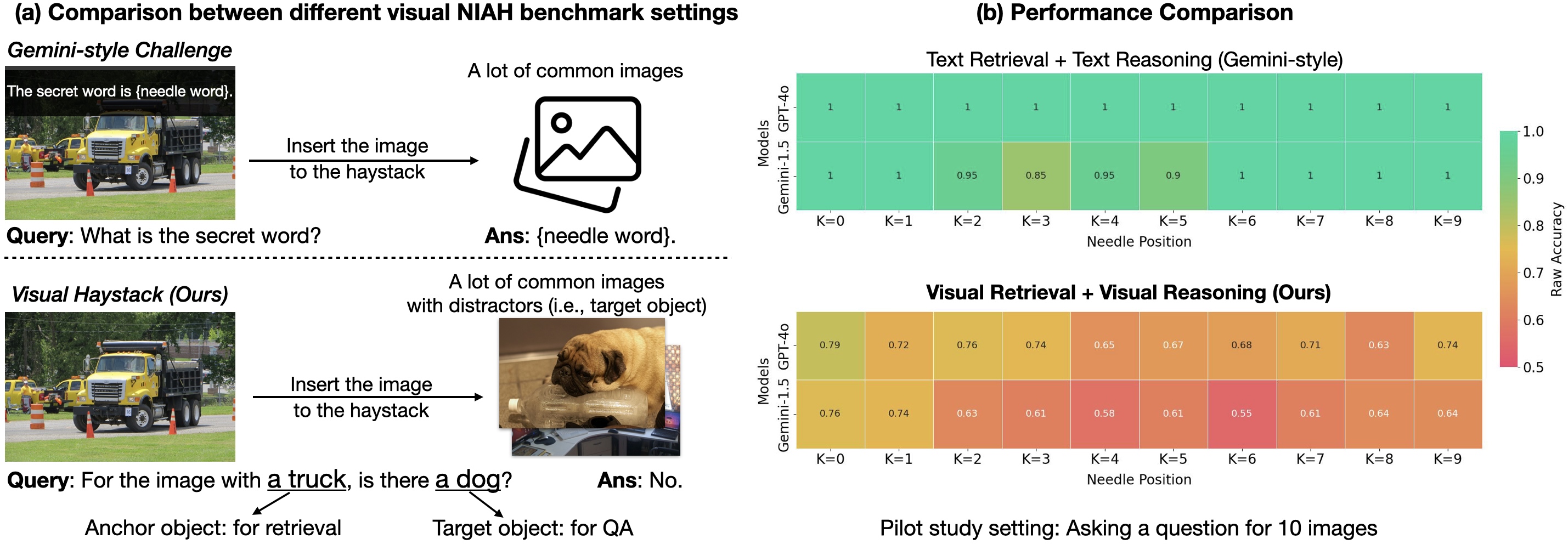
Visual Haystacks benchmark exposes limits of multi-image reasoning in LMMs
Sources: http://bair.berkeley.edu/blog/2024/07/20/visual-haystacks
TL;DR
- Visual Haystacks (VHs) is a new MIQA benchmark that evaluates Large Multimodal Models on visual retrieval and reasoning across large, uncorrelated image sets (1–10K images per set).
- The benchmark uncovers major difficulties for current LMMs with long visual Context and distractors, including limitations of open-source LMMs and API-based payload constraints for proprietary models.
- MIRAGE (Multi-Image Retrieval Augmented Generation) is an open-source, single-stage training paradigm that extends LLaVA to MIQA, handling 1K or 10K images with a 10x compression of visual encoder tokens.
- In experiments, MIRAGE achieves strong performance on most single-needle tasks and competitive results on multi-image tasks, outperforming several strong baselines and offering a retriever that exceeds CLIP in this setting.
- A notable finding is the “lost-in-the-middle” phenomenon: the needle image position can dramatically affect accuracy, highlighting the need for robust multi-image retrieval and integration. Reference: Visual Haystacks benchmark and MIRAGE framework are discussed in detail in the original Berkeley AI Research post Visual Haystacks blog.
Context and background
Traditionally, Visual Question Answering (VQA) has focused on interpreting a single image and answering questions about that image. Recent foundation models have narrowed the gap, but real-world scenarios often require reasoning over collections of images, not just one. The Visual Haystacks project introduces the Multi-Image Question Answering (MIQA) task to push beyond single-image VQA and evaluate how Large Multimodal Models handle long visual contexts and cross-image reasoning across hundreds or thousands of images. The benchmark draws on annotations from the COCO dataset and frames two core challenges to stress model capabilities: a Single-Needle setting where only one needle image exists in the haystack, and a Multi-Needle setting with two to five needle images. The Needle-In-A-Haystack (NIAH) paradigm has gained traction for testing long-context processing in models, with earlier work focusing on text or a single video frame; Visual Haystacks expands this to visual reasoning across large image collections. The work explicitly aims to prevent guessing based on prior knowledge alone, by designing questions that require actual image viewing. For more context on the benchmark’s motivation and design, see the Visual Haystacks overview in the linked post.
What’s new
Visual Haystacks introduces a two-pronged benchmark and a novel training paradigm:
- Benchmark design
- Sets contain approximately 1K binary question–answer pairs per task, with each set having 1 to 10K images.
- Two main challenges: Single-Needle (one needle image) and Multi-Needle (2–5 needles) with questions about whether all images with the anchor object contain the target object, or whether any do.
- The data and tasks are built around visual content such as objects present in images, leveraging COCO annotations.
- Experimental findings
- Across both single- and multi-needle modes, several open-source and proprietary models were evaluated, including LLaVA-v1.5, GPT-4o, Claude-3 Opus, and Gemini-v1.5-pro. A captioning baseline (caption images with LLaVA, then answer with Llama3) was also included.
- The benchmark reveals strong struggles with visual distractors as haystack size grows, even when oracle accuracy remains high. Open-source LMMs like LLaVA are limited by a 2K context length (e.g., handling only up to three images), while proprietary models encounter API payload limits when the image count grows beyond thousands.
- In VHs, all models show a significant drop in performance as haystack size increases, indicating that current LMMs are not robust to long, visually diverse inputs. In multi-image scenarios, many LMMs perform poorly relative to a captioning+LLM approach, underscoring gaps in integrating information across images.
- MIRAGE: a simple, open-source, single-stage solution
- MIRAGE stands for Multi-Image Retrieval Augmented Generation and extends LLaVA to MIQA tasks. It introduces a three-part strategy: compress existing encodings, use a retriever to filter irrelevant images, and train on multi-image data.
- It supports handling both 1K and 10K images per task and achieves state-of-the-art results on most single-needle tasks despite a relatively modest single-image QA backbone (32 tokens per image).
- MIRAGE’s retriever is co-trained with the LLM and shows strong recall and precision on multi-image tasks, outperforming strong baselines like GPT-4, Gemini-v1.5, and the Large World Model (LWM) on multi-image QA while maintaining competitive single-image QA performance.
- The retriever’s effectiveness vs CLIP
