
PLAID: Repurposing Protein Folding Models for Latent-Diffusion Generated Multimodal Proteins
Sources: http://bair.berkeley.edu/blog/2025/04/08/plaid, bair.berkeley.edu
TL;DR
- PLAID is a multimodal generative model that simultaneously generates protein 1D sequence and 3D structure by learning the latent space of protein folding models. PLAID article
- It supports compositional prompts for function and organism, trained on sequence databases that are 2–4 orders of magnitude larger than structure databases. PLAID article
- The method uses diffusion over a latent space of a folding model and decodes structure with frozen weights from the folding model, here using ESMFold as the decoder. PLAID article
- CHEAP (Compressed Hourglass Embedding Adaptations of Proteins) reduces embedding dimensionality to tackle large latent spaces and regularization challenges. PLAID article
- The work demonstrates how multimodal generation can be guided by functional and organism prompts and discusses potential extensions to more complex molecular contexts. PLAID article
Context and background
The PLAID project emerges in a moment of heightened attention to AI in biology, following the 2024 Nobel Prize recognition of AlphaFold2. In this context, PLAID asks what comes next after protein folding: how to move from generating proteins to generating useful proteins in a controlled, multimodal fashion. The work develops a method to sample from the latent space of protein folding models to generate new proteins, combining sequence and structure in a single unified process. PLAID article What makes PLAID notable is its emphasis on multimodal co-generation: unlike prior models that may focus on a single modality (sequence or structure), PLAID aims to produce both discrete sequence and continuous all-atom coordinates in a cohesive generation. This approach is motivated by the observation that simply generating proteins may be insufficient without mechanisms to control the outputs for practical use. PLAID article
What’s new
PLAID introduces a diffusion-based approach operating in the latent space of a protein folding model. The training process uses only sequence data to learn embeddings, with structure decoded during inference by applying frozen weights from a protein folding model. In particular, the authors use ESMFold as a modern successor to AlphaFold2, replacing a retrieval step with a protein language model. The key idea is to sample embeddings that correspond to valid proteins and then decode both sequence and full atomic structure from those embeddings. PLAID article A central challenge is that the latent spaces of transformer-based models can be very large and require substantial regularization. To address this, PLAID proposes CHEAP (Compressed Hourglass Embedding Adaptations of Proteins), a compression model for the joint embedding of protein sequence and structure. The combination of a diffusion process on a latent space and a compressed embedding space enables more tractable training and inference while preserving structural and sequence diversity. PLAID article During training, the system relies on sequences to learn embeddings; during inference, the model can decode both sequence and structure from the sampled embedding using frozen weights from the folding model. This design leverages structural understanding embedded in pretrained protein folding models as priors, analogous to how vision-language-action models use priors from large multi-modal training. PLAID article The latent space of ESMFold—and by extension many transformer-based models—exhibits some characteristic patterns when probed. The authors report that the latent space is highly compressible and exhibits notable activations across layers; this observation informs the development of CHEAP and the overall sampling strategy. PLAID article Beyond sequence-to-structure generation, PLAID is framed as a general approach for multimodal generation where a predictor from a abundant modality to a scarce one (e.g., sequence to structure) enables joint generation across modalities. As protein design advances (including complex contexts like interactions with nucleic acids and ligands), the authors suggest the method could be extended to more complex systems using the same latent-diffusion paradigm. PLAID article The authors invite collaboration to extend the method or to test it in wet-lab settings. They also provide BibTeX references for PLAID and CHEAP and point readers to preprints and codebases (PLAID and CHEAP). PLAID article
Why it matters (impact for developers/enterprises)
- Multimodal protein generation could streamline design workflows by jointly optimizing sequence and structure rather than treating them separately. This may enable more efficient exploration of functional protein variants guided by prompts. PLAID article
- Training on large sequence databases, which are 2–4 orders of magnitude larger than structure databases, hints at scalability and practicality for data-rich protein design tasks. The approach leverages latent embeddings rather than requiring structural data for every training example. PLAID article
