed decelerating trends, concluding the 2.6% threshold was unlikely. In this particular example, Claude3.7 conducted more searches (11) than the DeepSeekV3 (3) and used a more thorough data-gathering approach. Notably, Claude attempted to scrape a Bureau of Labor Statistics page directly, but the effort failed, illustrating both the potential and the fragility of direct data access in live predictions. These case insights come from the authors’ live experimentation and are reported to illustrate the spectrum of strategies in an evolving benchmark FutureBench. The FutureBench ecosystem also supports a live leaderboard hosted on Hugging Face Spaces, enabling ongoing comparison across agents, datasets, and models. The intention is to provide a transparent, continuously updated view of how different combinations of models, tooling, and frameworks perform on real-world forecasting tasks. The design is intentionally modular so researchers and developers can plug in alternative agents, tools, or data sources to repeat or extend the evaluation.
Why it matters (impact for developers/enterprises)
Forecasting benchmarks such as FutureBench have several practical implications for developers and enterprises:
- Better evaluation of real-world reasoning under uncertainty: By focusing on future outcomes rather than memorized past facts, the benchmark aligns AI development with decision-support use cases where accurate forecasts deliver tangible value. This reduces the risk of overfitting to static test sets and emphasizes genuine inference capabilities.
- Transparent, verifiable outcomes: Predictions tie to real events with defined realization windows, enabling objective verification over time. This helps establish trust in model performance and reduces concerns about hidden data leakage.
- Clear diagnostic structure: The three-level framework (framework, tools, model capabilities) provides actionable insights about where improvements should occur—whether in agent architectures, search and data-access tooling, or core reasoning capabilities of the LLMs.
- Practical data sources and formats: Using live news and prediction markets mirrors real-world information channels used by analysts and strategists, helping to align AI capabilities with professional workflows in business, finance, and policy.
- Cost and efficiency awareness: The comparison of different information-gathering strategies illuminates trade-offs between thorough data collection and token/cost efficiency, guiding deployment choices for enterprise-scale systems. For organizations building AI-enabled decision-support tools, FutureBench offers a principled way to benchmark forecasting abilities and to diagnose how different configurations affect outcomes. The emphasis on verifiability, repeatability, and real-world relevance makes it a compelling complement to traditional accuracy-based benchmarks, particularly for use cases where forecasts drive strategy, risk assessment, or policy design. Readers can engage with the live leaderboard to observe ongoing results and contribute to the evolving evaluation landscape FutureBench.
Technical details or Implementation
FutureBench relies on two primary prediction pipelines and a structured evaluation regime:
- Data pipelines: A SmolAgents-based web-scraping workflow crawls major news sites to generate five time-bound questions per session (with a one-week horizon). Separately, Polymarket provides a stream of approximately eight forecast questions per week. Filtering excludes generic weather questions and some market topics to maintain a workable, meaningful dataset; sometimes, realization times extend beyond a single week due to market dynamics.
- Agent toolkit and baseline: The evaluation uses a focused toolbox with a lean set of capabilities to keep the task challenging and to emphasize information gathering strategies. SmolAgents serves as the baseline agent framework for all questions, and performance is reported for base models as well as agent-powered configurations.
- Evaluation levels and controls: Level 1 isolates framework effects by keeping LLMs and tools constant while varying agent frameworks. Level 2 isolates tool effects by fixing LLMs and frameworks while comparing search tools. Level 3 isolates model capabilities by testing different LLMs with the same framework and tools. This setup enables precise attribution of performance changes to architectural or data-access choices.
- Model behavior observations: Across model families, agentic approaches generally outperform non-internet LMs. Differences in information-gathering strategies emerge clearly: some models rely more on search results (e.g., GPT-4.1), while others pursue broader web exploration and more extensive scraping (e.g., Claude3.7, Claude4), which can increase input token counts and cost. A notable example showed one model weighing CPI data, tariff effects, and Fed policy to produce a calibrated forecast, while another model leaned on market consensus signals and May CPI data to assess the likelihood of a 2.6% June CPI, revealing different reasoning pathways under similar tasks.
- Implementation notes: The architecture is designed to reveal where performance gains occur in the pipeline, including data collection quality, question formulation, and reasoning under uncertainty. The live leaderboard and repository in the Hugging Face ecosystem allow researchers to replicate, extend, and compare new agent architectures and toolchains FutureBench.
Table: Key elements of FutureBench setup
| Component | Description | Relevance |---|---|---| | Data sources | News front-page articles; Polymarket questions | Anchors forecast tasks in real-world events |Question cadence | ~5 per scraping session; ~8 per week from Polymarket | Ensures a steady stream of fresh evaluation material |Horizons | Mostly one-week windows; some Realization times extend | Tests ability to forecast within meaningful timeframes |Evaluation levels | Framework, Tools, Model capabilities | Diagnostics for where to improve performance |Baselines | SmolAgents as baseline; base LLMs | Shows value of agentic approaches over non-internet models |
Key takeaways
- Forecasting-focused benchmarks shift emphasis from memorization to reasoning, synthesis, and uncertainty management.
- The three-level evaluation framework helps pinpoint whether gains come from agent frameworks, information access tools, or the models themselves.
- Agent-based approaches generally outperform base language models on these tasks, with model capabilities shaping the consistency of predictions.
- Information-gathering strategies materially affect outcomes and cost; different models balance search and scraping in distinct ways.
- FutureBench offers a live leaderboard and extensible toolkit, inviting researchers to plug in new agents, tools, or data sources and compare results against a common baseline.
FAQ
-
What is FutureBench?
benchmark to evaluate AI agents on predicting future events using real-world data sources.
-
What data sources feed FutureBench?
News front-page articles via a smolagents-based scraping workflow and prediction-market questions from Polymarket.
-
How many questions are generated per session/week?
bout five questions per scraping session and around eight Polymarket questions per week.
-
How are the evaluations structured?
Through three levels: framework comparison, tool performance, and model capability assessment.
-
Where can I see live results?
The live leaderboard is available on Hugging Face Spaces as part of the FutureBench ecosystem [FutureBench](https://huggingface.co/blog/futurebench).
References
More news