- Compared to CLIP, MIRAGE’s co-trained retriever performs significantly better without sacrificing efficiency, indicating that question-specific retrieval can outperform generic image-text matching for MIQA tasks. For a detailed description of the benchmark, model comparisons, and MIRAGE’s design, see the Visual Haystacks post and associated materials in the linked source.
Why it matters
The Visual Haystacks findings provide a clearer picture of the current bottlenecks in multi-image reasoning for LMMs. They show that simply scaling context length or relying on OCR-like retrieval from frames is insufficient for robust MIQA. The MIRAGE approach demonstrates that a single-stage, end-to-end training recipe—combining query-aware compression, an inline retriever, and multi-image training data—can markedly improve performance on large image collections while remaining open-source. For developers and enterprises, this work highlights concrete directions to build LMMs capable of processing large visual contexts, with practical implications for domains such as medical imaging collections, satellite imagery analysis, and comprehensive visual catalogs.
Technical details or Implementation
- MIRAGE overview
- MIRAGE (Multi-Image Retrieval Augmented Generation) extends LLaVA to handle MIQA tasks in a single-stage training framework.
- It uses a query-aware compression model to reduce visual encoder tokens by about 10x, enabling more images to fit within the same context length.
- A retriever, trained in-line with LLM fine-tuning, predicts whether an image will be relevant to the question and dynamically drops irrelevant images.
- The training data is augmented with multi-image reasoning data and synthetic multi-image reasoning data to support MIQA tasks.
- According to the authors, MIRAGE is open-source and capable of handling 1K or 10K images per task, providing strong recall and precision on multi-image QA tasks while maintaining competitive single-image QA performance.
- Results and comparisons
- MIRAGE achieves state-of-the-art performance on most single-needle tasks, even though the model backbone for single-image QA is relatively lightweight (only 32 tokens per image).
- On multi-image tasks, MIRAGE significantly outperforms strong competitors such as GPT-4, Gemini-v1.5, and LWM in terms of recall and precision.
- The authors compare MIRAGE’s co-trained retriever with CLIP and report that MIRAGE’s retriever performs significantly better without losing efficiency, suggesting that task-specific retrieval can outperform CLIP in MIQA contexts.
Key takeaways
- Visual distractors create substantial retrieval and integration challenges as image set size grows, even when the needle is detectable in principle.
- Many existing LMMs struggle to reason across more than a few images, particularly in multi-needle settings.
- A single-stage, open-source solution like MIRAGE can markedly improve multi-image QA performance by combining image compression, inline retrieval, and multi-image training data.
- Retrievers trained with the LLM (as opposed to relying solely on general-purpose CLIP) can yield better retrieval performance for MIQA tasks while preserving efficiency.
- The position of the needle image within the input sequence materially affects performance, a phenomenon also seen in NLP and termed here as a form of “lost-in-the-middle.”
FAQ
-
What is Visual Haystacks (VHs)?
It is a new Needle‑In‑A‑Haystack benchmark designed to evaluate Large Multimodal Models on visual retrieval and reasoning across large, uncorrelated image sets (about 1K QA pairs per task with 1–10K images per set) using COCO-based annotations.
-
What is MIRAGE?
MIRAGE stands for Multi-Image Retrieval Augmented Generation; it is an open-source, single-stage training paradigm that extends LLaVA to MIQA tasks, enabling 1K or 10K images per task by compressing visual tokens, using an inline retriever, and training with multi-image data.
-
How does MIRAGE compare to other models?
On multi-image tasks, MIRAGE shows strong recall and precision, outperforming GPT-4, Gemini-v1.5, and LWM, while retaining competitive single-image QA performance. Its retriever also outperforms CLIP for this use case.
-
What limitations were observed in the study?
The study found substantial performance drops as the haystack size increases and observed sensitivity to the needle’s position within the input sequence; open-source LMMs have context-length limits (e.g., LLaVA up to 2K) and proprietary models face payload-size constraints with large image sets.
-
How can researchers access these resources?
The benchmark and MIRAGE approach are presented as open-source, with the Visual Haystacks post detailing the framework and experiments.
References
- Visual Haystacks: A New Benchmark Exposing Limits of Multi‑Image Reasoning in LMMs — http://bair.berkeley.edu/blog/2024/07/20/visual-haystacks/
More news