- Using a frozen folding model during decoding allows practitioners to exploit established structural representations without retraining the entire folding stack, potentially reducing development time and computational cost. PLAID article
- The compositional control interface—functions and organism prompts—emulates intuitive user control patterns from image generation, suggesting a path toward user-friendly protein design tooling. PLAID article
- The CHEAP compression approach addresses technical challenges in high-dimensional latent spaces, which is relevant to any organization seeking scalable multimodal design tools that integrate sequence and structure. PLAID article
Technical details or Implementation
- Core concept: diffusion in the latent space of a protein folding model, enabling sampling of valid proteins whose sequence and structure can be decoded from the embedding. The decoder leverages a pretrained folding model with frozen weights, specifically ESMFold, a successor to AlphaFold2, to produce all-atom structures. PLAID article
- Training regime: only sequences are required to train the generative model, taking advantage of the abundance of sequence data relative to structural data. This enables learning a robust latent space that maps to realistic structure when decoded. PLAID article
- CHEAP (Compressed Hourglass Embedding Adaptations of Proteins): a compression model for the joint embedding of sequence and structure to manage the large latent spaces and facilitate learning. PLAID article
- Multimodal co-generation: PLAID addresses the challenge of generating both a discrete sequence and continuous structural coordinates in a single pass, enabling end-to-end generation with controllable prompts. PLAID article
- Control and prompts: PLAID supports compositional prompts for function and organism as a proof-of-concept for controlling both axes of generation; the goal is to eventually enable full-text prompt control. PLAID article
- Notable results and examples: PLAID demonstrates capabilities such as learning the tetrahedral cysteine-Fe2+/Fe3+ coordination patterns common in metalloproteins while preserving sequence-level diversity; transmembrane proteins with hydrophobic cores are also observed under function-based prompting. PLAID article
Data considerations and tables
| Data type | Characteristic | Notes |---|---|---| | Protein sequences | Abundant | Training data are 2–4 orders of magnitude larger than structure databases. |Protein structures | Scarce | Used for decoding, via frozen folding-model weights. |Latent space | Large but compressible | Demonstrated by activations across layers and the CHEAP approach. |
Key takeaways
- PLAID combines diffusion in a folding-model latent space with sequence-to-structure decoding to generate proteins multimodally. PLAID article
- Training relies on sequences; structure is produced at inference time using frozen weights from a folding model (ESMFold). PLAID article
- CHEAP offers a compression strategy to manage the joint embedding of sequence and structure, addressing high-dimensional latent spaces. PLAID article
- The approach supports function- and organism-based prompts as a proof-of-concept for controllable generation. PLAID article
- The authors see potential for extending multimodal generation to more complex systems, including interactions with nucleic acids and ligands. PLAID article
FAQ
-
What does PLAID generate?
PLAID generates both protein sequences (1D) and full all-atom 3D structures by sampling the latent space of protein folding models. [PLAID article](http://bair.berkeley.edu/blog/2025/04/08/plaid)
-
What data does PLAID require for training?
Training uses sequence databases; structure data is not required for training but is produced during inference via decoding from frozen folding-model weights. [PLAID article](http://bair.berkeley.edu/blog/2025/04/08/plaid)
-
What role does CHEAP play?
CHEAP is a compression model for the joint embedding of sequence and structure to manage large latent spaces. [PLAID article](http://bair.berkeley.edu/blog/2025/04/08/plaid)
-
How is control implemented?
The system uses compositional prompts for function and organism as a proof-of-concept for controllable generation. [PLAID article](http://bair.berkeley.edu/blog/2025/04/08/plaid)
-
What is the potential scope for future work?
The method could be extended to multimodal generation over more complex systems, including interactions with nucleic acids and ligands. [PLAID article](http://bair.berkeley.edu/blog/2025/04/08/plaid)
References
More news

Prompting for precision with Stability AI Image Services in Amazon Bedrock
Amazon Bedrock now offers Stability AI Image Services, extending Stable Diffusion and Stable Image with nine tools for precise image creation and editing. Learn prompting best practices for enterprise use.

Scale visual production using Stability AI Image Services in Amazon Bedrock
Stability AI Image Services are now available in Amazon Bedrock, delivering ready-to-use media editing via the Bedrock API and expanding on Stable Diffusion models already in Bedrock.