Scaleway Joins Hugging Face Inference Providers for Serverless, Low-Latency Inference
Scaleway is now a supported Inference Provider on the Hugging Face Hub, enabling serverless inference directly on model pages with JS and Python SDKs. Access popular open-weight models and enjoy scalable, low-latency AI workflows.

Reducing Cold Start Latency for LLM Inference with NVIDIA Run:ai Model Streamer
A detailed look at how NVIDIA Run:ai Model Streamer lowers cold-start times for LLM inference by streaming weights into GPU memory, with benchmarks across GP3, IO2, and S3 storage.

How msg enhanced HR workforce transformation with Amazon Bedrock and msg.ProfileMap
This post explains how msg automated data harmonization for msg.ProfileMap using Amazon Bedrock to power LLM-driven data enrichment, boosting HR concept matching accuracy, reducing manual workload, and aligning with EU AI Act and GDPR.

How Quantization Aware Training Enables Low-Precision Accuracy Recovery
Explores quantization aware training (QAT) and distillation (QAD) as methods to recover accuracy in low-precision models, leveraging NVIDIA's TensorRT Model Optimizer and FP8/NVFP4/MXFP4 formats.

Accelerate Protein Structure Inference Over 100x with NVIDIA RTX PRO 6000 Blackwell Server Edition
NVIDIA’s RTX PRO 6000 Blackwell Server Edition dramatically speeds protein-structure inference, enabling end-to-end GPU-resident workflows with OpenFold and TensorRT—achieving up to 138x faster folding than AlphaFold2.

Why language models hallucinate—and how OpenAI is changing evaluations to boost reliability
OpenAI explains that hallucinations in language models stem from evaluation incentives that favor guessing over uncertainty. The article outlines how updated scoring and uncertainty-focused benchmarks can reduce confident errors and improve reliability.