First look at the Google Home app powered by Gemini
The Verge reports Google is updating the Google Home app to bring Gemini features, including an Ask Home search bar, a redesigned UI, and Gemini-driven controls for the home.

Shadow Leak shows how ChatGPT agents can exfiltrate Gmail data via prompt injection
Security researchers demonstrated a prompt-injection attack called Shadow Leak that leveraged ChatGPT’s Deep Research to covertly extract data from a Gmail inbox. OpenAI patched the flaw; the case highlights risks of agentic AI.

Predict Extreme Weather in Minutes Without a Supercomputer: Huge Ensembles (HENS)
NVIDIA and Berkeley Lab unveil Huge Ensembles (HENS), an open-source AI tool that forecasts low-likelihood, high-impact weather events using 27,000 years of data, with ready-to-run options.

Scaleway Joins Hugging Face Inference Providers for Serverless, Low-Latency Inference
Scaleway is now a supported Inference Provider on the Hugging Face Hub, enabling serverless inference directly on model pages with JS and Python SDKs. Access popular open-weight models and enjoy scalable, low-latency AI workflows.

Google expands Gemini in Chrome with cross-platform rollout and no membership fee
Gemini AI in Chrome gains access to tabs, history, and Google properties, rolling out to Mac and Windows in the US without a fee, and enabling task automation and Workspace integrations.

Kaggle Grandmasters Playbook: 7 Battle-Tested Techniques for Tabular Data Modeling
A detailed look at seven battle-tested techniques used by Kaggle Grandmasters to solve large tabular datasets fast with GPU acceleration, from diversified baselines to advanced ensembling and pseudo-labeling.