Mercury foundation models from Inception Labs available on Amazon Bedrock Marketplace and SageMaker JumpStart
AWS announces Mercury and Mercury Coder foundation models from Inception Labs are now accessible via Amazon Bedrock Marketplace and SageMaker JumpStart, enabling ultra-fast diffusion-based generation for AWS generative AI workloads.

Defending Against Prompt Injection with StruQ and SecAlign
Overview of StruQ and SecAlign defenses to mitigate prompt injection in LLM-powered apps, with Secure Front-End concepts and evaluation results.

Scaling Up Reinforcement Learning for Traffic Smoothing: A 100-AV Highway Deployment
Berkeley researchers deployed 100 RL-controlled vehicles on a live highway to dampen stop-and-go waves, improving traffic flow and cutting energy use for all drivers.
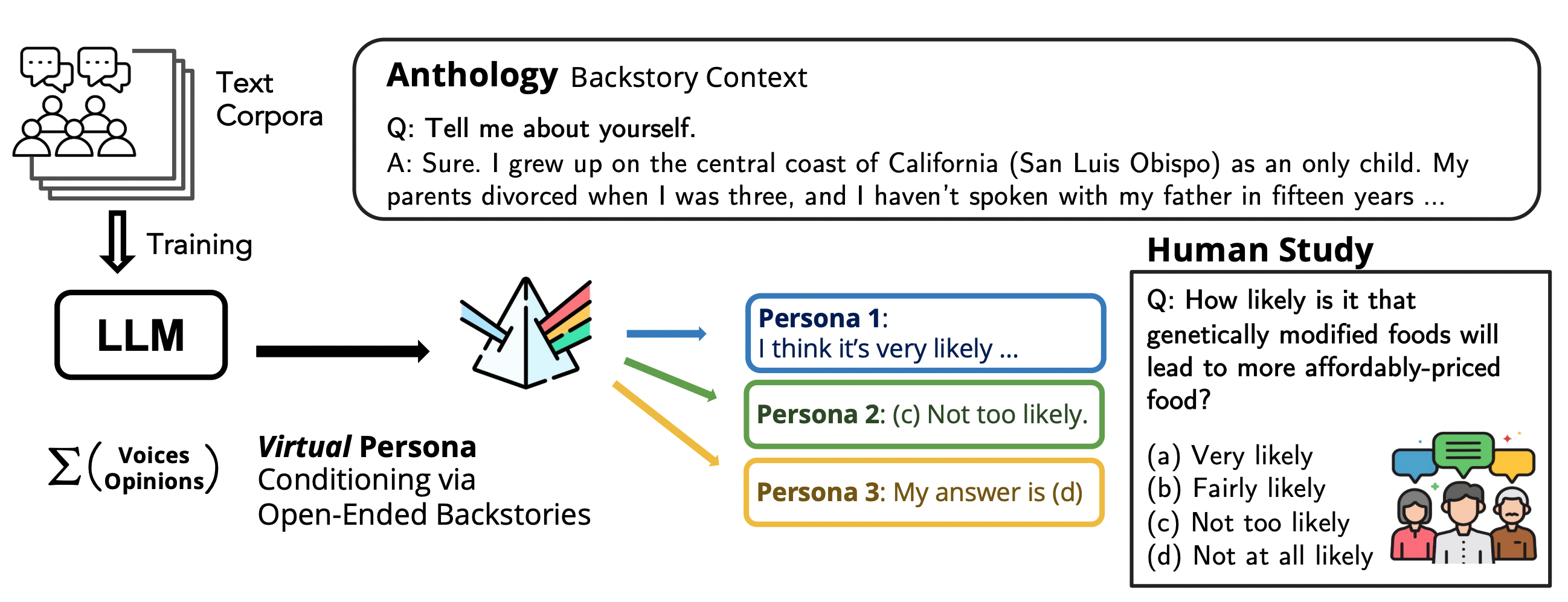
Anthology: Conditioning LLMs with Rich Backstories to Create Virtual Personas
Anthology conditions language models on richly detailed backstories to simulate representative, consistent, and diverse virtual personas for surveys and social science research.